







 本文介绍了一种利用单个雷达扫描和相机图像来估计深度的方法,针对毫米波雷达点云的稀疏性、噪声和不确定性,提出了RadarNet和FusionNet网络。RadarNet学习雷达点与图像表面的一对多映射,而FusionNet通过门控融合机制融合雷达和相机信息,生成密集深度图。在NuScenes基准上,该方法显著提高了深度估计的准确性。
本文介绍了一种利用单个雷达扫描和相机图像来估计深度的方法,针对毫米波雷达点云的稀疏性、噪声和不确定性,提出了RadarNet和FusionNet网络。RadarNet学习雷达点与图像表面的一对多映射,而FusionNet通过门控融合机制融合雷达和相机信息,生成密集深度图。在NuScenes基准上,该方法显著提高了深度估计的准确性。
CVPR 2023 | Depth Estimation from Camera Image and mmWave Radar Point Cloud
多模态感知论文阅读笔记:CVPR 2023, Depth Estimation from Camera Image and mmWave Radar Point Cloud

Abstract
-
背景
-
提出一种从摄像机图像和稀疏雷达点云推断密集深度图的方法
-
Challenge:毫米波雷达点云形成的挑战,如模糊性和噪声 ⇒ \Rightarrow ⇒ 无法正确映射到camera images上
✅ existing works: overlook the above challenge
-
-
Proposed approach
- 设计一个网络将每个雷达点映射到图像平面上可能投影的表面
- 与现有工作不同,我们不直接处理原始雷达点云,而是查询每个原始点与图像中可能的像素进行关联——产生半密集的雷达深度图
- 提出带门控融合方案,考虑对应分数的置信度,选择性地结合雷达和相机嵌入来产生密集深度图
-
Experiments
- 在NuScenes基准测试中测试方法,平均绝对误差提高10.3%,均方根误差提高9.1%
- code: https://github.com/nesl/radar-camera-fusion-depth
1 Introduction
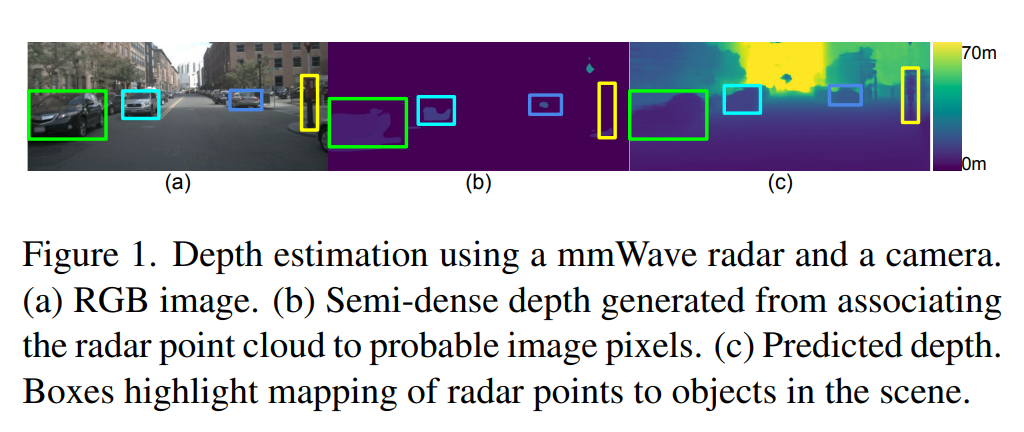
P1: 基于雷达 + 相机 的 深度估计
- 理解3D场景结构可以支持空间任务如导航和操作
- 相机图像提供每个像素的强度,但由于遮挡或光圈问题难以恢复3D结构
- 测距传感器通常很稀疏,但提供场景中的一些点的3D坐标(即点云)
- 目标:利用相机图像和雷达点云的互补性恢复密集3D场景(即相机雷达深度估计)
- mmWave radar: 比激光雷达廉价、轻量、功耗低
P2: 挑战
- 毫米波雷达:highly sparse, noisy, and ambiguous AOA
- ⇒ \Rightarrow ⇒ 存在很大误差,无法直接映射到camera images上
- 已有方法:直接处理原始雷达点云,忽略上述挑战
P3: Proposed method
- 提出从单个雷达和图像帧估算深度
- 1 首先学习每个雷达点与图像中可能属于的表面之间的 一对多映射来 学习对应关系
- 2 每个雷达点通过ROI对齐机制与图像中的区域对应——产生 半密集的雷达深度图
- 3 雷达深度图中的信息由门控融合机制调制, 学习对应关系中的错误模式并自适应地加权其对图像雷达融合的贡献
- 4 其结果用于增强图像信息,并解码为密集深度图
P4: Contributions
- 首个 使用单个雷达扫描和单个相机图像来学习雷达到相机的对应关系的方法
- 以将任意数量的模糊和嘈杂的雷达点映射到图像中的物体表面
- 引入映射的置信分数
- 用于融合雷达和图像模态
- 提出门控融合机制
- 在雷达深度和图像信息之间自适应调节权衡
- 优秀的实验性能
- 尽管只使用单个图像和雷达帧 ⇒ \Rightarrow ⇒
- 超过使用多个图像和雷达帧的最佳方法10.3%的平均绝对误差(MAE)和9.1%的均方根误差(RMSE),以达到NuScenes基准测试的最新技术
2 Related Work
2.1 Camera-lidar depth estimation
- 利用RGB图像作为指导来密集化稀疏的激光雷达点云
- 大多工作致力于解决稀疏性问题,如
- 设计网络块
- 估计激光雷达采样位置
- 使用金字塔网路
- 使用独立的图像和深度网络
- 提出上采样层
- 使用置信度图
- 使用表面法向
- 激光雷达昂贵、能耗高,在实际应用中受限
2.2 Single image depth
- 在没有强大先验条件的情况下难以大规模应用
- 毫米波雷达便宜且常见,将预测与公制尺度结合
2.3 Camera-radar depth estimation
- 使用稀疏的毫米波雷达点云和相机图像
- 与基于相机和激光雷达的深度估计不同,具有新的挑战
- 因为雷达点云的稀疏性和噪声
- 已有工作
- [30]学习从雷达数据到图像像素的映射,使用多个图像和扫描得到更密集的点
- [26]提出两阶段编码器解码器架构减少噪声,也使用未来帧
- [28]创建高度扩展的雷达表示,与相机图像融合生成密集深度
- [13]将稀疏点云作为训练期间的弱监督信号融合,推理时用作额外输入增强稳健性
- 这些工作要么 忽略雷达点的噪声和错误 ,要么 使用多个图像和扫描得到更密集的点
- 与它们不同,本文只需要 单张图像和雷达扫描产生密集深度
3 mmWave PCD Geneartion
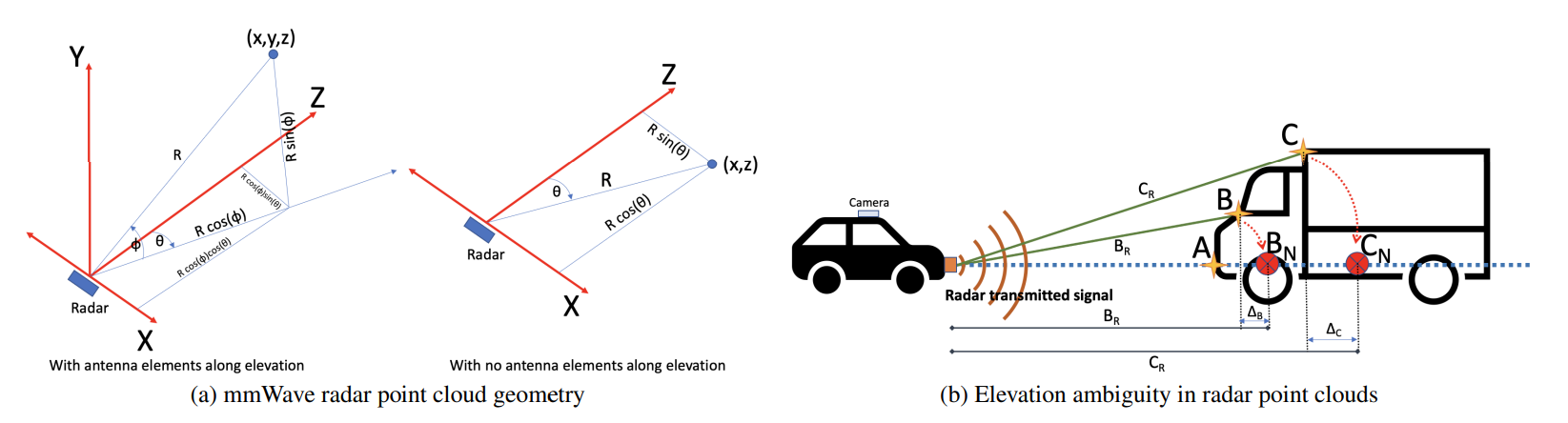
- 镜面反射
- 导致稀疏性
- 天线阵列
- 导致角度,特别是俯仰角度分辨能力差
- 已有工作
- [13,26,28,29]没有考虑到上述问题,将不正确的投影视为原貌,或执行后处理操作如沿y轴扩展每个点
- 本文
- 学习将雷达点映射到场景中的可能表面,以恢复更密集的雷达点云
4 Proposed Approach
4.1 Overview & Formulation
- 目标
- 从单张RGB图像 和 点云 恢复 3D场景
- 分为两个子问题
-
(i) 在嘈杂的雷达点云中找到每个点与其在图像平面上的可能投影之间的对应关系,以产生半密集的雷达深度图;
🚩 RadarNet :将RGB图像和雷达点作为输入,输出置信度图,表示点映射到图像中的可能表面。对K个点,输出K个置信度图,构造半密集的雷达深度图
✅ ROIAlign进行高效推理
-
(ii) 融合半密集的雷达图和相机图像以输出密集深度图
🚩 FusionNet :融合图像,雷达深度图和每个对应关系的置信度,输出密集深度图
✅ 门控融合:学习一组权重调节传递到解码器的深度信息量,学习雷达深度图和置信度分数的错误模式
-
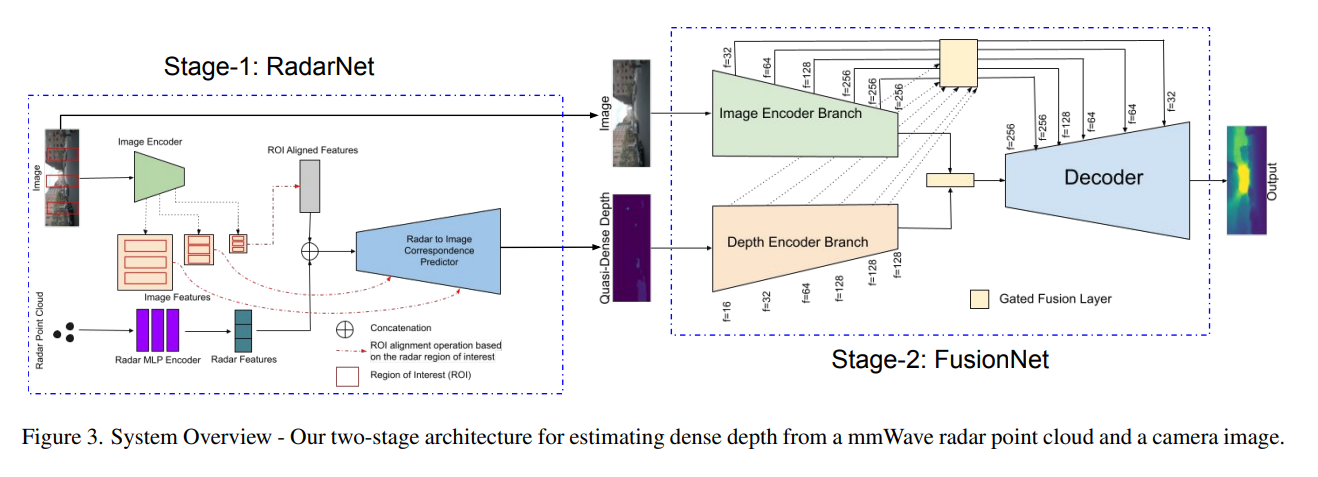
4.2 RadarNet
- 数据集:RGB图像,雷达点云,真实的激光雷达深度图
- 两个编码器:标准ResNet18编码图像;5层全连接MLP编码雷达点
- 将点云的潜在表示与图像潜在表示融合,解码为响应图(置信度分数)
- 作为二分类问题: 高响应表示给定点的可能表面
- ROI对应给定点的真实位置,构造标签,最小化二分类交叉熵损失
- 训练RadarNet将雷达点映射到图像空间中的区域,支持不同时刻的雷达返回,产生比雷达点云密集的半密集深度图
ℓ B C E =
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











