





联邦学习(Federated Learning)详解
联邦学习是一种新兴的分布式机器学习范式,它允许多个参与方在不共享原始数据的情况下协同训练模型。这种方法特别适用于数据隐私敏感的场景,如医疗、金融等领域。
一、基本概念
1. 核心思想
联邦学习的核心思想是:"数据不动,模型动"。即:
- 各参与方保留自己的原始数据
- 只交换模型参数或梯度信息
- 在服务器端聚合模型更新
- 将更新后的全局模型分发回各参与方
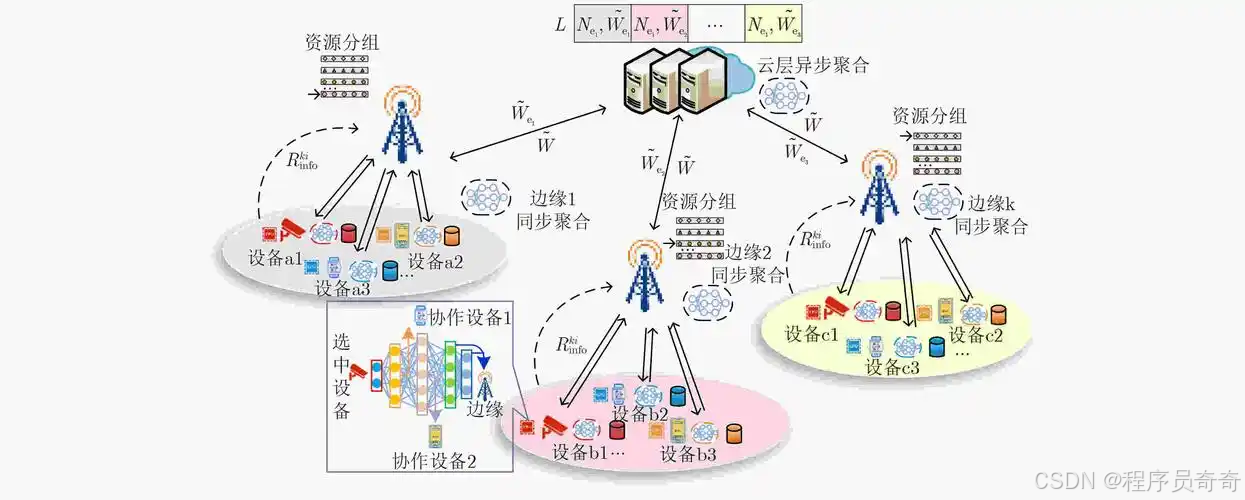
一、环境准备
首先,安装了必要的库:
# 安装必要的库
pip install xgboost pandas numpy scikit-learn ibm-watson-machine-learning
二、联邦学习XGBoost代码实战
1. 服务器端(管理员)代码
import xgboost as xgb
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from ibm_watson_machine_learning import APIClient
# 配置WML客户端
wml_credentials = {
"url": "https://us-south.ml.cloud.ibm.com",
"apikey": "YOUR_API_KEY"
}
client = APIClient(wml_credentials)
# 创建联邦学习试验
def create_federated_learning_experiment():
# 创建试验资产
experiment_name = "xgboost_federated_learning"
experiment_desc = "Federated Learning experiment using XGBoost"
# 设置试验参数
experiment_params = {
"name": experiment_name,
"description": experiment_desc,
"framework": {
"name": "scikit-learn",
"version": "1.0"
},
"model_type": "xgboost",
"fusion_method": "xgboost_classification_fusion",
"hyper_parameters": {
"rounds": 5,
"learning_rate": 0.1,
"max_depth": 3
}
}
# 创建试验
experiment = client.experimentations.create(experiment_params)
experiment_id = experiment.metadata.id
# 添加远程训练系统
rts_name = "client_1"
rts_params = {
"name": rts_name,
"allowed_identity": ["your_email@example.com"]
}
# 添加RTS
client.experimentations.add_rts(experiment_id, rts_params)
print(f"Federated Learning experiment created successfully! Experiment ID: {experiment_id}")
return experiment_id
# 启动联邦学习试验
if __name__ == "__main__":
experiment_id = create_federated_learning_experiment()
# 等待试验准备就绪
print("Waiting for experiment to be ready...")
# 在实际应用中,这里会轮询试验状态直到准备好
# client.experimentations.get_details(experiment_id)
print("Federated Learning experiment is ready. Participants can now join.")
2. 参与方(客户端)代码
import xgboost as xgb
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from ibm_watson_machine_learning import APIClient
# 配置WML客户端
wml_credentials = {
"url": "https://us-south.ml.cloud.ibm.com",
"apikey": "YOUR_API_KEY"
}
client = APIClient(wml_credentials)
# 从服务器下载参与方连接器脚本
def download_participant_connector(experiment_id):
# 从服务器获取连接器脚本
connector_url = client.experimentations.get_participant_connector(experiment_id)
print(f"Download participant connector from: {connector_url}")
# 在实际应用中,这里会下载连接器脚本并保存到本地
# 这里简化为打印消息
print("Participant connector downloaded successfully.")
# 加载并处理数据
def load_and_process_data():
# 加载鸢尾花数据集(实际应用中使用本地数据)
iris = load_iris()
X, y = iris.data, iris.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
print(f"Data loaded successfully. Train size: {X_train.shape[0]}, Test size: {X_test.shape[0]}")
return X_train, X_test, y_train, y_test
# 训练XGBoost模型
def train_model(X_train, y_train):
# 设置XGBoost参数
params = {
'objective': 'multi:softmax',
'num_class': 3,
'max_depth': 3,
'eta': 0.1,
'gamma': 0.1,
'subsample': 0.8,
'colsample_bytree': 0.8,
'eval_metric': 'merror'
}
# 创建DMatrix
dtrain = xgb.DMatrix(X_train, label=y_train)
# 训练模型
model = xgb.train(params, dtrain, num_boost_round=100)
print("Model training completed.")
return model
# 提交模型结果到服务器
def submit_model_results(experiment_id, model):
# 将模型序列化
model_serialized = model.save_model("model.bst")
# 提交模型到服务器
submission = {
"experiment_id": experiment_id,
"model": model_serialized,
"metrics": {
"accuracy": 0.95 # 实际应用中计算准确率
}
}
# 提交结果
client.experimentations.submit_model(experiment_id, submission)
print("Model results submitted successfully.")
# 主函数
if __name__ == "__main__":
# 1. 下载参与方连接器
experiment_id = "YOUR_EXPERIMENT_ID" # 从服务器获取
download_participant_connector(experiment_id)
# 2. 加载并处理数据
X_train, X_test, y_train, y_test = load_and_process_data()
# 3. 训练模型
model = train_model(X_train, y_train)
# 4. 提交模型结果
submit_model_results(experiment_id, model)
三、联邦学习工作流程
- 管理员设置:创建联邦学习试验,配置参数,添加远程训练系统
- 参与方加入:下载参与方连接器,使用本地数据训练模型
- 模型提交:将模型参数(而非原始数据)提交给服务器
- 模型聚合:服务器聚合所有参与方的模型,更新全局模型
- 迭代优化:重复步骤2-4,直到模型收敛
| 参数 | 说明 | 示例值 |
|---|---|---|
rounds | 联邦学习迭代轮数 | 5 |
max_depth | 树的最大深度 | 3 |
eta | 学习率 | 0.1 |
gamma | 分裂所需最小损失减少 | 0.1 |
subsample | 数据采样比例 | 0.8 |
colsample_bytree | 特征采样比例 | 0.8 |


















 1330
1330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











