



(这篇帖子主要是自己留个备份。想听我随便聊只看前面就行。想复制代码就直接拉到后面。)
两年前,我微调过当时开源的一些大语言模型。用阿毗达磨数据。因为,大语言模型在阿毗达磨问题上的表现总是很差。后来,每出一种更强劲的模型,我总会从写作和阿毗达磨两个方面去测试它。在文学写作上,最先达到我认为勉强可用的模型是Claude 3.5 Sonnet(2024年10月版),我是从去年11月开始用sonnet写作的。deepseek R1出现之后,基本替换成R1。
R1在阿毗达磨上的表现比现在一般人能用的模型都要相对好一点。注意,只是相对。我现在一般会用三个比较简单的问题问它们:1、阿毗达磨里的98随眠具体是哪些?2、色界见灭所断随眠有哪些?3、色界见灭所断随眠中有哪些是无漏缘惑?——包括o1和o3-mini在内的模型,都还从来没回答对第二个问题过。R1在表现最好的时候,第二个问题回答对了(大部分时候回答不对)。
这主要不是模型能力差,因为模型能做对很多数学竞赛和编程题,那些比阿毗达磨题目难太多了(更何况上面列举的只是非常基础的阿毗达磨题目)。主要原因是什么呢?是网上的阿毗达磨数据质量太差了,99%的数据都是错的。说99%毫不夸张。这也是我想尝试微调开源模型的原因。
我完全不懂编程。连一行代码都看不明白。能够跑通,首先得益于刘琨的指导和帮助,其次得益于有诸多AI可用。也可以说主要是刘琨跑通的,我主要负责写这个帖子。
所以,我把微调的代码放出来,以便自己以后还想微调有个备份(两年前微调的那些流程我清理电脑已经找不到了)。
1、用jsonl还是txt?
我的选择是毫不犹豫地用txt。
不过一开始,还是试了jsonl数据。方法是,先分卷把《俱舍论》塞给Claude,让它从每一卷中提取出40个问题,列成jsonl格式。效果如下(举三例):
{“instruction”: “”, “input”: “什么是"色蘊”?", “output”: “色蘊包含五根(眼、耳、鼻、舌、身根)、五境(色、声、香、味、触)以及无表色。”}
{“instruction”: “”, “input”: “文中提到的"五根"具体指什么?”, “output”: “五根指眼根、耳根、鼻根、舌根、身根,这五种净色是识的所依。”}
{“instruction”: “”, “input”: “文中提到的"界"是什么意思?”, “output”: “界的含义是法的种族义,如同一座山中有多种金银铜铁等族群,一身或一相续中有十八类诸法种族,故名十八界。”}
复制这些内容成jsonl,还会碰到一些问题,一个是要把空行删除,再一个是内容中的引号会让程序出错,以及可能还会有一些其他问题。
但这些都不是最关键的问题。最关键的问题是,jsonl类型的阿毗达磨数据质量高不了。高质量的数据只能手动去写,但我不可能有那个精力。AI根据《俱舍》《婆沙》生成的1万条jsonl数据,假设其中包含20万字,它的价值只相当于俱舍论的4000字,这就是为什么用jsonl数据训练很不可行。
所以,我简单试了下jsonl数据,还是回归到txt数据。
2、1小时可运行的代码
我是在google colab上微调的。一开始是用10MB的数据,包含《俱舍》《婆沙》《正理》三部阿毗达磨文献全文。还有个更大的,整个毗昙部的文献,48MB左右,想先跑通一遍流程,没用那个。用的是T4 GPU,最早的代码,显示微调完成需要36小时。我想先跑通流程,所以修改参数到最小,又换成一个4MB的数据(只包含《俱舍》《正理》),训练需要1小时左右。因此,现在放上来的也是这个。
以下的代码解释,每一部分放在一个单元格中,解释是让Claude完成的。
%%capture
# Normally using pip install unsloth is enough
# Temporarily as of Jan 31st 2025, Colab has some issues with Pytorch
# Using pip install unsloth will take 3 minutes, whilst the below takes <1 minute:
!pip install --no-deps bitsandbytes accelerate xformers==0.0.29 peft trl triton
!pip install --no-deps cut_cross_entropy unsloth_zoo
!pip install sentencepiece protobuf datasets huggingface_hub hf_transfer
!pip install --no-deps unsloth
好的,我来详细解释这段安装依赖的代码。让我们一步步来看:
\1. 首先看到 %%capture
- 这是一个Jupyter/Colab的魔法命令
- 它的作用是隐藏命令执行时的输出信息,让notebook看起来更整洁
- 如果不加这个,安装过程中会出现大量的日志信息
\2. 关于依赖安装的总体说明
- 通常情况下,只需要运行 pip install unsloth 就够了
- 但在2025年1月底,由于Colab环境的特殊性,需要分步安装以提高效率
- 这种方式可以把安装时间从3分钟缩短到1分钟以内
\3. 让我们看看安装了哪些核心库:
```python
!pip install --no-deps bitsandbytes accelerate xformers==0.0.29 peft trl triton
```
- --no-deps: 表示只安装指定的包,不安装它们的依赖包
- bitsandbytes: 用于模型量化,可以减少显存占用
- accelerate: Hugging Face的加速训练工具
- xformers: Facebook开发的Transformer优化库
- peft: Parameter-Efficient Fine-Tuning的缩写,用于高效微调
- trl: Transformer Reinforcement Learning,用于强化学习训练
- triton: 一个编程语言,用于编写高效的GPU代码
\4. 安装特定功能的包:
```python
!pip install --no-deps cut_cross_entropy unsloth_zoo
```
- cut_cross_entropy: 优化的交叉熵损失函数实现
- unsloth_zoo: unsloth的模型库
\5. 安装Hugging Face相关的工具:
```python
!pip install sentencepiece protobuf datasets huggingface_hub hf_transfer
```
- sentencepiece: 用于文本分词
- datasets: Hugging Face的数据集工具
- huggingface_hub: 用于与Hugging Face模型库交互
- hf_transfer: 优化的模型下载工具
\6. 最后安装unsloth主包:
```python
!pip install --no-deps unsloth
```
这些库构成了一个完整的大语言模型微调环境。使用unsloth可以帮助我们更高效地进行模型微调,它提供了很多优化和加速的特性。
小提示:如果安装过程中遇到错误,可以去掉%%capture来查看具体的错误信息,这样更容易排查问题。

好的,我来详细解释这段代码的作用。这是加载预训练模型的关键步骤,让我们逐行分析:
\1. 首先是导入必要的库:
```python
from unsloth import FastLanguageModel
import torch
```
- FastLanguageModel 是unsloth提供的快速语言模型加载工具
- torch 是PyTorch深度学习框架,为模型训练提供基础支持
\2. 加载预训练模型:
```python
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = “unsloth/DeepSeek-R1-Distill-Llama-8B-unsloth-bnb-4bit”,
max_seq_length = 512,
dtype = None,
load_in_4bit = True,
)
```
这行代码的各个参数含义如下:
- model_name: 指定要加载的模型
- 这里使用的是DeepSeek-R1-Distill-Llama-8B模型
- 这是一个8B参数的Llama架构模型
- "unsloth"前缀表明这是经过unsloth优化的版本
- "bnb-4bit"表示使用了4位量化
- max_seq_length = 512:
- 设置模型能处理的最大文本长度
- 512是一个比较保守的设置,可以节省显存
- 根据实际需求,这个值可以调整
- dtype = None:
- 数据类型设置为None,表示使用模型默认的数据类型
- 在4位量化的情况下,这个参数实际上不会起作用
- load_in_4bit = True:
- 启用4位量化加载模型
- 这可以大大减少显存占用
- 相比16位或32位精度,显存占用可以减少4-8倍
- 虽然精度降低,但对大多数任务的影响很小
这段代码执行后会返回两个重要对象:
- model: 加载好的语言模型,用于后续的训练和推理
- tokenizer: 分词器,用于将文本转换为模型可以理解的数字序列
小贴士:
\1. 如果显存不足,可以考虑:
- 进一步减小max_seq_length
- 使用参数更少的模型版本
\2. 第一次运行时会从网络下载模型,可能需要一些时间
\3. 建议确保有足够的显存(建议至少10GB以上)才运行这段代码

让我详细解释这段配置PEFT(Parameter-Efficient Fine-Tuning)模型的代码。这是使用LoRA方法进行高效微调的重要设置:
\1. FastLanguageModel.get_peft_model()的作用:
- 将普通的语言模型转换为可以进行高效参数微调的版本
- 使用LoRA(Low-Rank Adaptation)技术来减少训练参数量
- 保持模型主体不变,只训练少量新增参数
\2. 重要参数解析:
- r = 8: LoRA的秩设置
- 这个值决定了LoRA矩阵的大小
- 值越小,训练参数越少,显存占用越低
- 但如果太小可能会影响模型效果
- 8是一个比较平衡的选择
- target_modules = ["q_proj", "k_proj", "v_proj"]:
- 指定要应用LoRA的具体层
- 这里只选择了注意力机制中最核心的三个投影矩阵:
- q_proj: Query投影
- k_proj: Key投影
- v_proj: Value投影
- 这样可以在保持效果的同时最大限度减少训练参数
- lora_alpha = 8:
- LoRA的缩放因子
- 控制LoRA层的影响程度
- 通常设置为与r相同的值
- lora_dropout = 0:
- LoRA层的dropout率
- 设为0表示不使用dropout
- 这可以加快训练速度
- bias = "none":
- 设置是否训练偏置项
- "none"表示不训练偏置
- 这样可以进一步减少训练参数
- use_gradient_checkpointing = "unsloth":
- 使用unsloth优化的梯度检查点
- 可以显著减少显存使用
- 虽然会稍微降低训练速度,但对于大模型来说很有必要
- random_state = 3407:
- 设置随机种子
- 确保实验可以复现
- 3407是机器学习中常用的一个幸运数字
实用建议:
\1. 如果显存still很紧张,可以:
- 进一步减小r的值(比如改为4)
- 减少target_modules的数量
\2. 如果训练效果不理想,可以:
- 适当增加r的值
- 增加target_modules(比如加入"o_proj")
\3. 这些参数设置体现了"够用就好"的原则,在效果和资源消耗之间找到平衡
通过这样的设置,我们可以用很小的计算资源实现模型微调,这对于个人开发者来说特别友好。
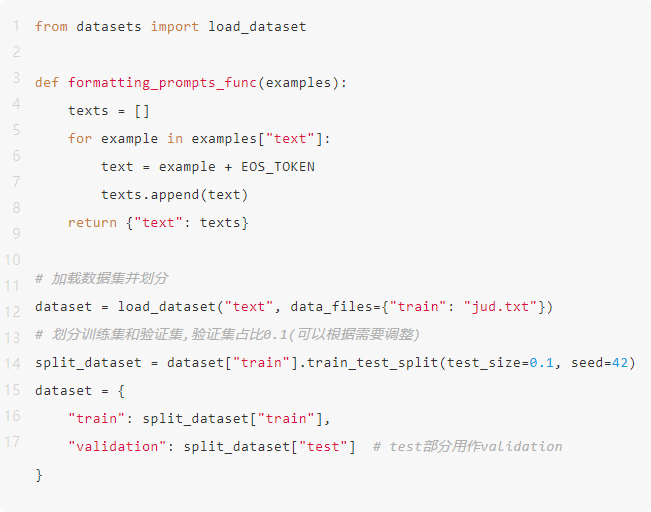
我来详细解释这段数据处理的代码。这是准备训练数据的关键步骤:
\1. 首先导入数据集工具:
```python
from datasets import load_dataset
```
- datasets是Hugging Face提供的数据集处理库
- 它让数据集的加载和处理变得简单高效
\2. 定义数据格式化函数:
```python
def formatting_prompts_func(examples):
texts = []
for example in examples[“text”]:
text = example + EOS_TOKEN
texts.append(text)
return {“text”: texts}
```
这个函数的作用是:
- 接收一批文本样本
- 在每个文本末尾添加结束符(EOS_TOKEN)
- 将处理后的文本重新打包返回
- 这样可以让模型知道每个样本在哪里结束
\3. 加载本地数据集:
```python
dataset = load_dataset(“text”, data_files={“train”: “jud.txt”})
```
- 使用load_dataset加载本地文本文件
- data_files参数指定文件路径
- "jud.txt"是您的训练文本文件
- 这里假设文件采用简单的文本格式
\4. 划分数据集:
```python
split_dataset = dataset[“train”].train_test_split(
test_size=0.1,
seed=42
)
```
- 将数据集分为训练集和验证集
- test_size=0.1表示验证集占总数据的10%
- seed=42是随机种子,确保划分可重现
- 这个比例可以根据实际需求调整
\5. 重组数据集字典:
```python
dataset = {
“train”: split_dataset[“train”],
“validation”: split_dataset[“test”]
}
```
- 创建标准格式的数据集字典
- 包含"train"和"validation"两个部分
- 验证集用于评估模型训练效果
实用建议:
\1. 关于数据文件(jud.txt):
- 确保文件编码正确(推荐UTF-8)
- 最好提前清理好数据格式
- 建议每行一个样本
\2. 关于划分比例:
- 如果数据量很大,验证集可以设得更小(如5%)
- 如果数据量小,可以适当增加比例
- 确保验证集足够代表数据分布
\3. 数据质量检查:
- 建议在训练前打印几个样本检查格式
- 确认EOS_TOKEN正确添加
- 检查是否有异常的空行或格式问题
这段代码为后续的模型训练做好了数据准备工作。好的数据预处理对训练效果至关重要。
from transformers import AutoTokenizer
# tokenizer部分保持不变
tokenizer = AutoTokenizer.from_pretrained("unsloth/DeepSeek-R1-Distill-Llama-8B-unsloth-bnb-4bit")
# 加载txt数据集
dataset = load_dataset(
"text",
data_files={"train": "jud.txt"},
split="train"
)
# 划分数据集
split_dataset = dataset.train_test_split(test_size=0.1, seed=42)
train_dataset = split_dataset["train"]
val_dataset = split_dataset["test"]
# 查看数据结构
print("数据集列名:", train_dataset.column_names)
print("\n第一条数据样例:", train_dataset[0])
def format_text(examples):
"""处理纯文本数据"""
formatted_texts = []
for text in examples["text"]:
# 为每个文本片段添加EOS token
formatted_text = text + tokenizer.eos_token
formatted_texts.append(formatted_text)
return {"text": formatted_texts}
# 应用数据处理
train_dataset = train_dataset.map(
format_text,
batched=True,
remove_columns=train_dataset.column_names
)
val_dataset = val_dataset.map(
format_text,
batched=True,
remove_columns=val_dataset.column_names
)
# 验证输出
print("\n处理后的训练集样例:")
print(train_dataset[0]["text"][:200], "...") # 只打印前200个字符
print("\n处理后的验证集样例:")
print(val_dataset[0]["text"][:200], "...")
让我详细解释这段数据处理和分词的代码。这是对前面代码的优化和扩展版本:
\1. 导入分词器并初始化:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(“unsloth/DeepSeek-R1-Distill-Llama-8B-unsloth-bnb-4bit”)
```
- 使用和模型相同的分词器配置
- 确保数据处理与模型期望的输入格式一致
\2. 加载数据集:
```python
dataset = load_dataset(
“text”,
data_files={“train”: “jud.txt”},
split=“train”
)
```
- 直接指定训练数据文件
- 先作为单个数据集加载
\3. 数据集划分:
```python
split_dataset = dataset.train_test_split(test_size=0.1, seed=42)
train_dataset = split_dataset[“train”]
val_dataset = split_dataset[“test”]
```
- 90%作为训练集
- 10%作为验证集
- 使用固定随机种子确保可重现性
\4. 检查数据结构:
```python
print(“数据集列名:”, train_dataset.column_names)
print(“\n第一条数据样例:”, train_dataset[0])
```
- 打印数据集的基本信息
- 有助于理解数据格式和内容
\5. 定义文本处理函数:
```python
def format_text(examples):
“”“处理纯文本数据”“”
formatted_texts = []
for text in examples[“text”]:
formatted_text = text + tokenizer.eos_token
formatted_texts.append(formatted_text)
return {“text”: formatted_texts}
```
- 为每条文本添加结束符
- 使用tokenizer的标准结束符
- 批量处理以提高效率
\6. 应用数据处理:
```python
train_dataset = train_dataset.map(
format_text,
batched=True,
remove_columns=train_dataset.column_names
)
val_dataset = val_dataset.map(
format_text,
batched=True,
remove_columns=val_dataset.column_names
)
```
特别注意的参数:
- batched=True: 启用批处理以提高效率
- remove_columns: 移除原有列,保持数据结构清晰
\7. 验证处理结果:
```python
print(“\n处理后的训练集样例:”)
print(train_dataset[0][“text”][:200], “…”)
print(“\n处理后的验证集样例:”)
print(val_dataset[0][“text”][:200], “…”)
```
- 打印处理后的样本
- 只显示前200个字符避免输出过长
- 方便检查处理是否符合预期
实用建议:
\1. 数据检查:
- 仔细检查打印出的样例
- 确保文本格式正确
- 验证结束符是否正确添加
\2. 内存管理:
- 如果数据集很大,可以考虑使用流式处理
- 可以添加cache_file_name参数来缓存处理结果
\3. 错误处理:
- 建议添加try-except来捕获可能的错误
- 特别是处理大量数据时
\4. 性能优化:
- batched=True对大数据集很重要
- 可以通过num_proc参数启用多进程处理
这段代码提供了更完整的数据处理流程,并加入了必要的验证步骤,这对确保训练数据质量非常重要。

让我详细解释这段配置训练器的代码。这是整个训练过程中最关键的配置部分:
\1. 首先是导入必要的组件:
```python
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
```
- SFTTrainer: 用于监督微调(Supervised Fine-Tuning)的训练器
- TrainingArguments: 训练参数配置类
- is_bfloat16_supported: 检查是否支持bfloat16格式
\2. 创建SFTTrainer对象:
```python
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = train_dataset,
eval_dataset = val_dataset,
dataset_text_field = “text”,
max_seq_length = 512,
dataset_num_proc = 1,
packing = True,
args = TrainingArguments(…)
)
```
主要参数解析:
- model: 之前配置好的LoRA模型
- tokenizer: 分词器
- train_dataset和eval_dataset: 训练集和验证集
- dataset_text_field: 指定数据集中的文本字段名
- max_seq_length = 512: 限制序列长度,节省显存
- dataset_num_proc = 1: 数据处理的进程数
- packing = True: 启用序列打包,提高训练效率
\3. TrainingArguments详细配置:
基础训练参数:
```python
per_device_train_batch_size = 4, # 每个设备的批次大小
gradient_accumulation_steps = 2, # 梯度累积步数
warmup_steps = 5, # 预热步数
num_train_epochs = 1, # 训练轮数
```
优化器相关:
```python
learning_rate = 3e-4, # 学习率
optim = “adamw_8bit”, # 使用8位AdamW优化器
weight_decay = 0.01, # 权重衰减率
lr_scheduler_type = “linear”, # 学习率调度策略
```
精度设置:
```python
fp16 = not is_bfloat16_supported(), # 如果不支持bf16就用fp16
bf16 = is_bfloat16_supported(), # 优先使用bf16
```
其他设置:
```python
logging_steps = 1, # 每步都记录日志
seed = 3407, # 随机种子
output_dir = “outputs”, # 输出目录
report_to = “none”, # 不使用外部记录工具
```
实用建议:
\1. 关于批次大小:
- 如果显存充足,可以适当增加per_device_train_batch_size
- 如果显存不足,可以增加gradient_accumulation_steps
- 实际批次大小 = per_device_train_batch_size × gradient_accumulation_steps
\2. 关于学习率:
- 3e-4是比较激进的设置
- 如果训练不稳定,可以降低到1e-4或5e-5
- warmup_steps可以帮助稳定训练初期
\3. 关于训练轮数:
- 单轮训练可能不够
- 可以根据验证集表现适当增加
- 注意观察是否过拟合
\4. 关于显存优化:
- 使用8位优化器节省显存
- 根据硬件选择合适的精度(fp16/bf16)
- 可以通过减小max_seq_length进一步节省显存
这些配置体现了在有限资源下的优化策略,既要保证训练效果,又要确保训练能够顺利进行。

让我详细解释这段执行训练和评估的代码:
\1. 执行训练:
```python
trainer_stats = trainer.train()
```
- 这行代码启动实际的训练过程
- 会返回包含训练统计信息的对象
- 训练过程中会看到进度条和实时指标
\2. 打印训练统计信息:
```python
print(“\n训练统计:”)
print(f"总训练时间: {trainer_stats.metrics[‘train_runtime’]:.2f} 秒")
print(f"训练损失: {trainer_stats.metrics[‘train_loss’]:.4f}")
```
重要指标说明:
- train_runtime: 整个训练过程耗时
- train_loss: 训练集上的平均损失值
- 损失值越低表示模型拟合得越好
- 但要注意不能太低,可能出现过拟合
\3. 验证损失检查:
```python
if ‘eval_loss’ in trainer_stats.metrics:
print(f"验证损失: {trainer_stats.metrics[‘eval_loss’]:.4f}")
```
- 检查训练过程中是否计算了验证损失
- 这部分是可选的,取决于训练配置
\4. 最终模型评估:
```python
final_metrics = trainer.evaluate()
print(“\n最终验证集评估结果:”)
print(f"验证损失: {final_metrics[‘eval_loss’]:.4f}")
```
- 在完整验证集上评估模型表现
- 获得最终的验证指标
- 这个分数最具参考价值
实用建议:
\1. 关于训练监控:
- 记录初始损失值作为基准
- 观察损失下降趋势是否健康
- 警惕损失突然增大或不稳定的情况
\2. 训练时间分析:
- 如果训练时间过长,可以考虑:
- 减少数据量
- 减少训练轮数
- 增加批次大小
- 如果训练时间过短,可能需要:
- 增加训练轮数
- 增加数据量
\3. 损失值分析:
- 训练损失和验证损失的差距不应太大
- 如果验证损失明显高于训练损失,说明过拟合
- 理想情况下两者应该同步下降
\4. 常见问题处理:
- 如果损失不下降:
- 检查学习率是否合适
- 检查数据预处理是否正确
- 如果训练不稳定:
- 降低学习率
- 增加warmup步数
- 如果显存溢出:
- 减小批次大小
- 减少序列长度
这段代码是整个训练过程的收尾,通过这些指标可以判断训练是否成功,模型效果如何。建议保存这些指标,方便与其他训练配置进行比较。

让我详细解释这段用于模型推理的代码:
\1. 定义提示模板:
```python
alpaca_prompt = “”"
指令:{0}
输入:{1}
输出:{2}
“”"
```
- 使用Alpaca格式的提示模板
- 包含三个部分:指令、输入和输出
- 使用format()方法可以方便地填充内容
\2. 开启快速推理模式:
```python
FastLanguageModel.for_inference(model)
```
- 启用unsloth的原生快速推理
- 可以获得2倍的推理速度提升
- 这是优化后的推理模式
\3. 准备输入数据:
```python
inputs = tokenizer(
[
alpaca_prompt.format(
“”, # instruction
“三界是什么?”, # input
“”, # output - leave this blank for generation!
)
], return_tensors = “pt”).to(“cuda”)
```
- 使用模板格式化输入
- 将文本转换为模型需要的张量格式
- 将数据移到GPU上进行处理
\4. 设置文本流式输出:
```python
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
```
- 导入并初始化文本流式输出器
- 可以实时看到生成的文本
- 比等待全部生成完再显示更友好
\5. 生成文本:
```python
_ = model.generate(
**inputs,
streamer = text_streamer,
max_new_tokens = 512
)
```
主要参数说明:
- **inputs: 展开准备好的输入数据
- streamer: 使用流式输出器
- max_new_tokens: 限制生成的最大token数
实用建议:
\1. 关于提示工程:
- 提示模板可以根据需要修改
- 可以尝试不同的指令来获得更好的输出
- 注意保持提示格式的一致性
\2. 输出控制:
- 可以调整max_new_tokens控制输出长度
- 可以添加temperature参数控制随机性
- 可以设置top_p或top_k参数控制采样策略
\3. 性能优化:
- 使用batch处理可以提高效率
- 可以尝试不同的推理设置
- 注意显存使用情况
\4. 错误处理:
- 建议添加try-except捕获可能的错误
- 特别是处理长文本时
- 注意处理特殊字符和换行符
这段代码展示了如何使用微调后的模型进行实际的文本生成。通过调整各种参数,可以获得不同风格和质量的输出。建议多做实验,找到最适合您需求的设置。
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 2156
2156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









