



人工智能领域,斯坦福CS336课程(全称:CS 336 - Foundations of Large Language Models and Their Applications)被许多学习者视为“大模型学习的必修课”,不仅因为课程本身由一流学者讲授,更因为它以从零构建大语言模型为主线,让学习者真正看清楚大模型的底层运作机制。
然而,想要完全靠自学啃下这门课程,并不容易:
- 难度高:课程作业要求从零实现完整的模型组件,对基础和细节的掌握缺一不可;
- 资料分散:公开的讲义和参考代码碎片化严重,缺乏连贯的学习路径;
- 算力需求大:很多人被运行环境和训练成本卡住。
也正因如此,不少学习者虽然知道CS336的价值,但很难坚持学完。为了解决这些痛点,和鲸社区启动CS336课程作业复现计划:
- 把课程作业完整地实现并公开,降低学习门槛;
- 让学习者可以直接在社区中运行、修改、交流;
- 配备视频讲解,更加直观易懂。
今天,我们先来看由和鲸社区优秀创作者@天海一直在AI 复现的大作业一:从分词到完整Transformer的实现与实验。
创作者主页:https://www.heywhale.com/u/9f9a05
👆作业复现项目见“和鲸社区”(下文附网址)
🎬 视频讲解见:b站“天海一直在AI”
作业一复现项目概览
在大作业一中,学习者需要完成从“文本输入”到“模型训练与生成”的完整链路。和鲸社区的复现涵盖了五大模块,每一步都能运行、可验证、可扩展:
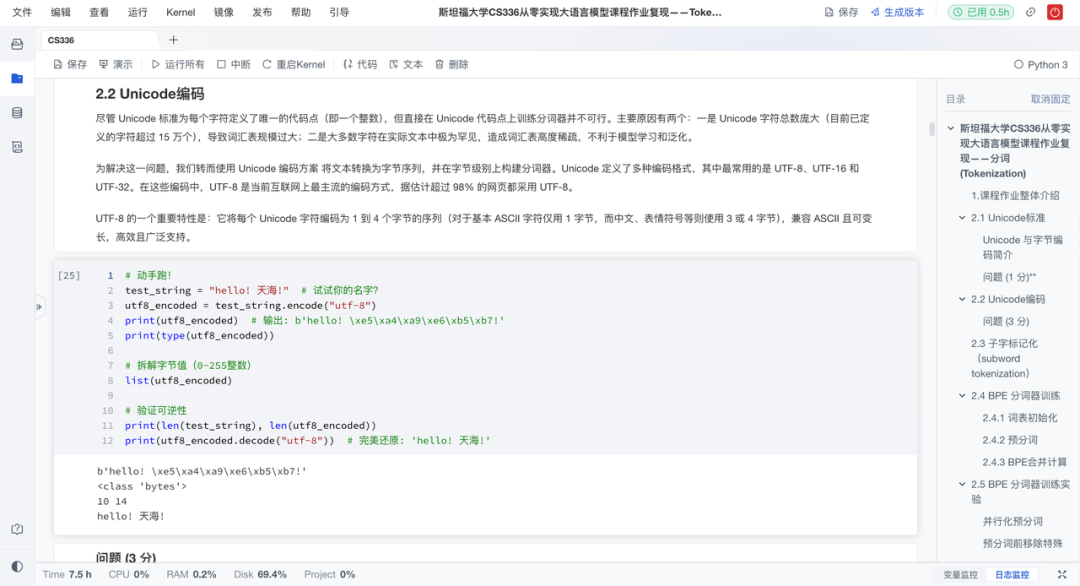
语言模型的第一步,是把自然语言切分成模型可处理的“Token”。作业复现项目从零实现字节级BPE分词器,并阐述了其相比字符级和词级分词的优势。具体来说有以下亮点:
- BPE算法实现:重点实现当前主流的字节级BPE算法,理解其如何从256个基础字节构建出上万规模的词汇表;
- 跨语言支持:基于UTF-8字节单元构建,天然兼容多语言与表情符号,规避OOV问题;
- **跨数据集验证:**在TinyStories和OpenWebText上训练与测试BPE分词器,分析其泛化能力与压缩效率;
- 可逆编解:支持编码与解码全流程,便于调试与下游任务集成。
该项目不仅夯实数据预处理基础,更通过实验揭示“分词方式如何影响模型上限”,是理解语言模型起点的关键一环。
💻分词作业复现项目地址:
- 网页:https://www.heywhale.com/u/a63533(复制至浏览器打开)
- 小程序:CS336作业1复现——Tokenization
👈左滑查看更多
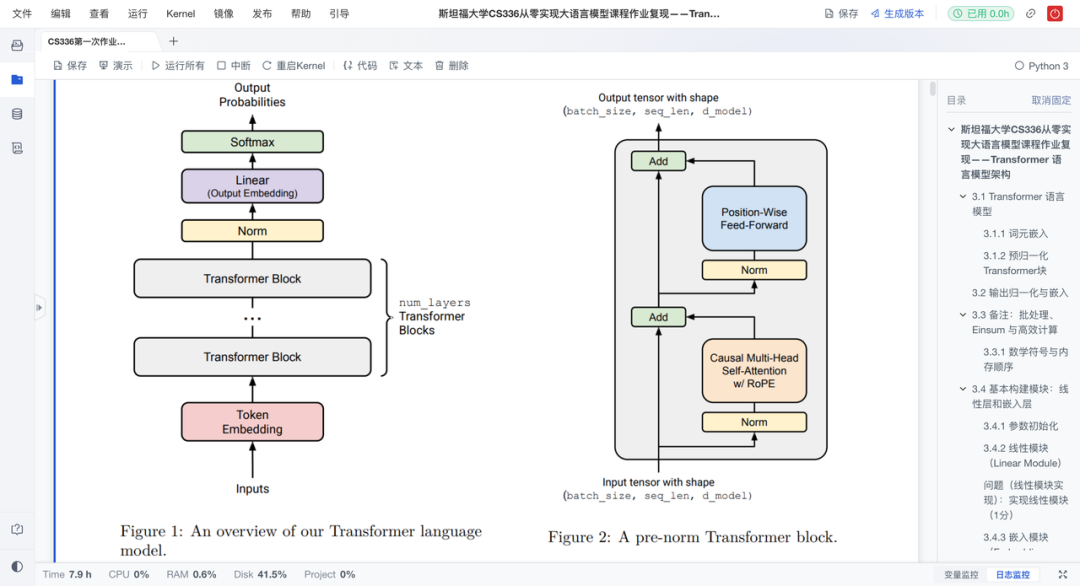
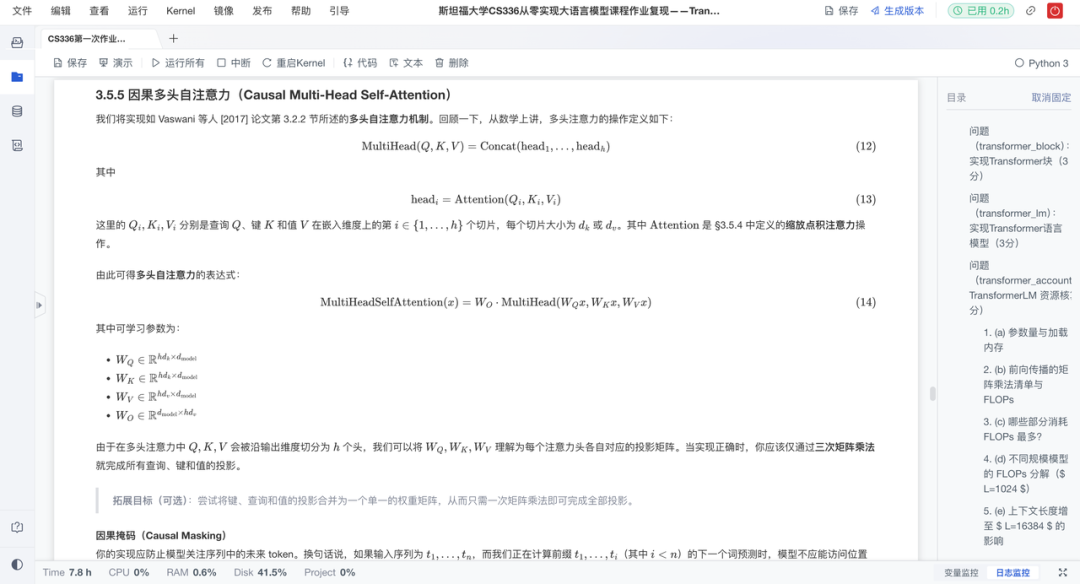
这是作业的重头戏。复现项目从零搭建了Transformer的核心模块,实现“手动拼装”大模型核心引擎。具体来说有以下亮点:
- 自注意力:从头实现因果多头自注意力机制,包括QKV计算、掩码处理与输出投影;
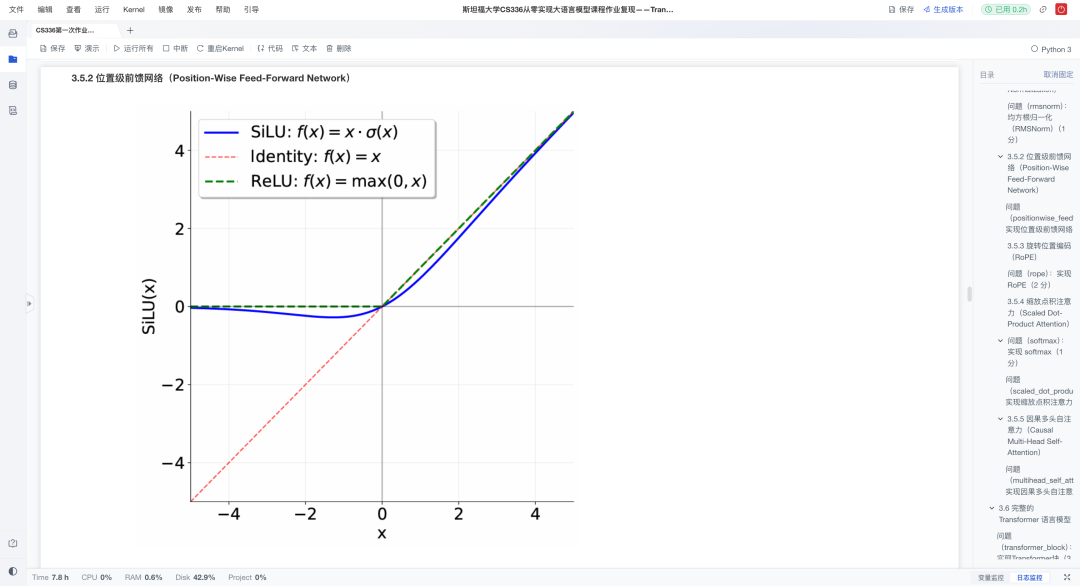
- 位置编码:实现可学习的位置嵌入层,为模型注入序列顺序信息;
- 前馈结构:实现RMSNorm+SwiGLU前馈网络,增强表达力与稳定性;
- 模块测试:采用模块化设计,每层可独立验证,降低学习门槛。
通过亲手实现每一层,学习者得以穿透框架黑箱,深入理解Transformer的运作机制。
💻Transformer作业复现项目地址:
- 网页:https://www.heywhale.com/u/10f21e(复制至浏览器打开)
- 小程序:CS336作业1复现——Transformer
👈左滑查看更多
这是承上启下的关键环节。项目构建完整的训练基础设施,涵盖损失函数、优化器与训练循环,打造可运行的端到端训练系统。具体来说有以下亮点:
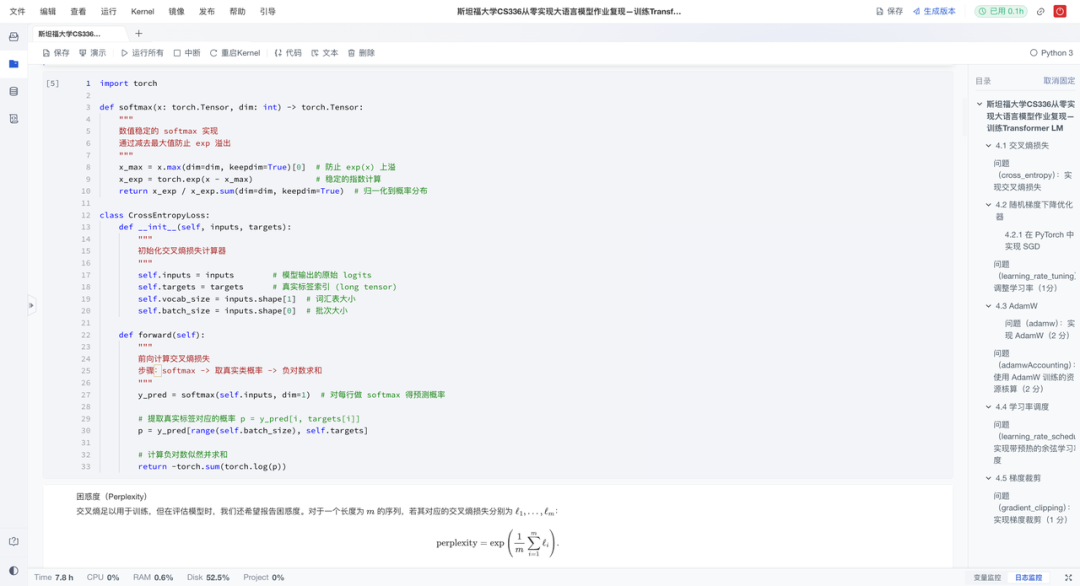
- 损失实现:手动编写数值稳定的交叉熵损失,处理softmax溢出问题;
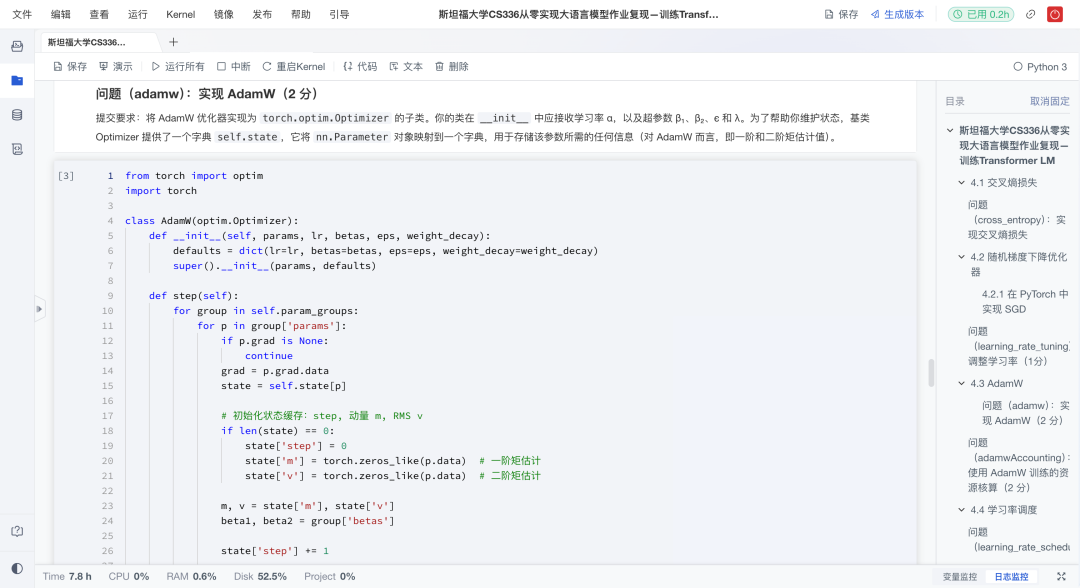
- 优化器:从头实现AdamW,包含动量、自适应学习率与权重衰减;
- 梯度控制:引入梯度裁剪,防止深层网络训练崩溃;
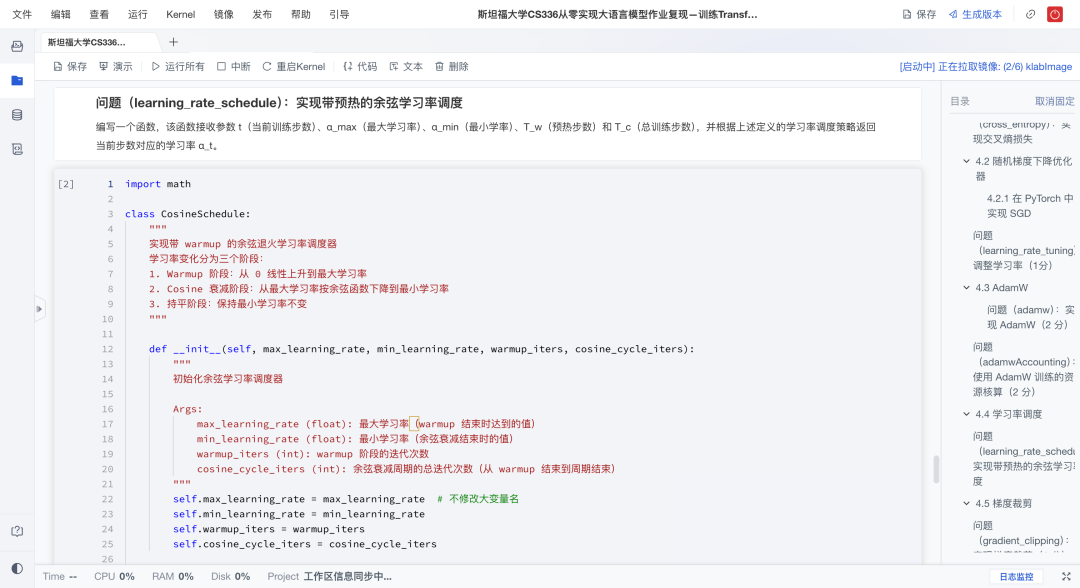
- 学习率:采用warmup + 余弦衰减策略,提升收敛效率与稳定性;
- 训练监控:建立实验日志系统,记录并追踪loss随训练步数和时间的变化,用于分析模型收敛情况。
这一部分可以让学习者体会到“代码能学会语言”,并通过可视化验证训练是否成功,为后续的生成与实验打下基础。
💻Transformer LM作业复现项目地址:
- 网页:https://www.heywhale.com/u/ae8d62(复制至浏览器打开)
- 小程序:CS336作业1复现——Transformer LM
👈左滑查看更多
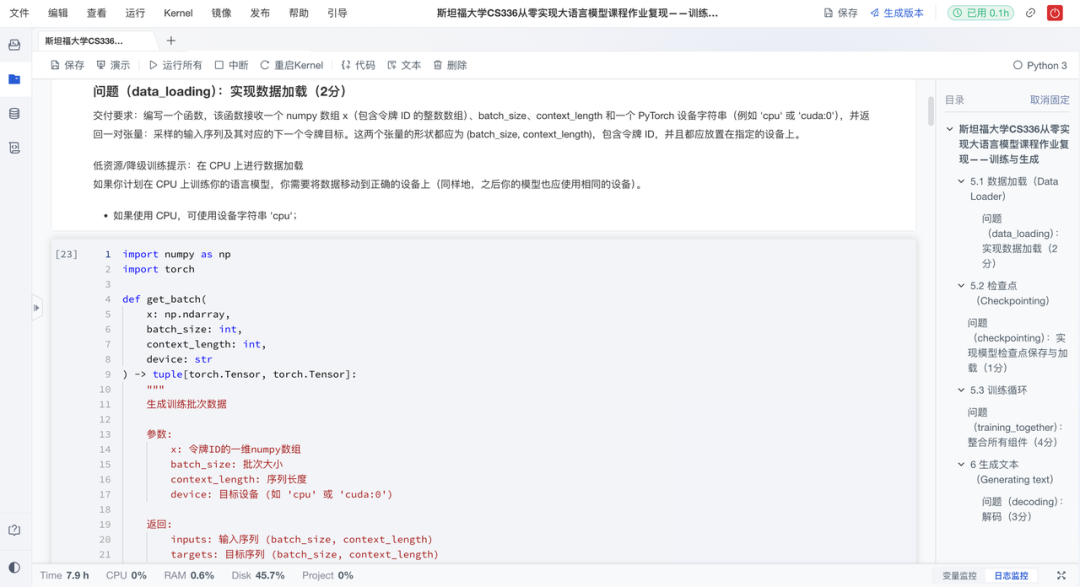
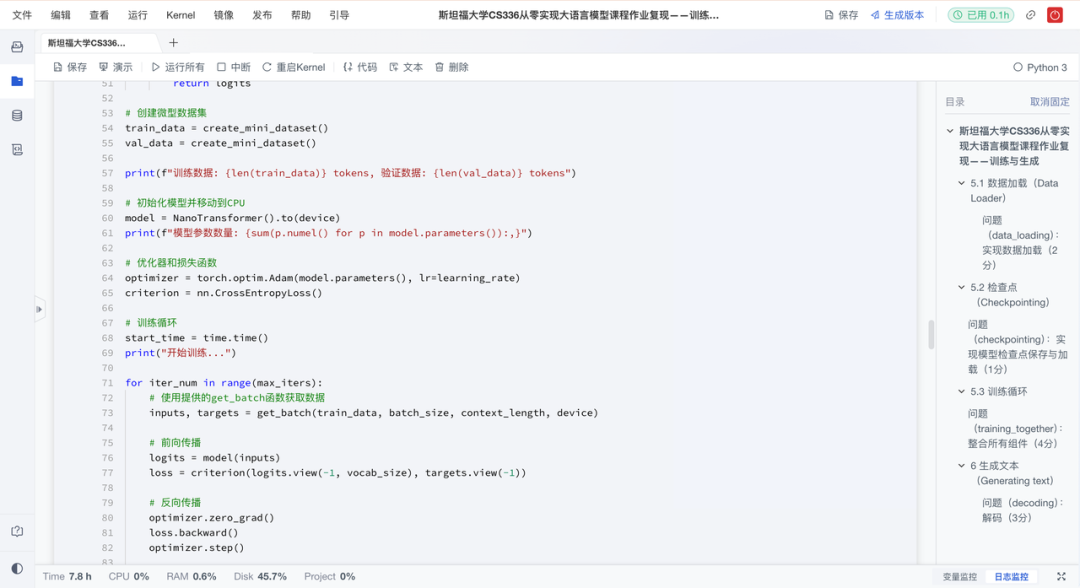
在有了模型架构后,复现项目实现了可运行的训练循环,并让模型真正“开口说话”。具体来说有以下亮点:
- 端到端:整合数据加载、训练循环与检查点保存,支持断点续训;
- 文本生成:实现基于采样的自回归生成,输入提示即可续写文本;
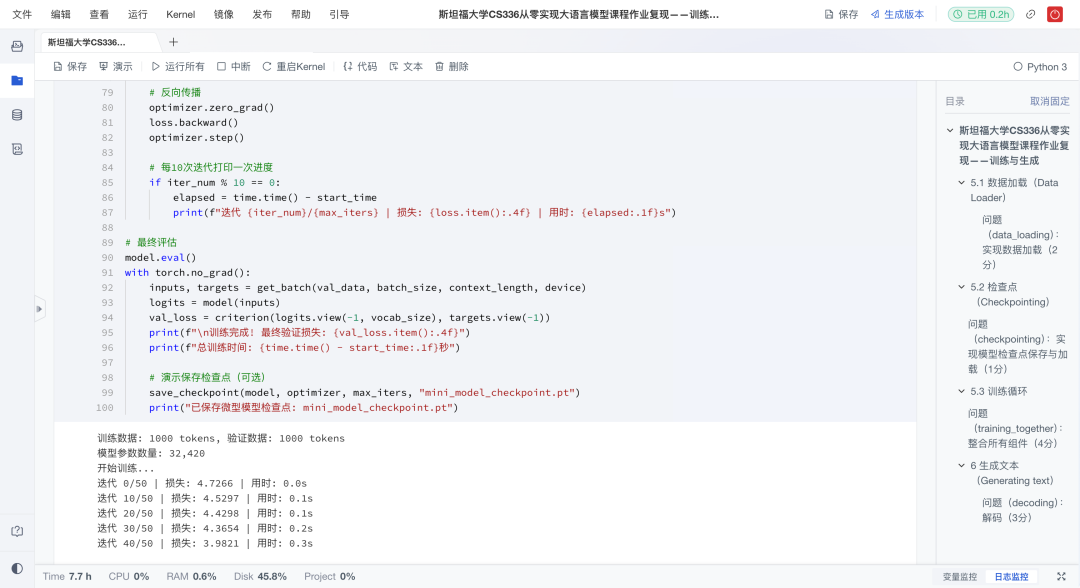
- 效果演进:对比不同训练阶段的生成结果,形成“loss↓→ 文本↑”的直观反馈。
更重要的是,这套训练与生成代码可以在社区环境直接运行,即便算力有限,也能快速看到模型收敛的过程。
💻Training&Generation作业复现项目地址:
- 网页:https://www.heywhale.com/u/e73b28(复制至浏览器打开)
- 小程序:CS336作业1复现——训练与生成
👈左滑查看更多
在完成模型构建与训练后,复现进一步展开了系统实验,探索不同超参数设置对模型性能的影响。具体来说有以下亮点:
- 超参探索:系统性地进行实验,对比不同学习率和batch size对模型训练稳定性、收敛速度和最终性能的影响;
- 定量评估:使用困惑度(Perplexity)等指标客观衡量模型质量;
- 分词实验:跨数据集测试BPE行为,分析长token成因与泛化能力;
- 记录复盘:保留参数、曲线与结果,支持迭代优化与对比分析。
这一部分不仅教会“怎么做”,更强调“怎么验证”,为后续独立研究与工程调优打下坚实基础。
💻Experiments作业复现项目地址:
- 网页:https://www.heywhale.com/u/f1ef9f(复制至浏览器打开)
- 小程序:CS336作业1复现——Experiments
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 1975
1975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









