



- 统一潜在空间:提出了一种因果编码器,将图像和视频映射到统一的潜在空间中,从而实现跨模态的训练和生成。这一设计不仅简化了模型架构,还显著减少了生成高分辨率视频的计算负担。
- 窗口注意力架构:设计了一种专门为联合空间和时空生成建模的窗口注意力架构。该架构通过在非重叠的窗口内进行自注意力计算,显著降低了计算需求,并提高了内存效率。
- Transformer骨干:首次成功实证展示了Transformer骨干在联合训练图像和视频潜在扩散模型中的应用。与传统的U-Net架构相比,Transformer在生成质量和参数效率方面表现更优。
- 级联模型架构:提出了一种由三个模型组成的级联架构,用于文本到视频生成任务。该架构包括一个基础潜在视频扩散模型和两个视频超分辨率扩散模型,能够生成高分辨率、时间一致的照片级视频。
摘要
我们提出了W.A.L.T,一种基于Transformer的方法,通过扩散建模实现照片级视频生成。我们的方法有两个关键设计决策。首先,我们使用因果编码器在统一的潜在空间中联合压缩图像和视频,从而实现跨模态的训练和生成。其次,为了内存和训练效率,我们使用了一种专门为联合空间和时空生成建模设计的窗口注意力架构。这些设计决策使我们能够在不使用无分类器指导的情况下,在已建立的视频(UCF-101和Kinetics-600)和图像(ImageNet)生成基准上实现最先进的性能。最后,我们还训练了一个由三个模型组成的级联,用于文本到视频生成任务,包括一个基础潜在视频扩散模型和两个视频超分辨率扩散模型,以生成512×896分辨率、每秒8帧的视频。

Part1背景
Transformer [73] 是一种高度可扩展和可并行的神经网络架构,旨在赢得“硬件彩票”[39]。这一理想特性鼓励研究社区在语言 [55, 56, 57, 26]、音频 [1]、语音 [58]、视觉 [18, 30] 和机器人 [7, 5, 89] 等多个领域中越来越多地倾向于使用Transformer而不是特定领域的架构。这种统一化的趋势使得研究人员能够在传统上不同的领域之间共享和构建进展,从而形成一个有利于Transformer模型设计的良性循环,推动创新和改进。
在视频生成建模领域,这一趋势的一个显著例外是生成建模。扩散模型 [67, 69] 已成为图像 [16, 33] 和视频生成 [36] 的主要范式。然而,U-Net架构 [63, 62],由一系列卷积 [46] 和自注意力 [73] 层组成,已成为所有视频扩散方法 [16, 33, 36] 的主要骨干。这种偏好源于Transformer中的全注意力机制的内存需求随输入序列长度呈二次方增长,导致处理高维信号(如视频)时成本过高。
潜在扩散模型(LDMs)[61] 通过在从自编码器 [20, 72, 75] 导出的低维潜在空间中操作来减少计算需求。在这种情况下,关键的设计选择是所使用的潜在空间的类型:空间压缩(每帧潜在)与时空压缩。空间压缩通常更受欢迎,因为它可以利用预训练的图像自编码器和LDMs,这些模型在大规模配对图像-文本数据集上进行训练。然而,这种选择增加了网络复杂性,并限制了Transformer作为骨干的使用,特别是在生成高分辨率视频时由于内存限制。另一方面,虽然时空压缩可以缓解这些问题,但它排除了使用配对图像-文本数据集的可能性,这些数据集比视频数据集更大且更多样化。
我们提出了窗口注意力潜在Transformer(W.A.L.T):一种基于Transformer的方法,用于潜在视频扩散模型(LVDMs)。我们的方法包括两个阶段。首先,自编码器将视频和图像映射到一个统一的、低维的潜在空间。这一设计选择使得可以联合在图像和视频数据集上训练单个生成模型,并显著减少生成高分辨率视频的计算负担。随后,我们提出了一种新的Transformer块设计,用于潜在视频扩散建模,该设计由自注意力层组成,这些层在非重叠的窗口内交替进行空间和时空注意力。这种设计提供了两个主要好处:首先,使用局部窗口注意力显著降低了计算需求。其次,它促进了联合训练,其中空间层独立处理图像和视频帧,而时空层则专门用于建模视频中的时间关系。
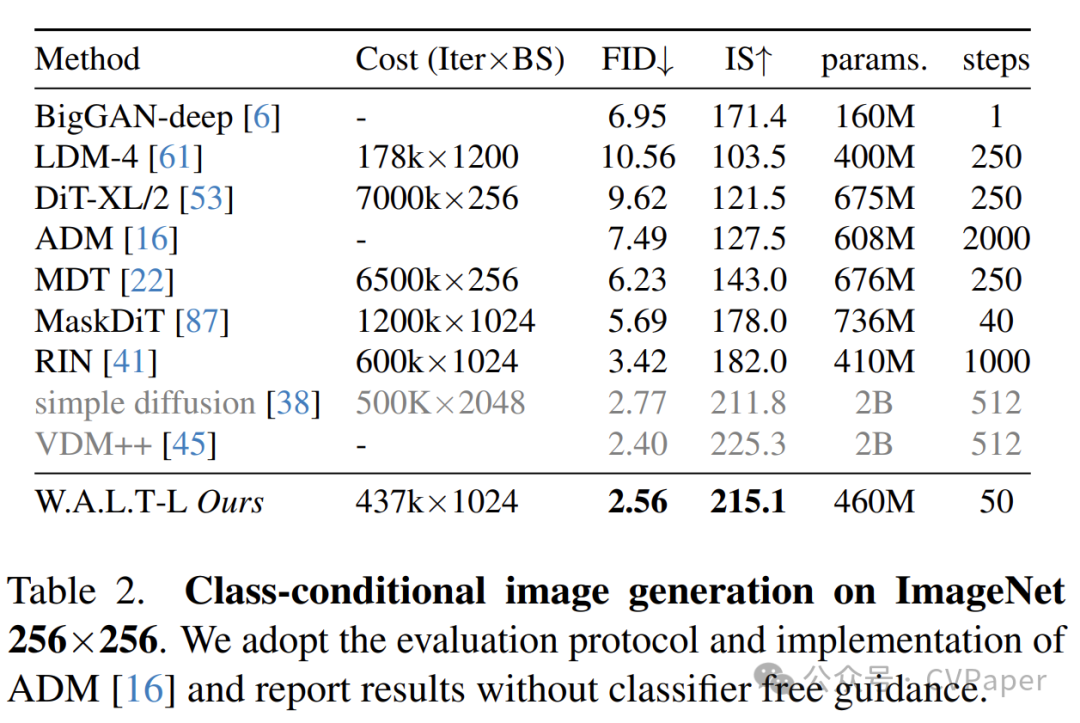
尽管在概念上简单,但我们的方法在公共基准上首次提供了Transformer在潜在视频扩散中生成质量和参数效率方面的优越性的实证证据。具体来说,我们在类别条件视频生成(UCF-101 [70])、帧预测(Kinetics-600 [9])和类别条件图像生成(ImageNet [15])上报告了最先进的结果,而无需使用无分类器指导。最后,为了展示我们方法的可扩展性和效率,我们还展示了在具有挑战性的照片级文本到视频生成任务上的结果。我们训练了一个由三个模型组成的级联,包括一个基础潜在视频扩散模型和两个视频超分辨率扩散模型,以生成512×896分辨率、每秒8帧的视频,并在UCF-101基准上报告了最先进的零样本FVD分数。

扩散公式
扩散模型 [33, 67, 69] 是一类生成模型,通过迭代去噪从噪声分布中抽取的样本来学习生成数据。高斯扩散模型假设一个正向噪声过程,逐渐将噪声()应用于真实数据()。具体来说,
其中 , 是一个从1到0的单调递减函数(噪声调度)。扩散模型被训练来学习反向过程,反转正向的腐败过程:
其中 是由神经网络参数化的去噪器模型, 是条件信息(例如类别标签或文本提示),目标 可以是随机噪声 、去噪输入 或 。根据 [34, 63],我们在所有实验中使用 v-预测。
潜在扩散模型(LDMs)
使用原始像素处理高分辨率图像和视频需要大量的计算资源。为了解决这个问题,LDMs在VQ-VAE [20, 72] 的低维潜在空间中操作。VQ-VAE由一个编码器 组成,将输入视频 编码为潜在表示 。编码器将视频下采样一个因子 和 ,其中 对应于使用图像自编码器。与原始VQ-VAE的一个重要区别是,扩散模型可以在连续潜在空间上操作,而无需量化嵌入的码本。解码器 被训练来从 预测视频的重构 。根据VQ-GAN [20],通过添加对抗性 [25] 和感知损失 [43, 86],可以进一步提高重建质量。
PartW.A.L.T
学习视觉标记
视频生成建模中的一个关键设计决策是潜在空间表示的选择。理想情况下,我们希望一个共享和统一的压缩视觉表示,可用于图像和视频的生成建模 [74, 82]。统一表示非常重要,因为联合图像-视频学习更可取,因为标记的视频数据稀缺 [34],例如文本-视频对。具体来说,给定一个视频序列 ,我们旨在学习一个低维表示 ,通过因子 在空间上和因子 在时间上进行时空压缩。为了实现图像和静态图像的统一表示,第一帧总是独立于视频的其余部分进行编码。这允许将静态图像 视为具有单帧的视频,即 。
我们使用MAGVIT-v2标记器的因果3D CNN编码器-解码器架构实例化这一设计 [82]。通常,编码器-解码器由常规的3D卷积层组成,无法独立处理第一帧 [23, 81]。这一限制源于常规卷积核大小为 的卷积核将在输入帧之前和之后分别操作 和 帧。因果 3D卷积层解决了这个问题,因为卷积核仅在过去的 帧上操作。这确保了每帧的输出仅受前帧的影响,从而使模型能够独立地标记第一帧。
学习生成图像和视频
Patchify。 遵循原始ViT [18],我们独立地将每个潜在帧“patchify”为一系列非重叠的 补丁,其中 ,, 是补丁大小。我们使用可学习的位置嵌入 [73],这些嵌入是空间和时间位置嵌入的总和。位置嵌入被添加到补丁的线性投影 [18] 中。请注意,对于图像,我们只需添加对应于第一潜在帧的时间位置嵌入。
窗口注意力。 完全由全局自注意力模块组成的Transformer模型在计算和内存成本上非常高,尤其是在视频任务中。为了效率和处理图像和视频的联合,我们在窗口 [27, 73] 中计算自注意力,基于两种非重叠配置:空间(S)和时空(ST),参见图2。空间窗口(SW) 注意力限制在大小为 的潜在帧内的所有标记(第一维度是时间)。SW建模图像和视频中的空间关系。时空窗口(STW) 注意力限制在大小为 的3D窗口内,建模视频潜在帧之间的时间关系。对于图像,我们简单地使用_恒等_注意力掩码,确保对应于图像帧潜在的_值_嵌入通过该层传递。最后,除了绝对位置嵌入外,我们还使用相对位置嵌入 [49]。
我们的设计虽然概念上简单,但实现了计算效率,并启用了图像和视频数据集的联合训练。与基于帧级自编码器的方法 [4, 24, 27] 相比,我们的方法不会出现闪烁伪影,这些伪影通常是由于独立编码和解码视频帧引起的。然而,与Blattmann等人 [4] 类似,我们也可以通过简单地交错STW层来潜在地利用具有Transformer骨干的预训练图像LDMs。
条件生成
为了实现可控的视频生成,除了时间步 的条件外,扩散模型通常还根据额外的条件信息 (如类别标签、自然语言、过去帧或低分辨率视频)进行条件化。在我们的Transformer骨干中,我们结合了三种条件机制,如下所述:
交叉注意力。 除了窗口Transformer块中的自注意力层外,我们还为文本条件生成添加了一个交叉注意力层。当仅在视频上训练模型时,交叉注意力层使用与自注意力层相同的窗口限制注意力,这意味着S/ST块将具有SW/STW交叉注意力层(图2)。然而,对于联合训练,我们仅使用SW交叉注意力层。对于交叉注意力,我们将输入信号(查询)与条件信号(键、值)连接,因为我们的早期实验表明这可以提高性能。
AdaLN-LoRA。 自适应归一化层是广泛生成和视觉合成模型中的重要组件 [16, 19, 44, 52, 53, 54]。一种简单的自适应层归一化方法是,为每层 包含一个MLP层,以回归条件参数向量 ,其中 ,,, 是条件和时间步嵌入。在Transformer块中, 和 分别缩放和偏移多头注意力和MLP层的输入,而 缩放多头注意力和MLP层的输出。这些额外MLP层的参数数量随层数线性增长,随模型维度大小二次方增长()。例如,在具有1B参数的ViT-g模型中,MLP层贡献了额外的475M参数。受 [40] 启发,我们提出了一种简单的解决方案,称为_AdaLN-LoRA_,以减少模型参数。对于每层,我们回归条件参数为
其中 ,。当 时,这显著减少了可训练模型参数的数量。例如,具有 的ViT-g模型将MLP参数从475M减少到12M。
自条件。 除了外部输入的条件外,迭代生成算法还可以在推理过程中根据其先前生成的样本进行条件化 [3, 13, 65]。具体来说,Chen等人 [13] 修改了扩散模型的训练过程,使得在一定概率 下,模型首先生成样本 ,然后使用另一个前向传递来细化该估计,条件是这个初始样本:。在概率 下,仅进行一次前向传递。我们将模型估计与输入沿通道维度连接,并发现这种简单的技术在与_v-预测_结合使用时效果良好。
自回归生成
为了通过自回归预测生成长视频,我们还联合训练我们的模型进行_帧预测_任务。这是通过在训练期间以概率 对模型进行过去帧的条件化来实现的。具体来说,模型使用 进行条件化,其中 是一个二进制掩码。二进制掩码指示用于条件化的过去帧的数量。我们对1个潜在帧(图像到视频生成)或2个潜在帧(视频预测)进行条件化。这种条件化通过沿噪声潜在输入的通道维度连接集成到模型中。在推理过程中,我们使用标准的无分类器指导,将 作为条件信号。

视频超分辨率
使用单个模型生成高分辨率视频在计算上是不可行的。遵循 [35],我们使用级联方法,通过三个在增加分辨率上操作的模型。我们的基础模型生成 分辨率的视频,随后通过两个超分辨率阶段进行两次上采样。我们首先使用深度到空间卷积操作对低分辨率输入 (视频或图像)进行空间上采样。请注意,与训练时可以使用真实低分辨率输入不同,推理依赖于前一阶段生成的潜在。为了减少这种差异并提高超分辨率阶段处理低分辨率阶段生成伪影的鲁棒性,我们使用噪声条件增强 [35]。具体来说,根据 添加噪声,通过采样噪声水平 并将其提供给我们的_AdaLN-LoRA_层。
宽高比微调。 为了简化训练并利用具有不同宽高比的广泛数据源,我们使用方形宽高比训练基础阶段。我们通过对位置嵌入进行插值,在数据子集上微调基础阶段,以生成 宽高比的视频。
Part实验结果





如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 1911
1911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









