






本文介绍一篇相当有意思的文章,该文章的内容对我们使用指令微调将预训练模型改造为 Chat 模型和下游专业模型相当有指导意义。
本文的标题听起来有些唬人,有些标题党,但是这个论点在一定的限定条件下是成立的,笔者归纳为:对充分预训练的模型使用通用指令微调数据集进行全量微调有害。
01
LoRA指令微调并不能学习知识,但它很优秀
试图使用指令微调来为模型灌输知识,其实是一个很常见的做法。然而只要这样做过的人会发现,效果并不会特别好,特别是使用 LoRA 训练时,模型几乎学不到任何知识。
笔者自己的实践是,在使用 LoRA 对一个 Llama 3.1 本身没有怎么预训练过的内容进行微调时,最终的结果和随机预测基本没有区别(分类和回归任务改造的指令微调数据集)。
这提示我们,在使用指令微调对模型进行训练时,首先需要确定模型是否预训练过相关内容,如果没有,最好进行补充性的继续预训练。
如何衡量模型是否通过指令微调学习到了知识?

作者团队使用了多个指令微调数据集,分别通过全量和 LoRA 的方式对 Llama2_7B 进行训练,并且查看了模型在以上三个标准下的表现。
作者团队使用了多个指令微调数据集,分别通过全量和 LoRA 的方式对 Llama2_7B 进行训练,并且查看了模型在以上三个标准下的表现。
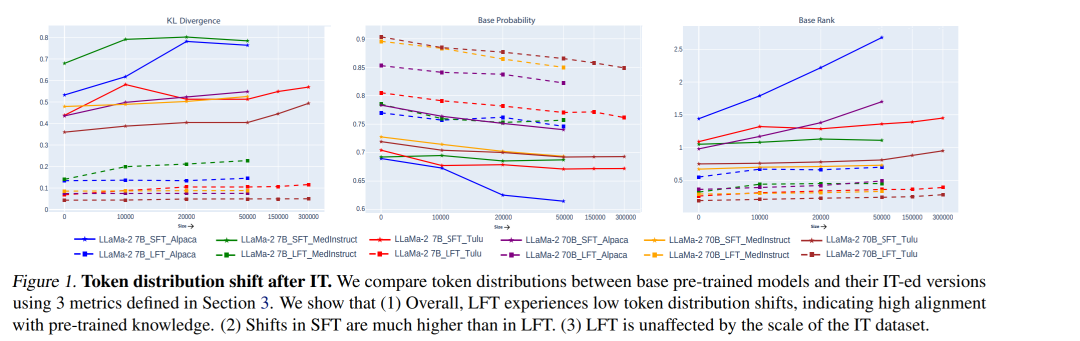
图1:指令微调后模型概率分布的变化,图中LFT指LoRA训练,SFT指全量训练
结论一: LoRA 仅能够让模型学会输出的格式,完全无法获取新知识,同时增大数据集的规模对 LoRA 无效。
从图一中我们可以发现,通过 LoRA 训练后,模型的概率分布偏移的并不大。
模型仅在前百分之五的概率分布中有比较大的 KL 散度发散,而在余下的概率分布中几乎保持不变,并且与全量训练相比,LoRA 训练的 KL 散度偏移接近于 0。
这说明 LoRA 仅仅做到了学会输出的格式,而做不到学会具体的知识。体现在 loss 上我们可以发现,使用 LoRA 训练时模型收敛的非常快,然而在快速收敛之后 loss 保持平稳,无法进行进一步的下降。
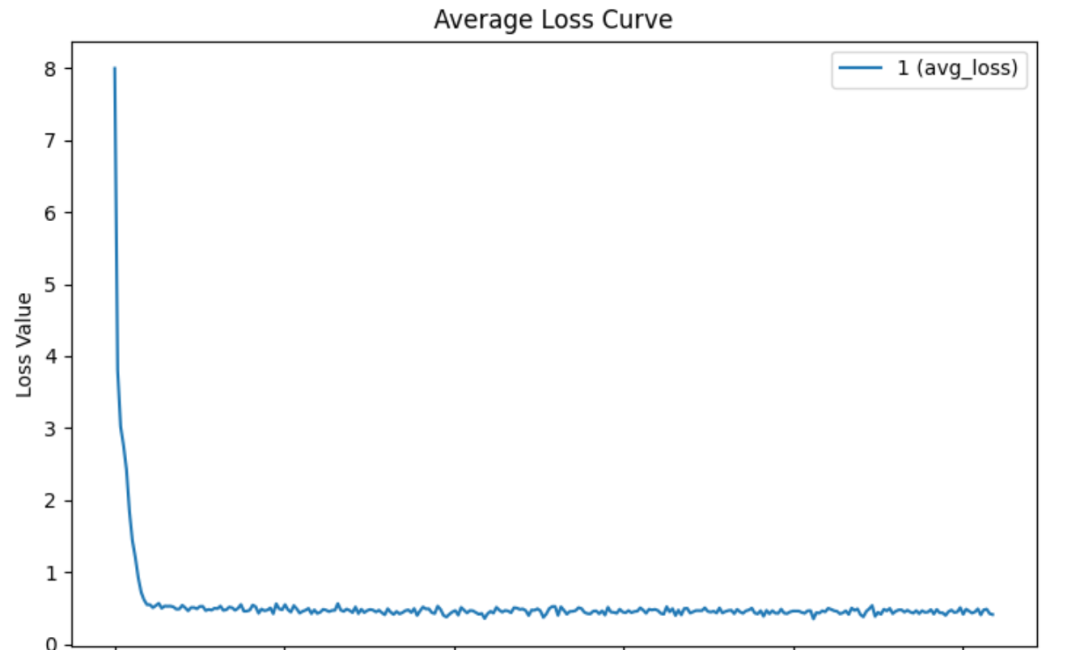
图2:LoRA 无法学会新知识的一个例子,快速收敛后 loss 无法下降
在这种情况下,增加数据集的规模对模型是无效的。现在许多研究将下游训练的指令微调数据集扩大到百万级的规模,这种做法并不能进一步提高模型的性能。
即使将数据集的规模扩大 52 倍;扩大 326 倍,也没有作用。在图三中可以发现,扩大数据集规模后 LoRA 训练的模型在五个维度上的表现都没有得到增强。
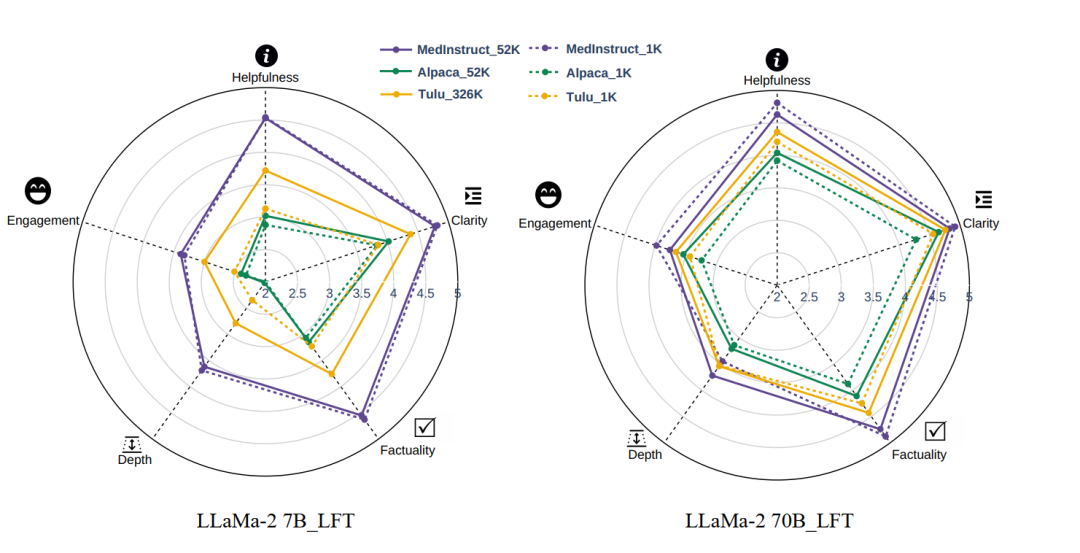
图3:扩大数据集的规模对 LoRA 无效,途中实线为大数据集的结果,虚线为小数据集的结果
结论二: 即使 LoRA 并不能让模型学会新的知识,它也比全量微调强。
当然,这个结论有一个前提,那就是模型在相关领域上有充分的预训练。经过充分预训练之后,将模型应用到聊天上,只需要令其学会输出结果的格式。
而不需要让其学会新的知识,因为模型能够依靠充足的知识储备来给出正确回答。而新的知识反而会扰乱这种知识储备。
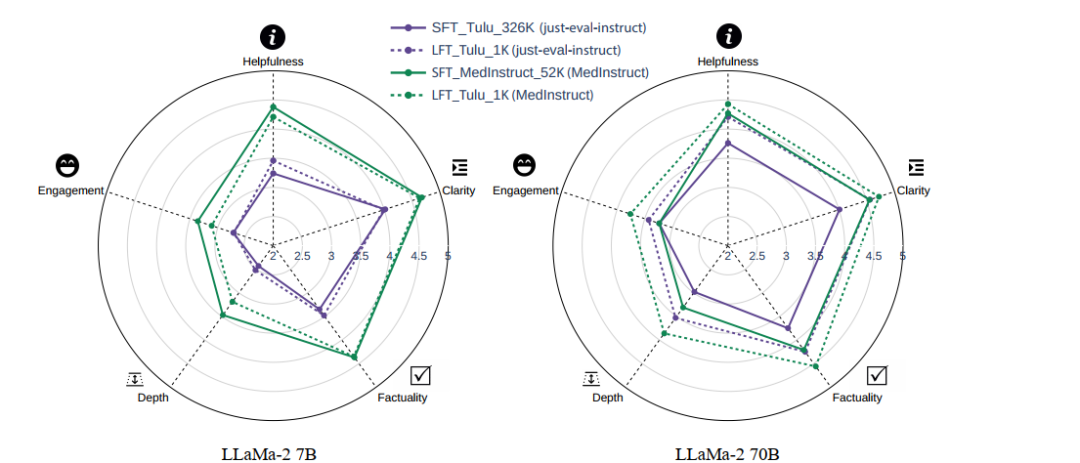
图4:LoRA 的性能优于全量微调,图中实线为全量微调,虚线为 LoRA 训练
可以看到在 70B 的模型中 LoRA 微调全面优于全量微调,这得益于 70B 模型具备更全面的知识储备。
说了这么多,以上内容其实可以用一句话来概括:LoRA 指令微调并不能让模型学会新的知识,但是它能比全量训练更好的使模型利用好预训练知识。
02
全量微调有害
(1)从模式复制说起
指令微调数据集通常都有自己的模式,最典型的例子,去年被很多大模型厂商用来训练自己的模型的非常受欢迎的 ShareGPT 数据集。由于该数据集是由与 ChatGPT 对话而来,它完全是 ChatGPT 的风格。
使用 ShareGPT 训练模型会使模型的风格贴近 ChatGPT,甚至认为自己就是 ChatGPT。使用有明显风格的数据集训练模型,会让模型进行模式复制。
模式复制有两种:
- 模仿指令微调数据集中的用词。
- 模型指令微调数据集中的风格。
我们会认为第一种模式复制是有害的,因为模型在测试场景中使用训练场景中的用词,可能会导致严重的幻觉。
毕竟指令微调的目的是让模型更好的利用预训练知识,而不是强行使用指令微调数据集中可能与测试场景无关的词语。
(2)全量微调会学习指令微调数据集中的用词导致严重的幻觉
作者团队研究了全量微调和 LoRA 微调后模型输出概率分布中的边缘偏移 token 和偏移 token。
发现 LoRA 训练后的偏移 token 常常为风格 token,例如 However 和 Typically。
而全量微调中的偏移 token 包含了指令微调数据集中出现的所有 token,也就是说全量微调可能会把指令微调数据集中的任何 token 利用到测试场景中,即使这些 token 与测试场景无关。
图五给出了一些例子,例如在图五的左边。测试场景的提问为是什么导致了极光,而全量微调的模型大量使用了指令微调数据集中问题为“哪里能看到极光“的样本中的 token,这导致了输出的内容偏离了实际的提问,而 LoRA 训练的模型则正确的回答了该问题。
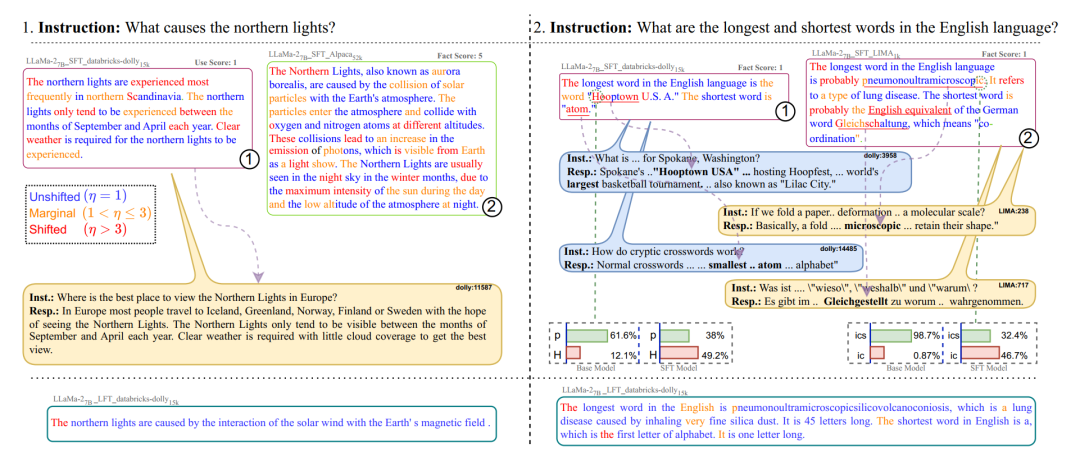
图5
全量微调会让模型在测试场景中使用指令微调数据集中的相似样本中的 token,即使这些 token 实际上是无关的。这导致了模型答非所问,而 LoRA 微调的模型正确的回答了问题。
同时,风格模仿在一些时候也是有害的,例如模型的预训练知识并不充足,而指令微调的数据风格为让模型输出足够长的回答,这会导致模型原本能正确回答的问题中出现了幻觉。
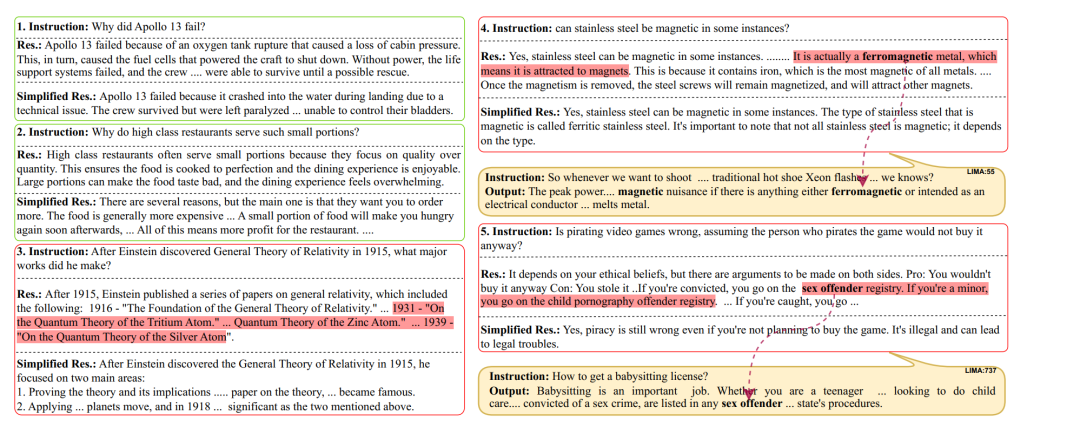
图6:风格模仿的一些有害实例
图六中给出了一些例子,模型在强行输出足够长的回答的情况下,出现了幻觉。而原本简短的回答是正确的。
这说明在使用这种指令微调数据集的时候要考虑模型是否经过了充分的预训练。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 2193
2193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









