 矢量数据库与AI应用
矢量数据库与AI应用





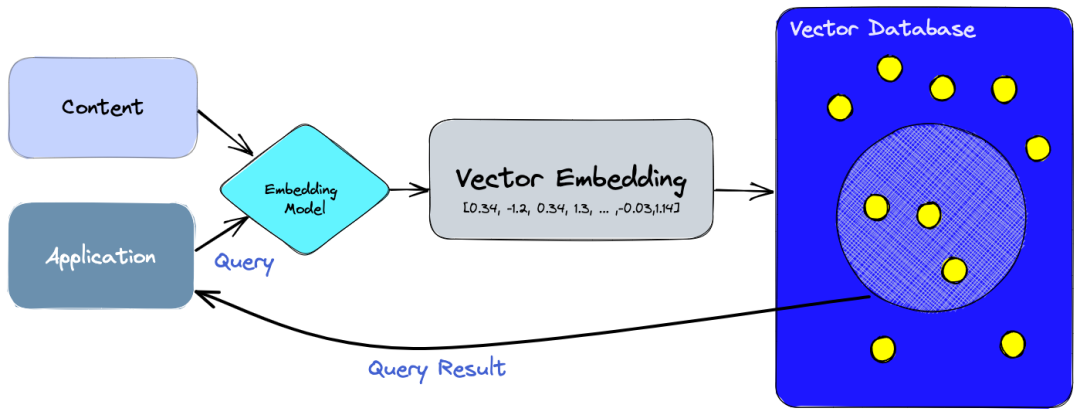
矢量数据库为管理高维数据提供了专门的解决方案,这对人工智能的上下文决策至关重要。但它们究竟是如何做到的呢?

介绍
信息有多种形式。有些信息是非结构化的,例如文本文档、图片和音频。有些则是结构化的,例如应用程序日志、表格和图表。怎么把这些数据进行统一存储和检索呢?矢量数据库就是为了解决这个问题而诞生的。
向量数据库能够将向量存储为高维数据点并进行高效检索。将文档信息利用text Embedding算法进行嵌入,形成文本向量;同理,可通过多模态表征算法将video/image/audio数据进行表征,生成稠密嵌入向量。然后将稠密向量存入到矢量数据库(如:Pinecone),然后利用相似算法进行高效检索。
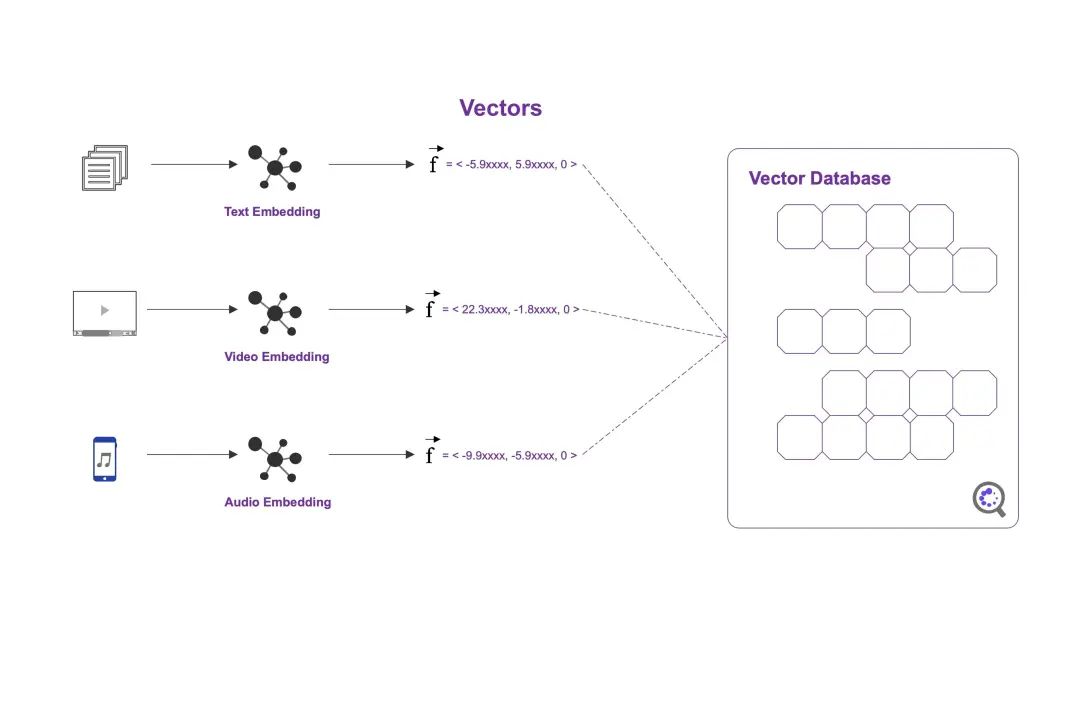

矢量数据库创建和检索
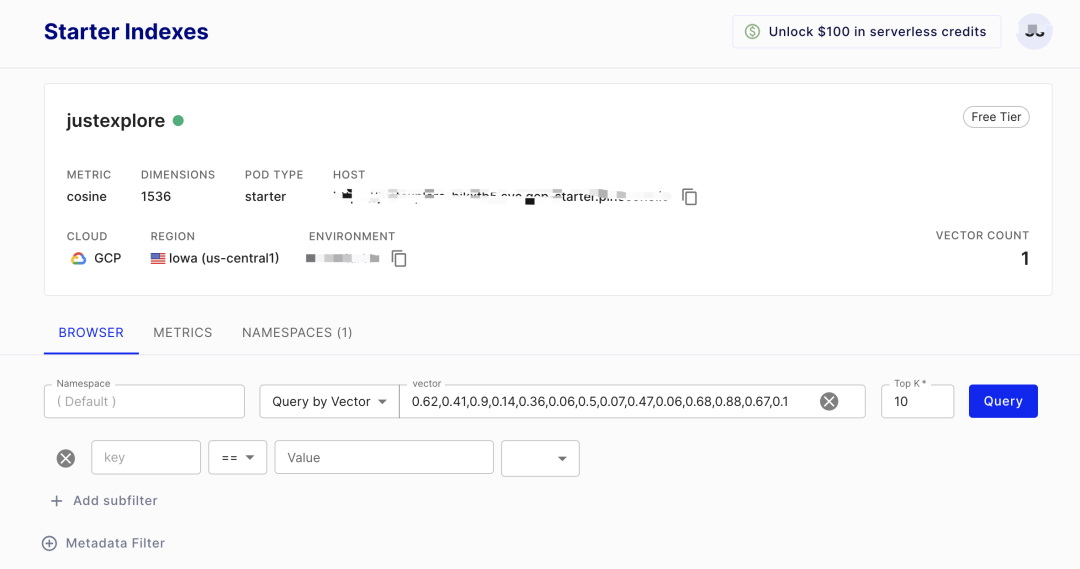
安装矢量数据库,例如:Pinecone(私人账号免费)。需要设置嵌入向量的维度和检索指标。由于openAI嵌入模型默认输出维度为1536,因此设置和Embedding Model的输出维度保持一致。检索指标是cosine相似度,也就是向量检索时,通过cosine输出Top-K结果。
可以通过API方式进行数据库“增删改查”操作。通过Pinecone的API方式插入数据的代码如下:

矢量数据存入到数据库后的效果如下:
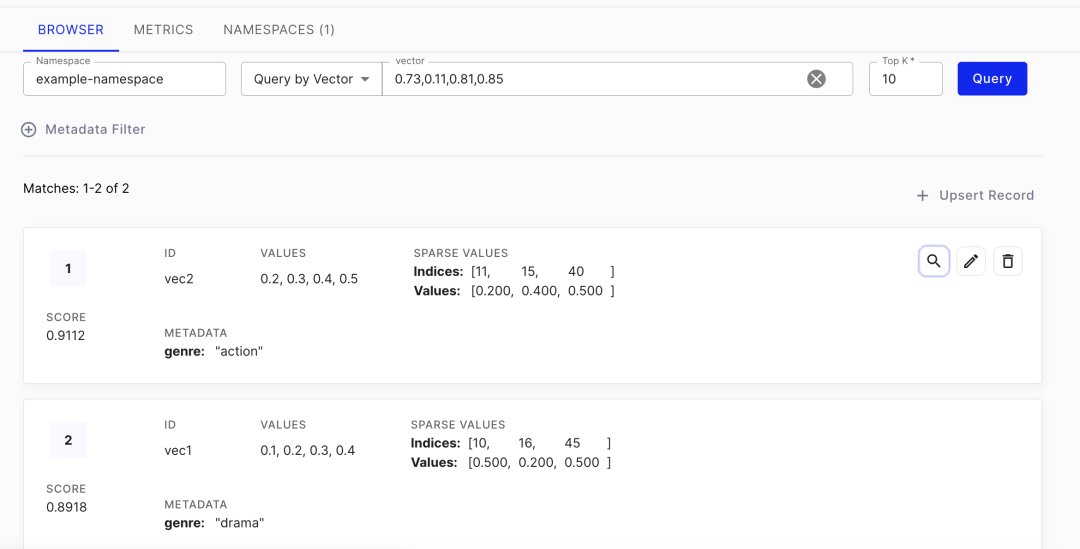
矢量数据库构建完成以后,每个数据点都会表征成一个有方向的向量值(Vector Representation)。当有检索诉求时,可通过相似度算法进行计算,从矢量数据库中输出最相似的向量返回即可。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2773
2773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









