






大语言模型用着爽,但推理速度实在太慢了?
而且,增加模型体积,推理效果也并不一定就比之前更好。
为了解决这一问题,谷歌MIT的研究人员提出了一个新框架CALM,让它自己来决定计算量。
如果CALM意识到某些层“可有可无”,那么它在计算时就会跳过这些层。
论文被po到网上后,立刻火了一波:

有网友表示,我们就是需要这样更智能和自适应的模型,显然CALM的解码器已经做到了:

直接用中间层输出结果
CALM全称Confident Adaptive Language Modeling,即置信自适应大语言模型。
这一模型基于Transformer架构,为了加速它的计算,研究人员提出了一个名叫“提前退出”*(early exiting)*的方法,让模型根据不同的输入,动态决定要用多少层网络来计算。
也就是说,在计算的过程中,模型不需要经过每一层计算再输出结果,而是能直接用中间层的特征输出token,从而降低模型计算量。

所以,模型如何决定“退出”的时机呢?
这就需要训练模型学会自己判断了。
其中,Yfull是标准模型输出的结果,Yearly是模型“提前退出”时输出的结果。为了让Yearly的效果更好,就需要尽可能让它与Yfull保持一致。

当然,不同的任务对于文本输出一致性也有不同的要求,例如对生成结果要求没那么严格(可以生成更多样的语句)的任务,对于Yfull和Yearly的一致性要求就没那么高。
因此作者们也在论文中给出了两个不同的公式,可根据实际情况选用:

在实际操作上,论文通过设置一个局部的token置信度,来检查其对整个生成序列的影响。
模型在解码过程中,会计算每一层的置信度c,并将它与达到“提前退出”的阈值λ相比,如果c大于λ,则模型“提前退出”。

所以,这样的模型实际测试效果究竟如何?
归纳翻译QA任务表现都不错
论文在CNN/DM、WMT和SQuAD三个数据集上进行了测试。
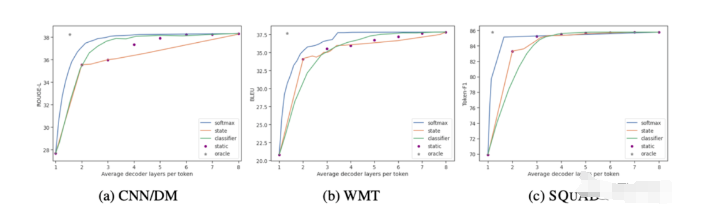
其中,CNN/DM是一个新闻文章数据集,需要输出一个几句话概括文章的结果;WMT15 EN-FR是一个机器翻译数据集,主要是法译英句子的结果;Open-book SQUAD 1.1则是一个根据维基百科提问的QA数据集。

据一作Tal Schuster介绍,在保持相同性能的情况下,CALM使用的解码器层数平均比之前降低了3倍。

对于这篇论文,有网友表示赞同:模型确实不需要总是“长时间深入思考”,有时候几层就能推理出正确答案了。

据作者表示,这一加速解码的思路,适用于任何Seq2seq模型。

如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









