




官网地址:GQA: Visual Reasoning in the Real World (stanford.edu)
一、数据集结构

GQA数据集由三个部分组成:场景图、问题和图像。场景图包含了训练集和验证集中每一张图像的场景图信息;问题包含了回答这个问题所需要的一些推理步骤;图像这个文件夹下面除了有图片,还储存了每张图像中包含的所有对象的特征和每张图像的空间特征。
二、数据集详解
1.allImages
(1)概述
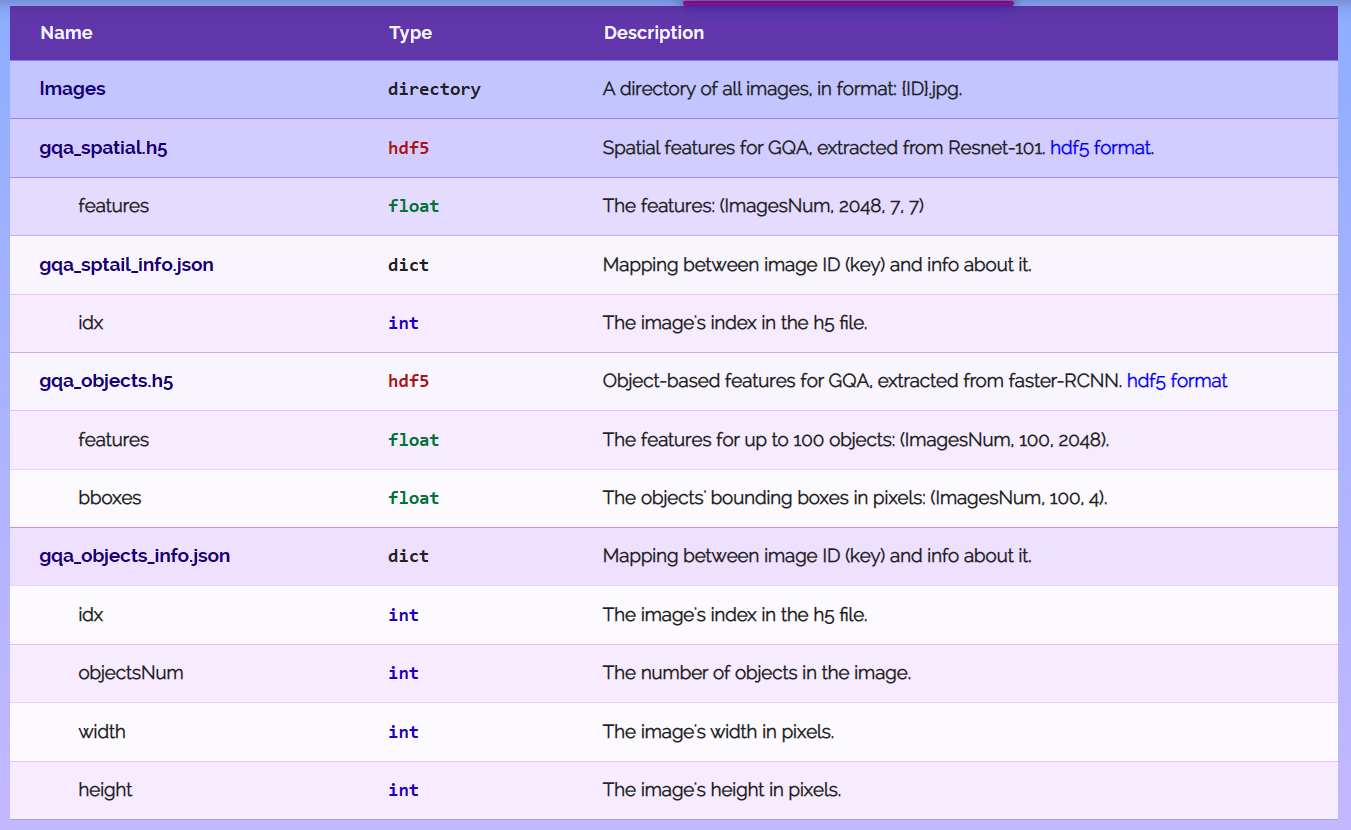
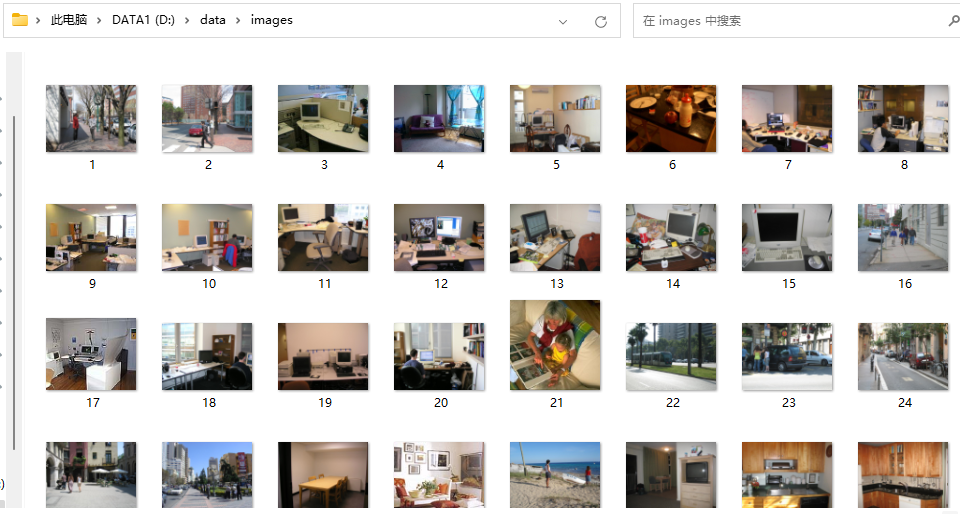
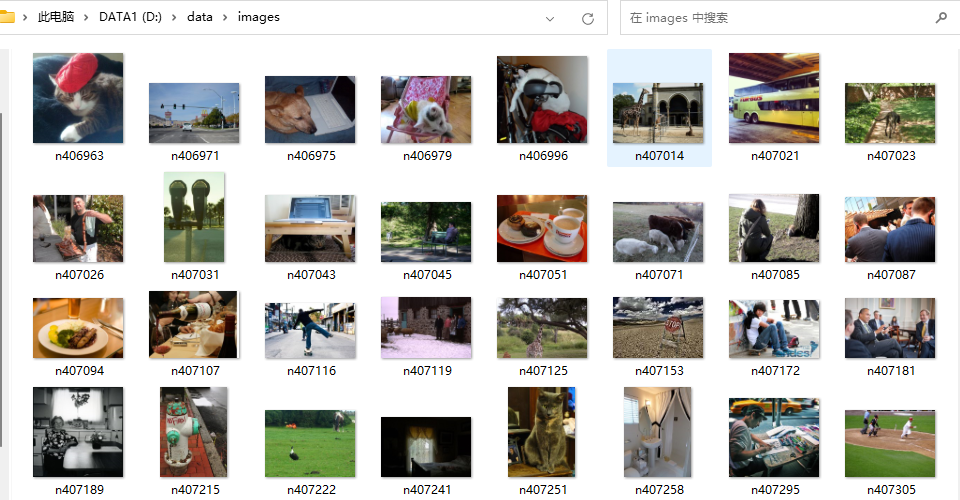
(2)images
存储原始图像的文件夹。
图片数:148854
(3)spatial
存储图片的空间特征。
1> gqa_spatial_0.h5
10000个7*7*2048维的特征。
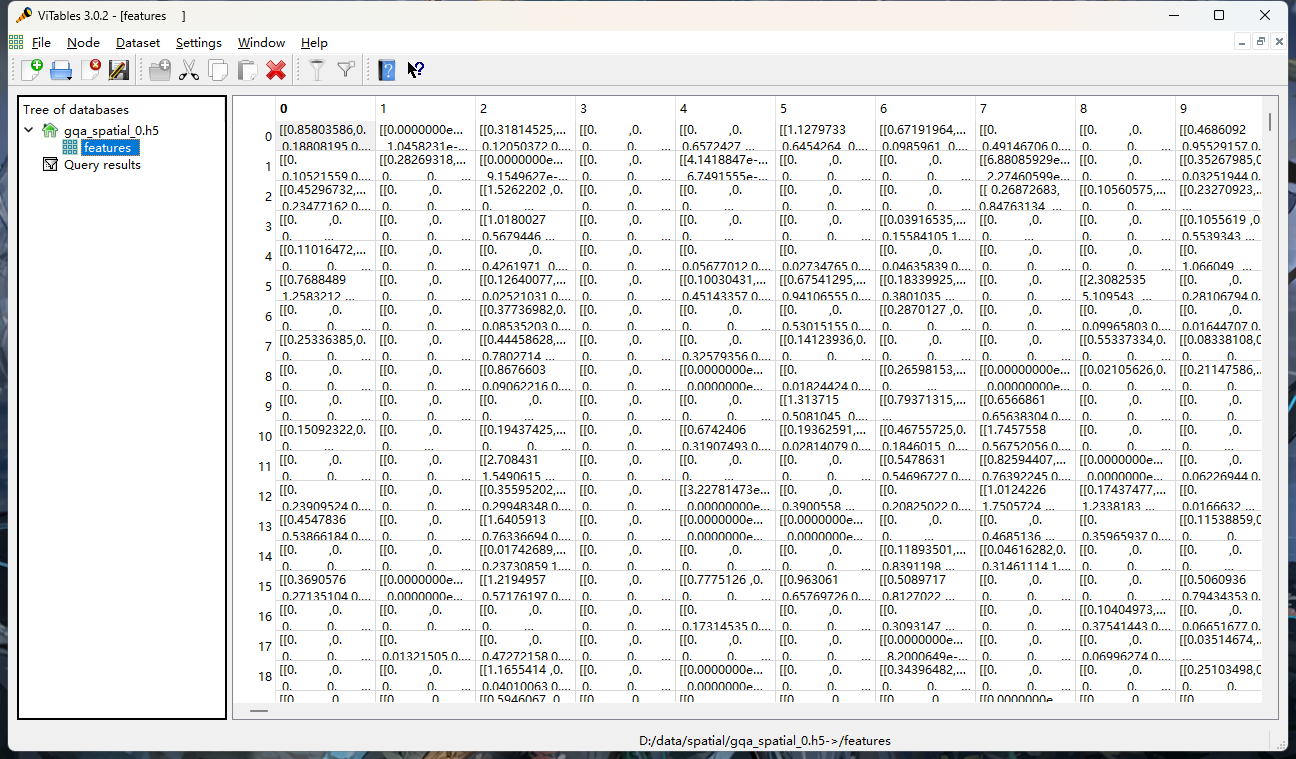
2> gqa_spatial_info.json
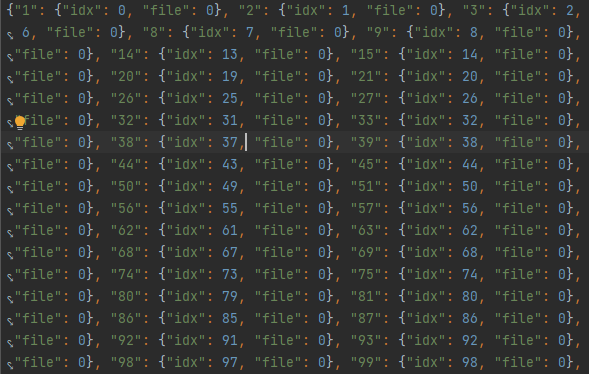
存储相对应的特征,图像编号,以及所在文件位置和索引的字典。
{key:“图片编号” value: {key:“idx” value:h5文件中图像的索引 , key:“file” value:所在文件的索引} }
图片编号:1-2417997(比较连续),n1-n581923(不连续)
特征编号(idx):一般 0-9999,10号文件0-8078,15号文件 0-774
(4)objects
存储图片里的对象特征。
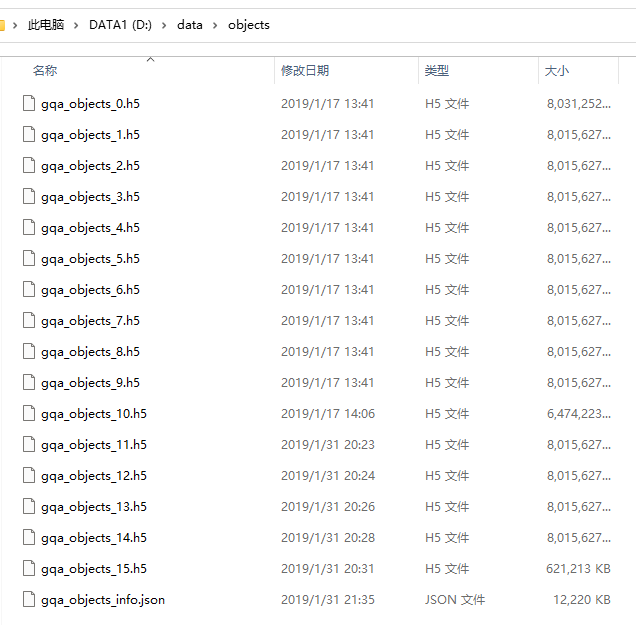
1> gqa_objects_0.h5
分为两个部分:bboxes,features
① bboxes:10000个4*1*100维向量,每一个向量保存一张图像上的所有对象的包围框顶点的坐标
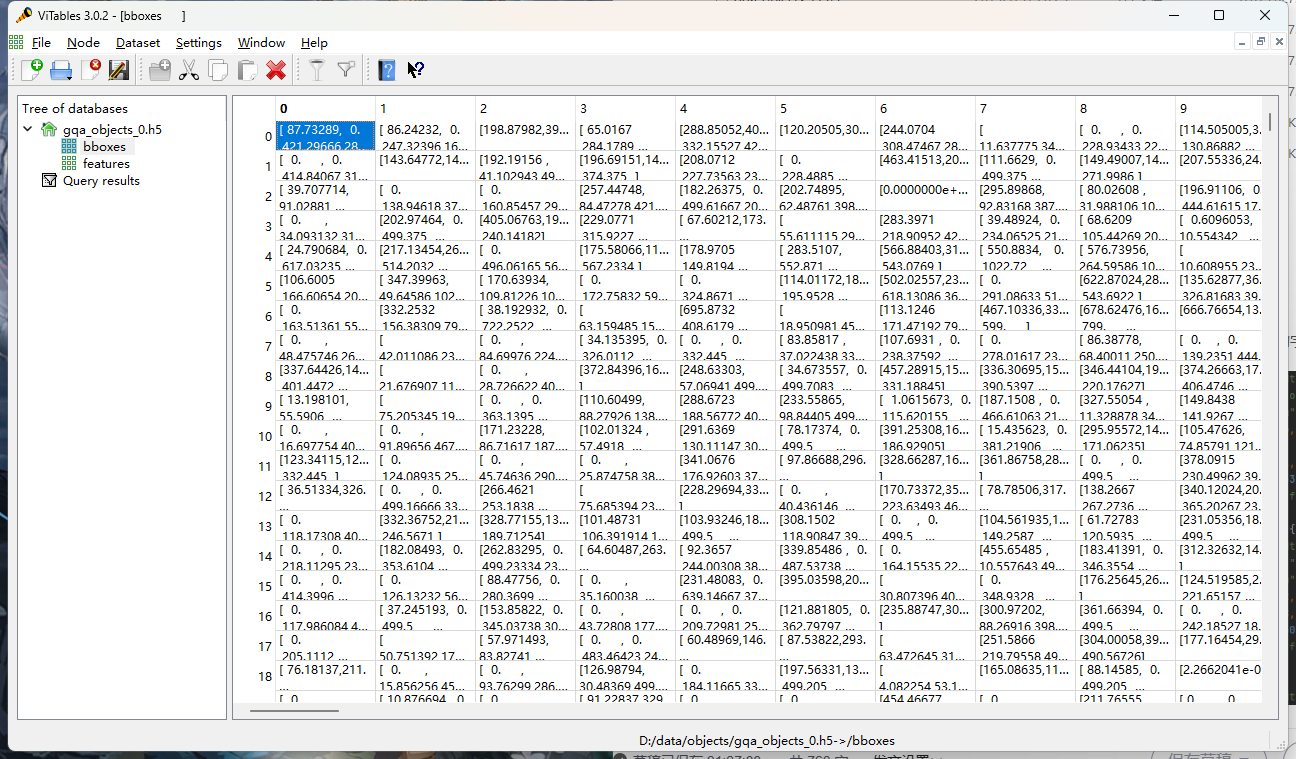
记录每一个框的 x,y,w,h
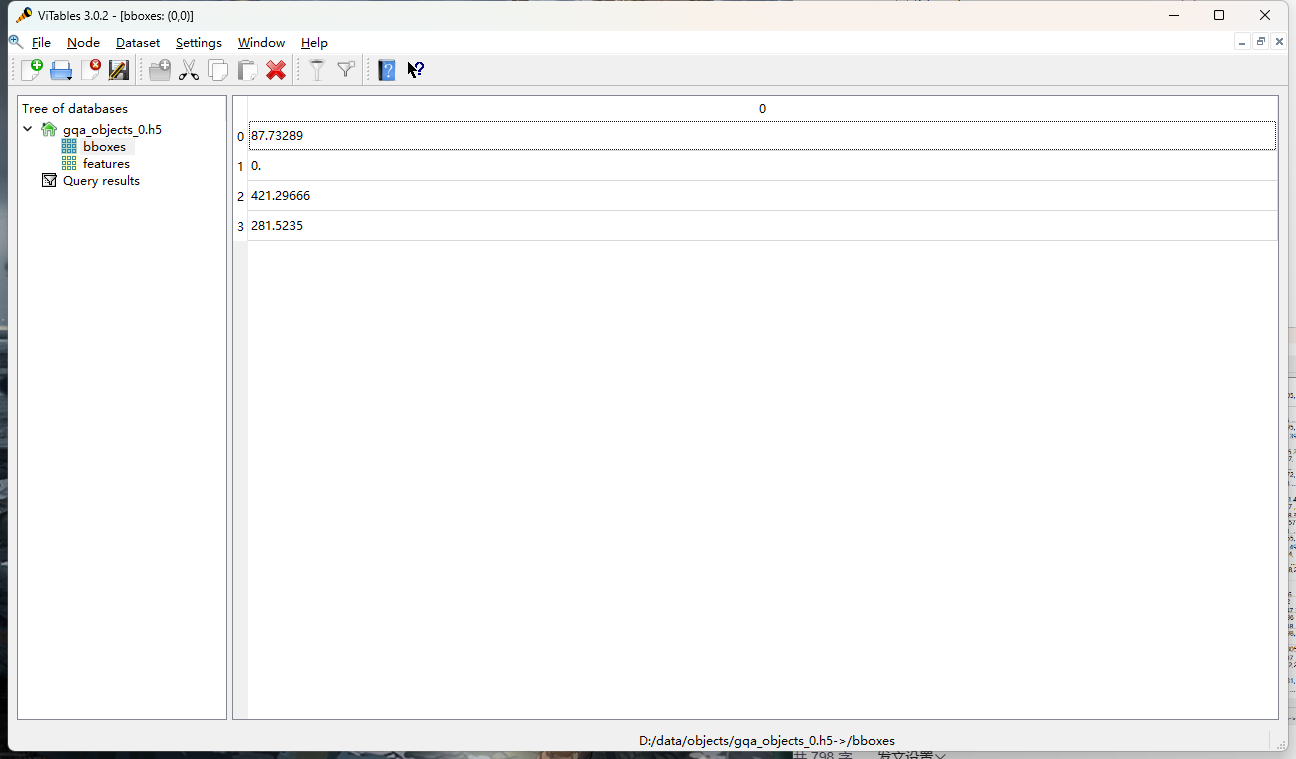
② features
10000个2048*1*100维向量
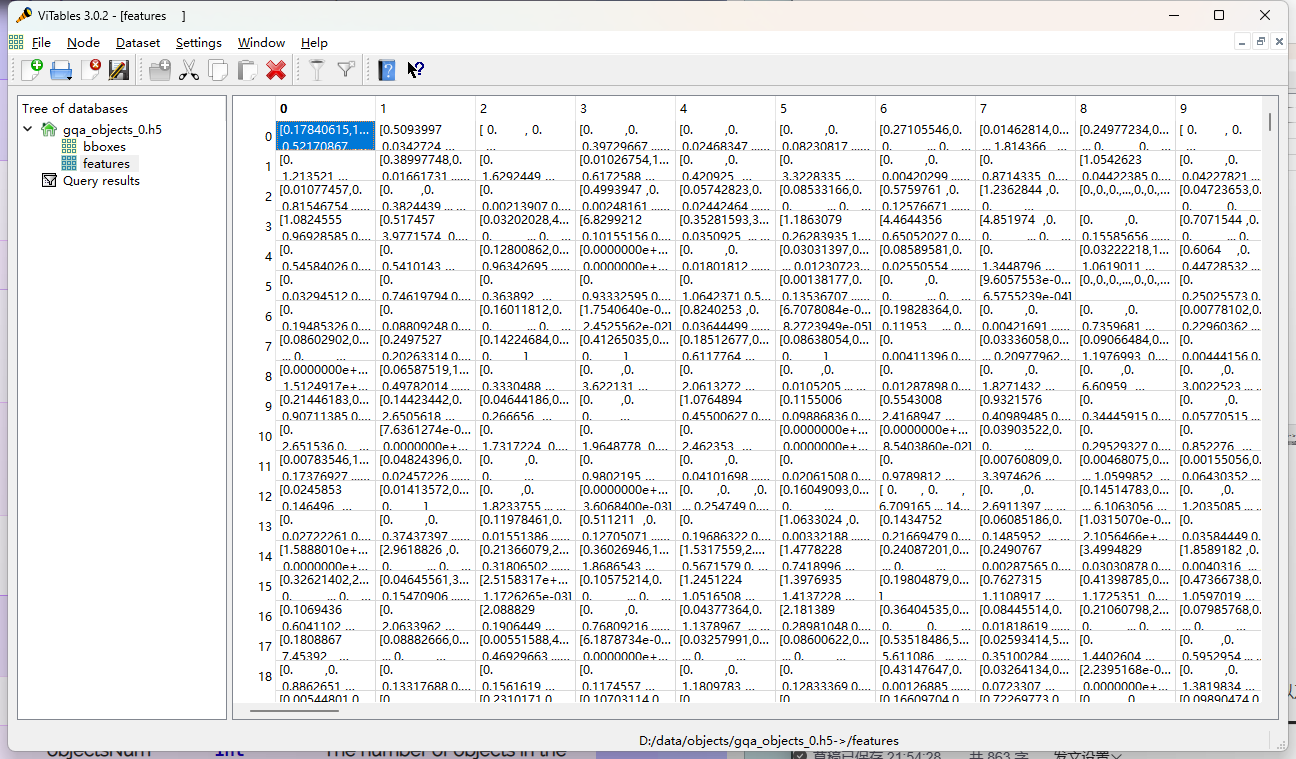
保存每个目标的特征信息
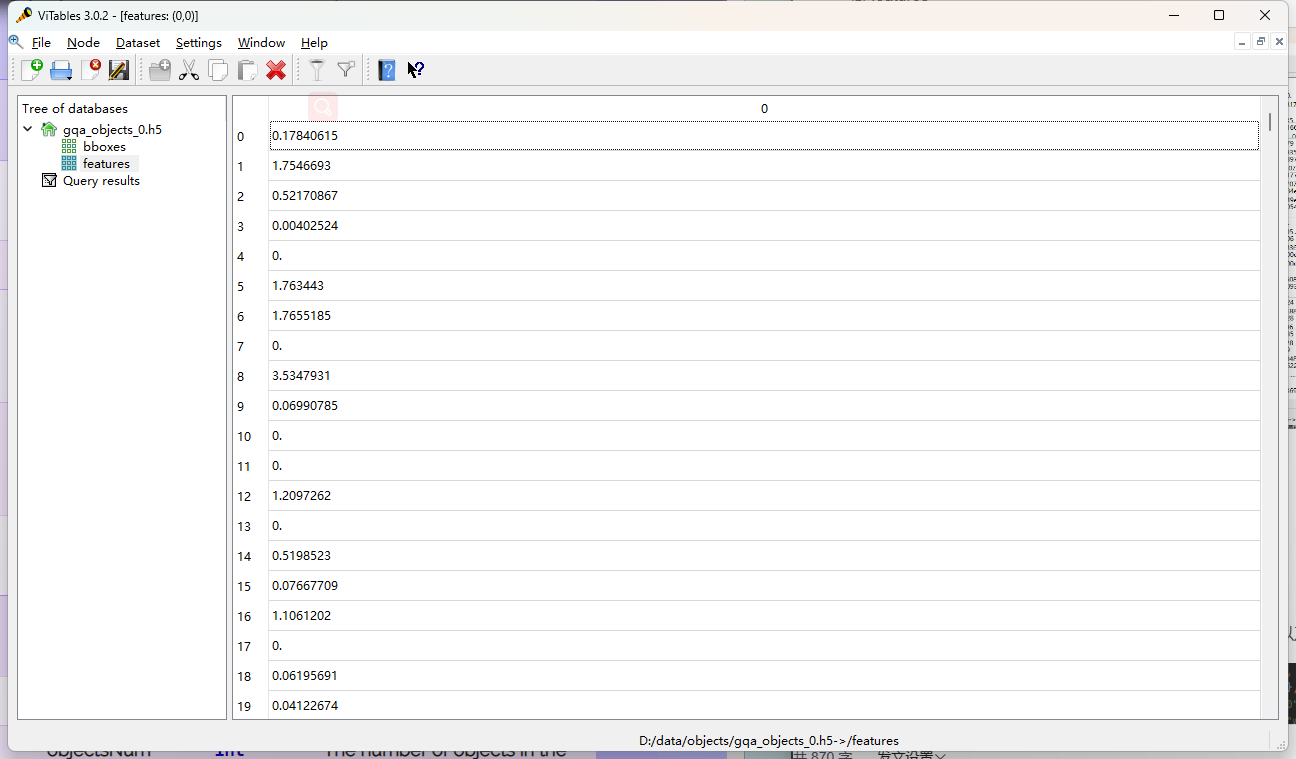
2> gqa_objects_info.json
存储相对应的图像编号,图像中的对象数,图像的宽度和高度以及所在文件位置和索引的字典。
{key:“图片编号” value: {key:“width” value:图像的宽度,key:“objectsNum” value:图片中的对象数,key:“idx” value:h5文件中图像的索引 ,key:“height” value:图像的高度, key:“file” value:所在文件的索引} }
特征编号(idx):一般 0-9999,10号文件0-8078,15号文件 0-774

2.sceneGraphs
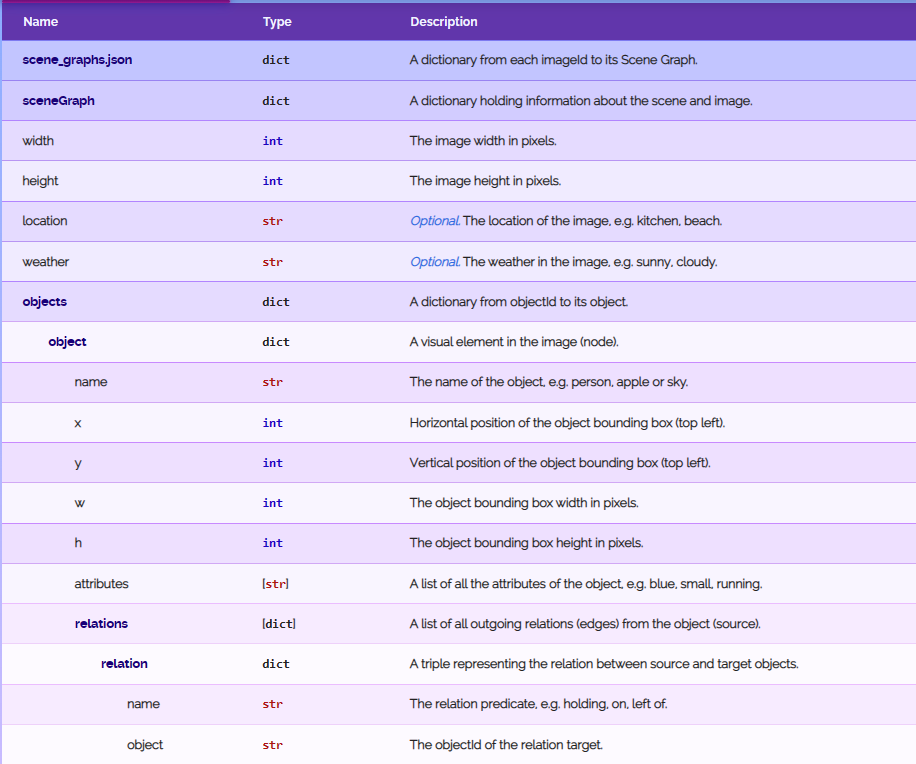
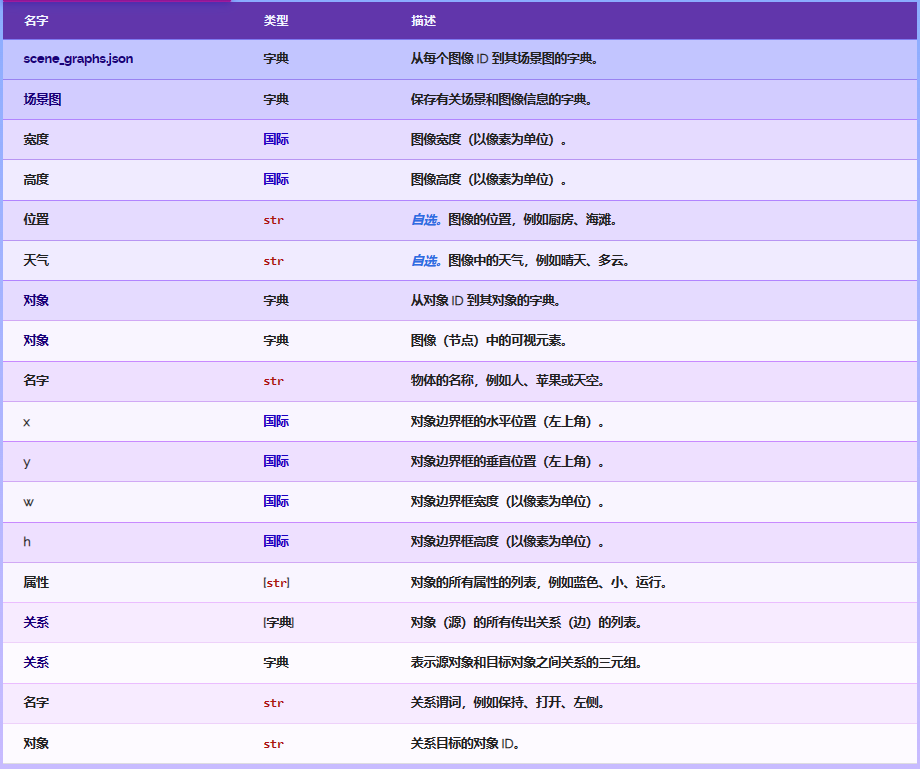
1>train_sceneGraphs.json
{key:图像编号 value:{key:“weather” value:图像里显示的场景的天气,key:“width” value:图像宽度,key:“objects” value:{key:对象编号 value:{key:“name” value:对象名称,key:“h” value:对象高度,key:“relations” value:[{key:“objects” value:对象编号,key:“name” value:对象之间的关系}{key:“objects” value:对象编号,key:“name” value:对象之间的关系}]key:“w” value:对象的宽度,key:“attributes” value:[对象的属性列表],key:“y” value:对象左上角的y坐标,key:“x” value:对象左上角的x坐标}}key:“location” value:图像里显示的其所属的位置,key:“height” value:图像的高度}}


3. questions1.2
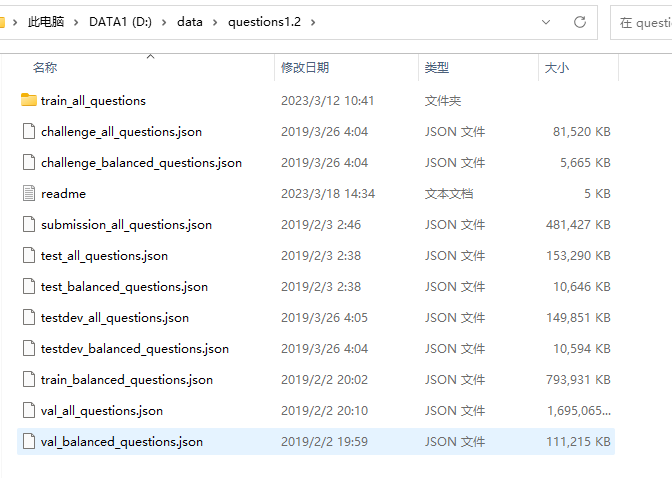


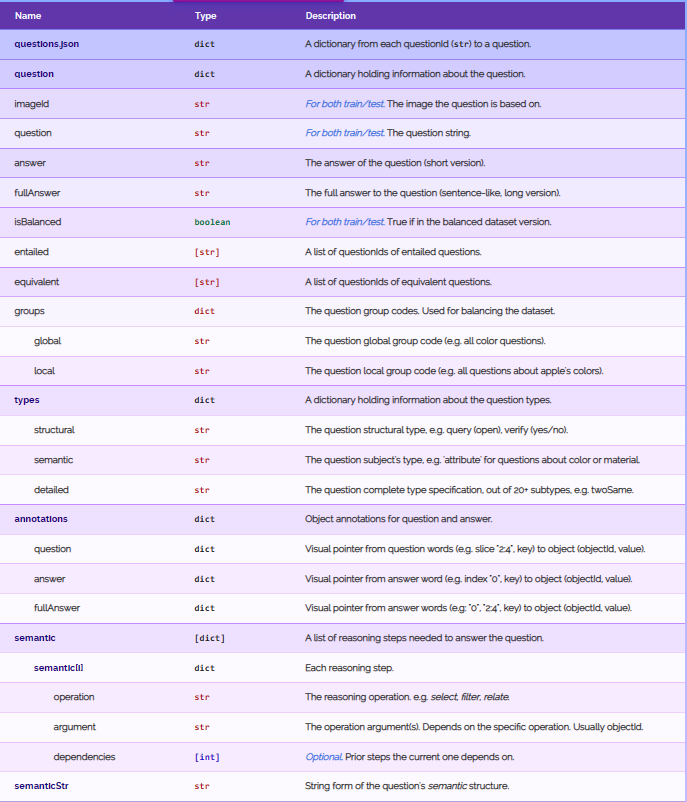
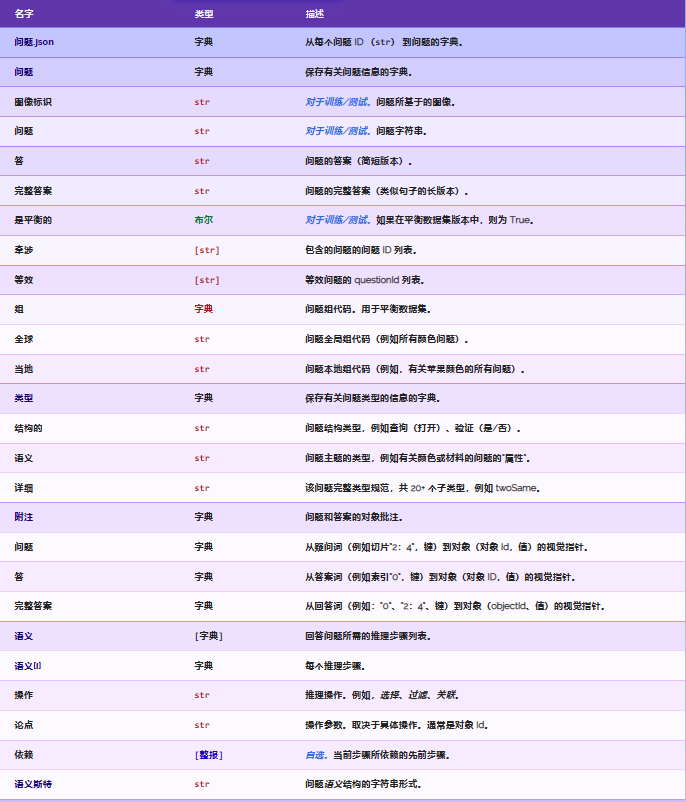
1> train_all_questions/train_all_questions_0.json
{key:问题ID value:{key:“semantic” value:[key:“operation” value:推理操作,key:“dependencies” value:当前步骤所依赖的先前步骤,key:“argument” value:操作参数(取决于具体操作,通常是对象ID)] key:“entailed” value:包含的问题的问题ID列表,key:“equivalent” value:等效问题的问题ID列表,key:“question” value:问题,key:“imgageId” value:问题对应的图片ID,key:“isBalanced” value:是否经过平衡,key:“groups” value:{key:“global” value:问题全局组代码(例如,所有颜色的问题),key:“local” value:问题本地组代码(例如,有关苹果颜色的所有问题)}key:“answer” value:简短答案,key:“semanticStr” value:问题语义结构的字符串形式,key:“annotations” value:{key:“answer” value:从答案词(例如索引“0”,key)到对象(对象 ID,value)的视觉指针,key:“question” value:从疑问词(例如切片“2:4”,key)到对象(对象 Id,value)的视觉指针,key:“fullAnswer” value:{从回答词(例如:“0”、“2:4”、key)到对象(objectId、value)的视觉指针}key:“types” value:{key:“detailed” value:该问题完整类型规范,key:“semantic” value:问题主题的类型,key:“structural” value:问题结构类型}key:“fullAnswer” value:长版答案}}
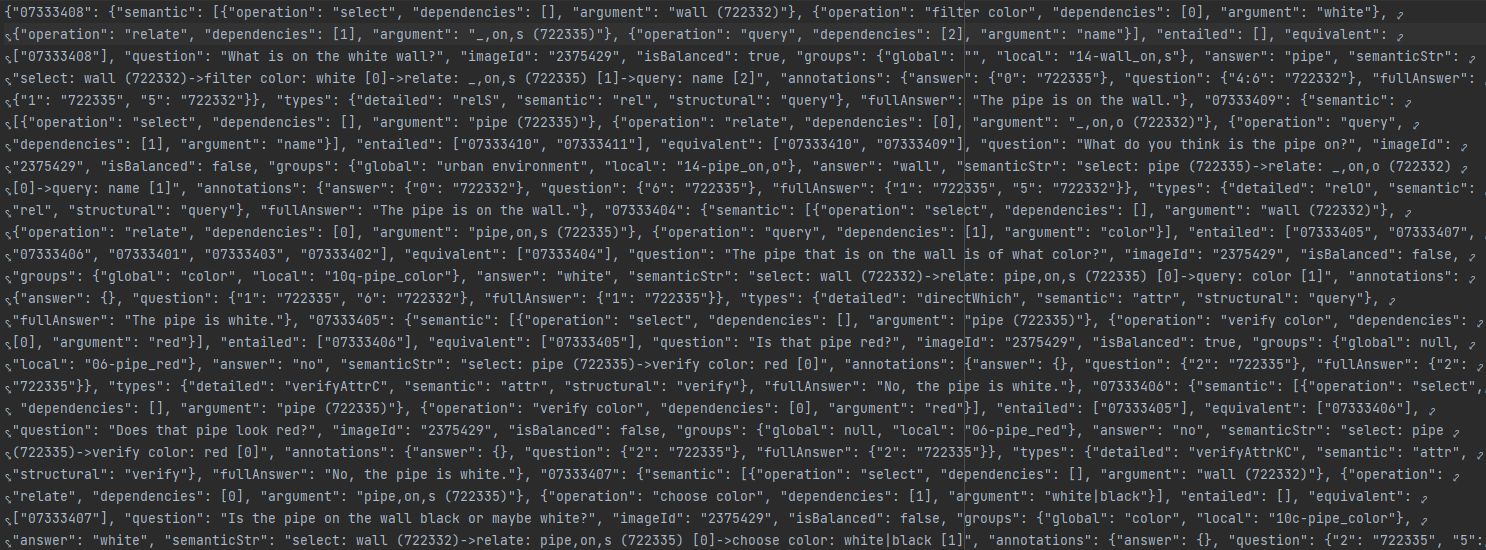

2>testdev_all_questions.json
(测试集)
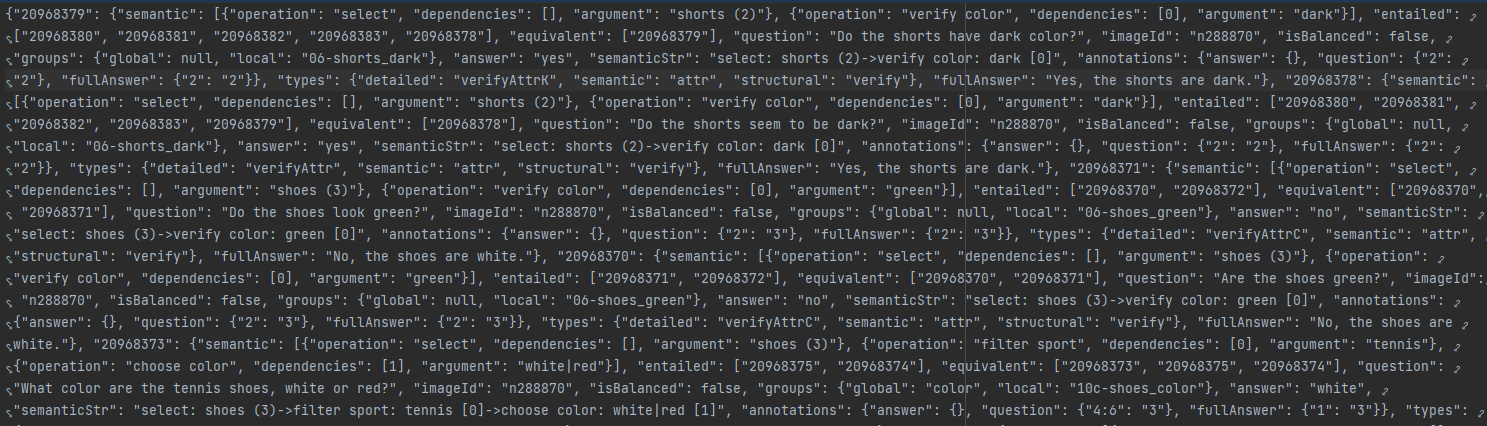
3>test_all_questions.json
(只保留了图像和问题的关联信息以及平衡信息用于测试)
三、一个样本的完整结构
1.图像
路径: images/2266.jpg

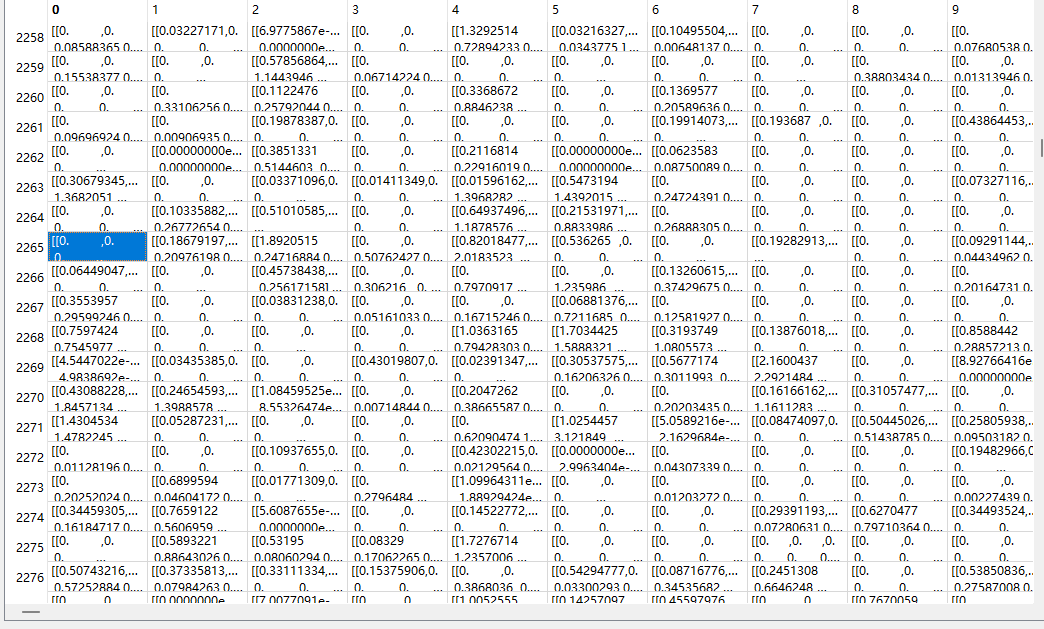
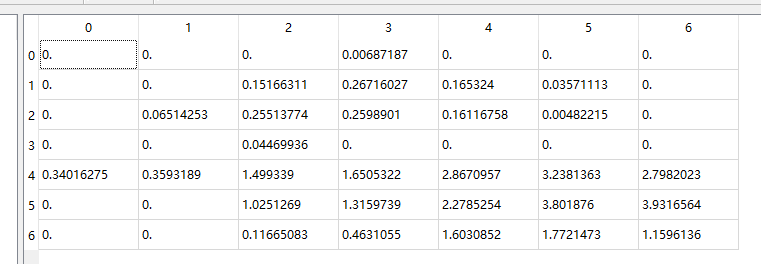
2.空间特征
路径:spatial/gqa_spatial_info.json
"2266": {"idx": 2265, "file": 0}
路径:spatial/gqa_spatial_0.h5
3. 对象特征
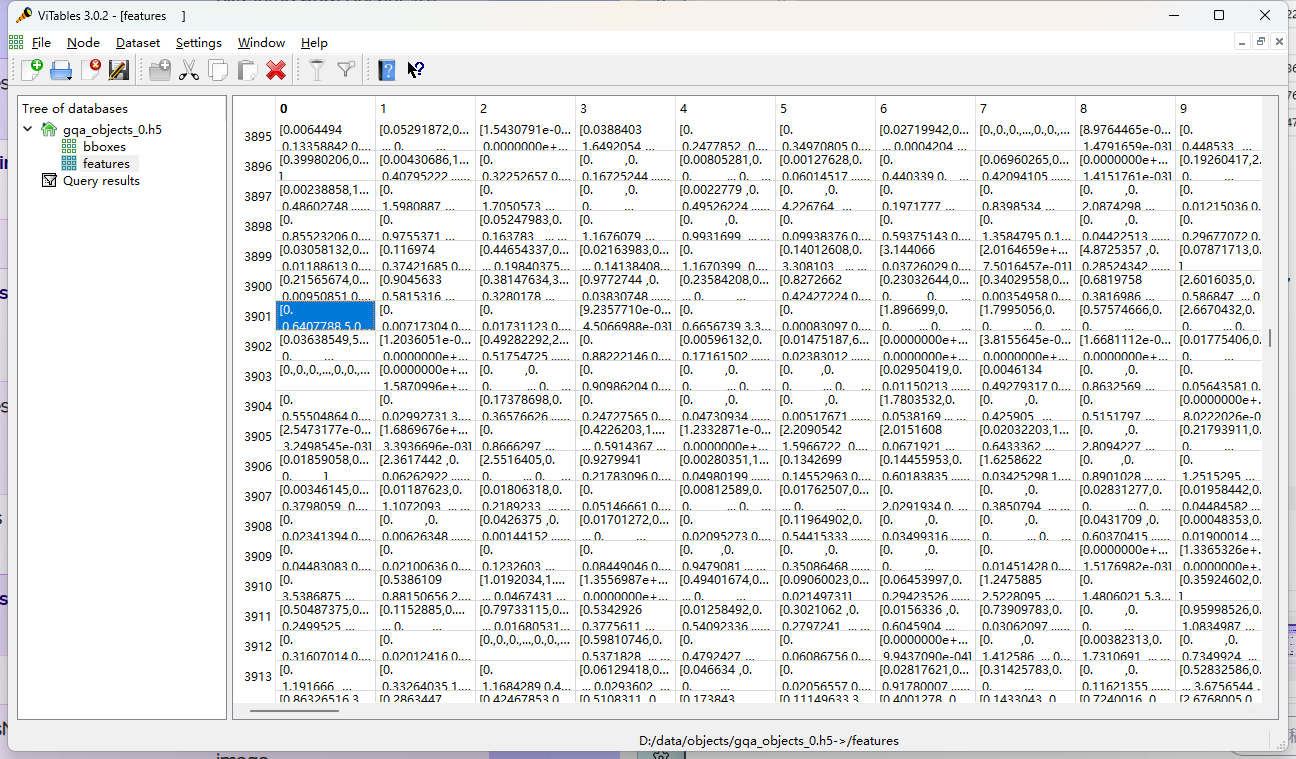
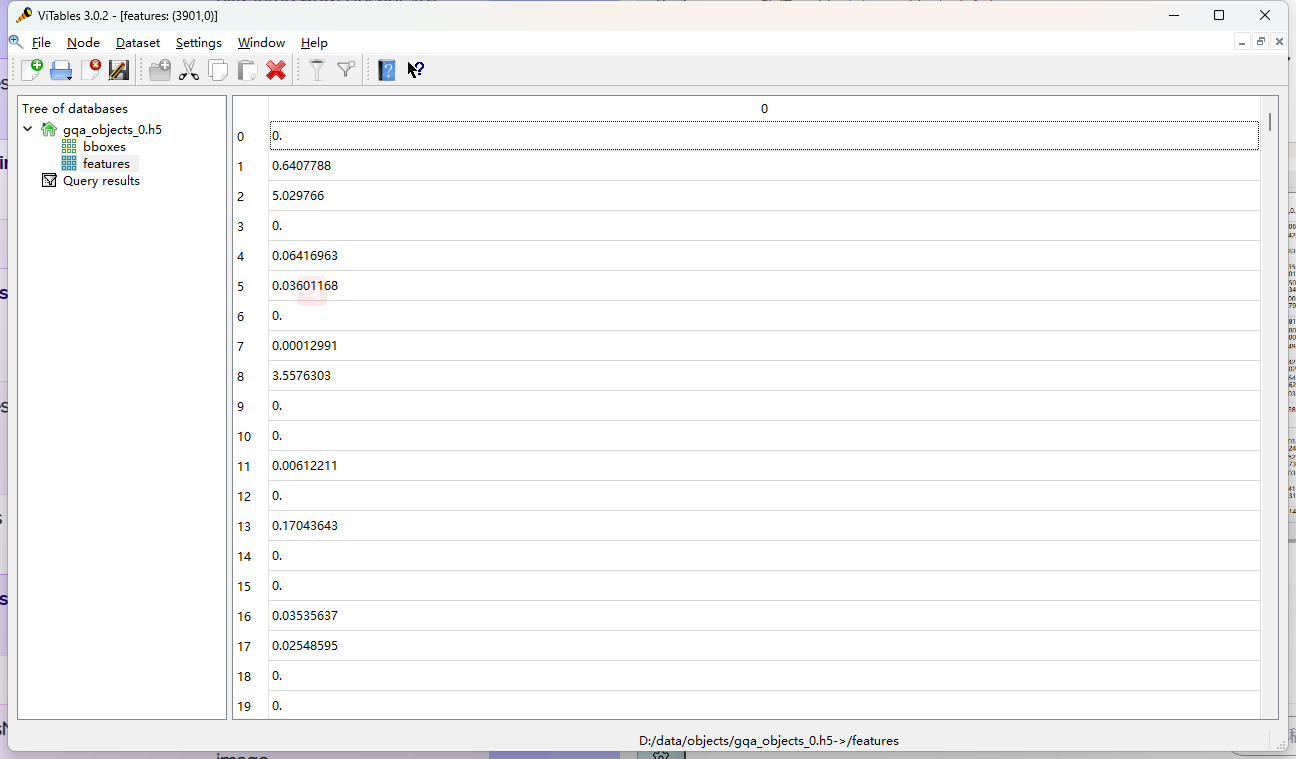
路径:objects/gqa_objects_info.json
"2266": { # 图片编号
"width": 800, # 图像的宽度
"objectsNum": 69, # 图片中的对象数
"idx": 3901, # h5文件中图像的索引
"height": 600, # 图像的高度
"file": 0 # 所在文件的索引
}
路径:objects/gqa_objects_0.h5
4.场景图
路径:sceneGraphs/train_sceneGraphs.json
描述:x,y是对象框左上顶点,w,h是对象框的宽和高
"2266": { # 图像编号
"width": 800, # 图像宽度
"objects": { # 从对象ID到其对象的字典
"4324200": { # 对象编号ID
"name": "person", # 对象名称
"h": 70, # 对象高度
"relations": [ # 对象(源)的所有传出关系(边)的列表
{
"object": "4324184", # 对象编号
"name": "to the left of" # 对象之间的关系
},
{"object": "4324192", "name": "to the left of"},
{"object": "4324213", "name": "to the left of"},
{"object": "4324196", "name": "to the left of"},
{"object": "4324219", "name": "to the left of"},
{"object": "4324190", "name": "to the right of"},
{"object": "4537542", "name": "to the left of"},
{"object": "4324189", "name": "to the right of"},
{"object": "4324188", "name": "to the left of"},
{"object": "4324191", "name": "to the right of"}
],
"w": 20, # 对象的宽度
"attributes": [], # 对象的属性列表
"y": 388, # 对象左上角的y坐标
"x": 85 # 对象左上角的x坐标
},
"4537543": {
"name": "crosswalk",
"h": 158,
"relations": [
{"object": "4537536", "name": "to the left of"}
],
"w": 453,
"attributes": [],
"y": 436,
&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 949
949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









