




 GQA是一个包含2200万个问题的数据集,专注于真实世界的视觉推理和组合式问答。它通过清理和强化场景图,使用问题引擎生成多样化的问题,旨在克服先前数据集的语言先验和缺乏组合语言的问题。数据集的构建包括规范化场景图、平衡答案分布和使用功能表示进行问题评估。新的评估指标关注一致性、有效性、合理性及答案分布,促进模型的视觉理解和推理能力的发展。
GQA是一个包含2200万个问题的数据集,专注于真实世界的视觉推理和组合式问答。它通过清理和强化场景图,使用问题引擎生成多样化的问题,旨在克服先前数据集的语言先验和缺乏组合语言的问题。数据集的构建包括规范化场景图、平衡答案分布和使用功能表示进行问题评估。新的评估指标关注一致性、有效性、合理性及答案分布,促进模型的视觉理解和推理能力的发展。
目录
数据集概述
GQA,这是一个用于真实世界视觉推理和组合问答的新数据集。2200万个不同的推理问题,所有这些问题都带有表示其语义的功能程序。答案分布受到严格控制。
11.3万张图像、2200万个问题,推理能力有对象和属性识别、传递关系跟踪、空间推理、逻辑推理和比较。
详述
出发点
先前数据集的缺点:
- 语言先验。也就是说答案分布中统计偏差和趋势,规避了对真实视觉场景理解的需求。
- 数据集中多数问题没有用到组合式的语言,从而仅仅测试了模型的物体识别能力,模型缺乏基于视觉的推理能力。
- 先前的数据集缺乏将问题中的关键词与图中的区域相联系的标记信息,使得研究者难以定位模型出错的原因。
具体步骤
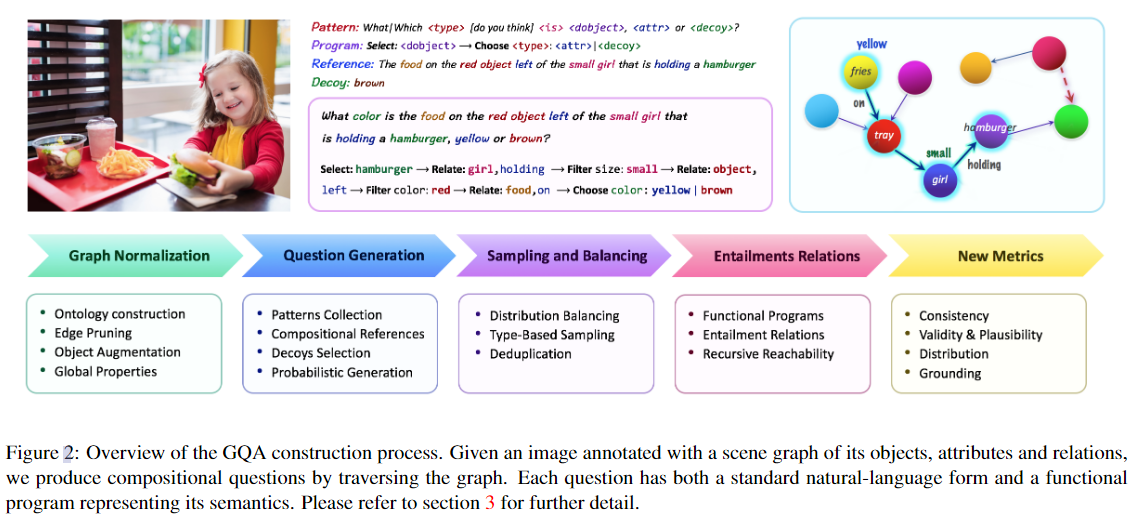
GQA 问题引擎和四步数据集构建过程:
(1)首先,我们彻底清理、规范化、巩固和增强与每个图像相关联的 Visual Genome 场景图 。
(2)然后,我们遍历图中的对象和关系,并将它们与从 VQA 2.0 [11] 和 sundry 概率语法规则中收集的语法模式进行匹配,以产生语义丰富多样的问题集。
(3)在第三阶段,我们使用潜在的语义形式来减少条件答案分布中的偏差从而产生一个平衡的数据集,该数据集对快捷方式和猜测更为稳健。
(4)最后,我们讨论了问题函数表示,并解释了如何使用它来计算问题之间的蕴涵,支持新的评估度量。
Scene Graph Normalization
场景图:作为图像的形式化表示,每
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 949
949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









