




 文章提出了GGE框架,针对VQA任务中的语言偏误进行分析,分解为分布误差和捷径误差。GGE通过连续集成有偏差的模型,提升鲁棒性,在VQA-CP上相比于UpDn基准,性能提升了17.34%。实验表明,该方法能更好地利用视觉信息,同时揭示了准确率高并不一定意味着有效利用视觉信息。
文章提出了GGE框架,针对VQA任务中的语言偏误进行分析,分解为分布误差和捷径误差。GGE通过连续集成有偏差的模型,提升鲁棒性,在VQA-CP上相比于UpDn基准,性能提升了17.34%。实验表明,该方法能更好地利用视觉信息,同时揭示了准确率高并不一定意味着有效利用视觉信息。
基于贪婪梯度集成的鲁棒视觉问答算法
一、创新点
(1)对VQA任务中的语言偏误进行分析,将语言偏误分解为分布误差和捷径误差。
分布误差:基于问题类型的训练集答案分布。
捷径误差:指特定问答对的语义相关性。
(2)提出了一种新的模型不可知的去偏框架:贪婪梯度集成 (Greedy Gradient Ensemble,GGE), 该框架连续集成有偏差的模型,实现鲁棒的VQA。
(3)在 VQA-CP 上,该方法更好地利用了视觉信息, 在没有额外标注的情况下,相对于简单的 UpDn 基准,获得了 17.34%的性能提升。
二、思想
利用深度学习中的过拟合现象。数据中有偏的部分被有偏的特征贪婪地过拟合,因此,可以用更理想的数据分布来学习预期的基础模型 , 并专注于有偏模型难以解决的例子。
三、前置实验
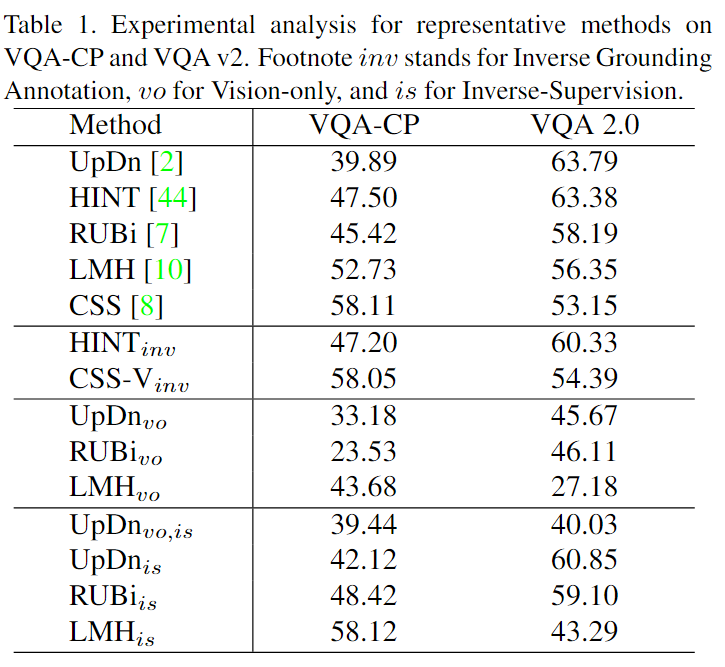
( · inv:改变人类标注的区域重要性分数
&nb
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









