



基于边缘计算的相机‐雷达融合方法
摘要
多接入边缘计算通过将计算和存储资源迁移到网络边缘,为车联网服务提供了低延迟、高性能的网络环境,并支持更多区域性车联万物服务的部署。本文提出了一种基于边缘计算的路侧摄像头与毫米波雷达的融合感知方法。首先,我们采用YOLOv3处理相机数据,使用DBSCAN聚类方法处理雷达数据,以获取检测的位置、速度和类别信息。接着,通过联合标定实现相机和雷达数据的空间同步,采用直接更新方法实现相机和雷达数据的时间同步。进一步地,利用穆恩克雷斯算法对相机和雷达的检测结果进行关联,并采用卡尔曼滤波对所提出融合方法的感知结果进行跟踪。最后,我们进行了仿真实验以评估所提出的方法。仿真结果验证了本算法的有效性。
关键词 -边缘计算;传感器融合;摄像头;雷达;路侧感知
一、INTRODUCTION
近年来,自动驾驶技术的发展使得车辆感知受到越来越多的关注。尽管大多数自动驾驶车辆依赖车载传感器进行环境感知,但在遇到超长距离、复杂交叉路口或车辆遮挡等情况时,检测能力inherently存在限制。因此,如何解决上述感知范围等限制并提升车辆感知能力,仍是车联网和车路协同系统领域的一个开放性问题。
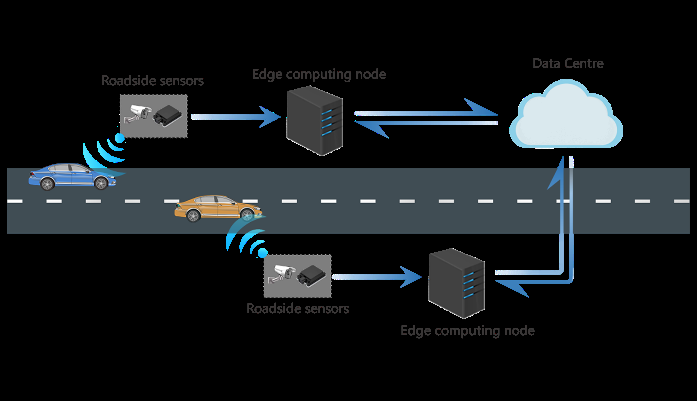
通常,用于自动驾驶或网联车辆的任何环境感知系统都应至少满足以下两个要求:1)系统能够实时处理大量传感器数据;2)系统能够将处理结果发送给周边的网联车辆。本文研究了一种基于边缘感知的替代方法,以解决车载感知问题。通过路侧设施传感器获取的多源信息,进行实时数据处理以分析交通状况,并可在路侧设施与车辆之间共享计算结果。此外,多接入边缘提供的强大计算和存储能力计算(MEC)显著降低了车辆与基础设施之间的传输延迟,并可实现多种附加服务。图1展示了基于MEC的整体边缘感知架构。
摄像头在目标分类和采购成本方面具有优势,而毫米波(mmWave)雷达在速度检测、纵向距离检测和稳定性方面具有优势。本文提出了一种基于MEC的利用路侧摄像头和毫米波雷达的融合感知方法。首先,采用YOLOv3对相机数据进行预处理,使用DBSCN聚类算法对雷达数据进行预处理。然后,通过相机和雷达的联合标定实现空间同步,并提出一种直接更新的时间同步方法。在完成前述时空同步的基础上进行数据融合。接着,分别利用穆恩克雷斯算法和卡尔曼滤波实现多目标的关联与跟踪。我们通过仿真验证了所提方法的性能,并确认该方法优于单一传感器感知。
本文其余部分组织如下:第二节介绍相关研究工作,第三节详细描述融合算法架构,该架构在第四节中进行了仿真和评估。最后,第五节对全文进行总结并得出结论。
II. 相关工作ELATED WORK
所选择的摄像头感知方法的类型对提出的融合算法的有效性和准确性有显著影响。环境感知旨在检测和分类交通场景中的目标物体,例如汽车、行人和骑自行车的人。传统的物体检测算法如SIFT、HOG、SURF使用滑动窗口不同大小的滑动窗口用于在图像上划定需要检测的区域并提取特征点,并使用机器学习方法对这些特征进行分类。近年来,计算机硬件的进步推动了深度学习(DL)方法在此领域的应用。像循环卷积神经网络(R‐CNN)算法系列这样的两步法,包括R‐CNN、Fast R‐CNN和 Faster R‐CNN,取得了良好的识别效果。相反,YOLO和单次多框检测器(SSD)等单步算法也实现了良好的物体检测结果。
目前,关于路侧传感器融合的研究较少,而车载融合方面的研究和应用则较多。以下是几项针对相机数据与毫米波雷达数据提出的不同融合方法的研究。
吴等人 [1] 提出了一种融合双目摄像头和毫米波雷达数据的方法。首先,他们根据双目深度信息拟合目标车辆的轮廓,并找到轮廓上的最近点。然后,通过融合雷达观测值与视觉最近点,得到融合后的最近点。接着,将拟合的轮廓平移到该融合最近点,以获得融合轮廓。最后,利用刚体约束跟踪融合轮廓,估计目标车辆的位置、尺寸、姿态和运动状态。
陈等人 [2] 提出了一种具有中心级架构的多传感器融合算法。首先,他们使用不同的感知传感器测量最近目标的距离。然后,利用多传感器信息融合算法检测整个区域内的最近目标。最后,使用卡尔曼滤波器对目标进行跟踪。与采用传感器级融合架构的方法相比,该方法能够提高目标检测概率。
余等人 [3] 提出了一种基于卡尔曼滤波和贝叶斯估计的融合方法。首先,他们使用SSD方法处理图像,并利用坐标变换矩阵统一摄像头和毫米波雷达的坐标系。接着,他们采用并行卡尔曼滤波器分别对雷达和摄像头的检测目标进行跟踪。最后,他们使用贝叶斯估计对雷达和摄像头的检测结果进行融合。实验表明,卡尔曼滤波器可用于降低测量中的噪声,融合算法能够提高估计精度。
诺比斯等人 [4] 提出了一种基于神经网络(NNs)的融合方法。他们设计了一个能够同时接收毫米波雷达和摄像头数据并输出处理结果的神经网络(NN)。他们使用 uScenes和模拟TUM数据集来评估该神经网络(NN)的有效性,实验结果表明其网络具有良好的感知性能。
III. ALGORITHM ARCHITECTURE
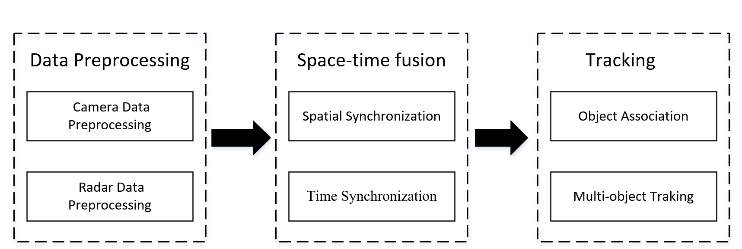
本节主要介绍了所提出的多传感器融合算法,该算法包括数据预处理、空间同步、时间同步和多目标跟踪,如图2所示。
A. 数据预处理
摄像头和雷达无法直接接收到有效检测,这证实了数据预处理的必要性。
1) 相机数据预处理
本文使用YOLOv3 [5] , ,这是一种极其快速且准确的深度学习方法,用于处理相机图像数据。此外,YOLOv3是一种实时目标检测系统,以30帧每秒的速度处理图像,在COCO测试开发集上使用Pascal Titan X实现了57.9%的mAP。
2) 雷达数据预处理
一些内置算法用于处理原始反射点以检测目标。然而,反射的检测点并不总是准确的,有时同一车辆上会出现多次检测。因此,需要一种聚类方法来进一步处理反射结果。本文采用DBSCAN聚类方法 [6] 处理雷达检测。该方法无需预先知道处理后聚类的最终数量和形状,并且能够同时识别噪声点。但对于位于聚类边界处的样本,其归属可能会根据哪个聚类先被检测到而发生波动。
B. 空间同步
由于不同位置的多种传感器获取多源信息,时空数据同步是传感器融合的前提。相机和雷达数据的空间同步通过联合标定实现。然而,摄像头和雷达必须预先分别进行标定。

| 相机标定 | 相机标定 | 相机标定 | 相机标定 | 相机标定 | 相机标定 | 相机标定 | 相机标定 | 相机标定 | 相机标定 | 雷达标定 | 雷达标定 | 雷达标定 | 雷达标定 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 姿态角 | 姿态角 | |||||||||||||
| 坐标 变换 | 坐标 变换 | 畸变 校正 | 姿态角 | 姿态角 | ||||||||||
| 坐标 变换 | 坐标 变换 | 畸变 校正 | ||||||||||||
| 刚体变换 | 刚体变换 |
径向畸变
切向畸变 |
径向畸变
切向畸变 | |||||||||||
| 世界坐标系 | 刚体变换 | 刚体变换 |
径向畸变
切向畸变 |
径向畸变
切向畸变 | ||||||||||
| 世界坐标系 | 刚体变换 | 刚体变换 |
径向畸变
切向畸变 |
径向畸变
切向畸变 | 雷达坐标系 | 雷达坐标系 | ||||||||
| 刚体变换 | 刚体变换 |
径向畸变
切向畸变 |
径向畸变
切向畸变 | 雷达坐标系 | 雷达坐标系 | |||||||||
|
径向畸变
切向畸变 |
径向畸变
切向畸变 | 雷达坐标系 | 雷达坐标系 | |||||||||||
|
径向畸变
切向畸变 |
径向畸变
切向畸变 | 雷达坐标系 | 雷达坐标系 | |||||||||||
| 相机坐标系 | 相机坐标系 | 透视投影 | 透视投影 |
径向畸变
切向畸变 |
径向畸变
切向畸变 | 雷达坐标系 | 雷达坐标系 | |||||||
| 透视投影 | 透视投影 |
径向畸变
切向畸变 |
径向畸变
切向畸变 | 雷达坐标系 | 雷达坐标系 | |||||||||
|
径向畸变
切向畸变 |
径向畸变
切向畸变 | 雷达坐标系 | 雷达坐标系 | |||||||||||
|
径向畸变
切向畸变 |
径向畸变
切向畸变 | 雷达坐标系 | 雷达坐标系 | |||||||||||
| 图像坐标系 | 图像坐标系 | 像素化 | 像素化 |
径向畸变
切向畸变 |
径向畸变
切向畸变 | 雷达坐标系 | 雷达坐标系 | |||||||
| 像素化 | 像素化 |
径向畸变
切向畸变 |
径向畸变
切向畸变 | 雷达坐标系 | 雷达坐标系 | |||||||||
|
径向畸变
切向畸变 |
径向畸变
切向畸变 | 雷达坐标系 | 雷达坐标系 | |||||||||||
|
径向畸变
切向畸变 |
径向畸变
切向畸变 | 雷达坐标系 | 雷达坐标系 | |||||||||||
| 像素坐标系 | 像素坐标系 |
径向畸变
切向畸变 |
径向畸变
切向畸变 | 雷达坐标系 | 雷达坐标系 | |||||||||
|
径向畸变
切向畸变 |
径向畸变
切向畸变 | 雷达坐标系 | 雷达坐标系 | |||||||||||
| 相机和雷达联合标定 | 相机和雷达联合标定 | 相机和雷达联合标定 | 相机和雷达联合标定 | 相机和雷达联合标定 | 相机和雷达联合标定 | 相机和雷达联合标定 | 相机和雷达联合标定 | 相机和雷达联合标定 | 相机和雷达联合标定 | 相机和雷达联合标定 | 相机和雷达联合标定 | 相机和雷达联合标定 | 相机和雷达联合标定 |
摄像头标定包括坐标变换和畸变校正,具体步骤如图3所示。坐标变换主要涉及四个坐标系:世界坐标系、相机坐标系、图像坐标系和像素坐标系。畸变校正是由镜头本身或安装误差引起的,包括径向畸变和切向畸变。目前采用棋盘格标定法 [7] 完成摄像头标定。雷达标定主要通过基于预期位置和角度的精确安装来实现。
相机与雷达联合标定的目的是将这两个传感器的测量值转换到同一坐标系中。本文中,将雷达坐标系中的测量值转换到相机坐标系中。对于三维到三维的转换,我们使雷达平行于地面放置,从而使得雷达的检测范围与摄像头处于同一水平面,不受姿态角的影响。
C. 时间同步
由于雷达和摄像头的采样频率不同,在空间同步之后需要进行时间同步,以提高每帧目标定位的准确性以及不同传感器数据的综合利用率。本文提出了一种多线程时间同步方法,包括雷达线程、相机线程和融合线程,如图4所示。
雷达线程和相机线程分别用于以不同的采样频率从雷达和摄像头收集数据,具体频率取决于传感器。实时获取的数据将被发送到包含YOLOv3和DBSCAN等算法的预处理模块。最终,得到的预处理结果将存储在缓冲区中,并通过直接更新方法进行实时更新。缓冲区中仅存储一帧有效雷达检测数据。如果摄像头和雷达已检测并聚类出新的目标,缓冲区中的数据将立即被替换。
融合线程由三部分组成,包括判断模块、检测分配和测量融合。判断模块由时间控制,且融合间隔必须长于摄像头和雷达的采样间隔。当系统时间达到融合时刻时,将从雷达和摄像头的缓冲区中提取数据以进行后续处理。检测分配是一种目标关联技术,用于配对摄像头和雷达的检测,以确保在存在多个目标的情况下两者能够相互匹配。可以使用分配算法或聚类算法来进行检测分配,此处选用穆恩克雷斯算法。对于测量融合,最终检测的速度采用雷达检测到的速度;最终检测的目标类型采用摄像头识别的目标类型;最终的位置则取摄像头检测和雷达检测的平均位置。

D. 多目标关联与跟踪
使用雷达和摄像头进行多目标跟踪时需要关注以下几点:1)目标关联——雷达检测应与摄像头检测相关联,当前融合检测必须与已有轨迹相关联;2)跟踪——应使用合适的滤波器进行跟踪;3)轨迹管理——应维护一个跟踪目标库,并定义包括初始化、更新和删除在内的跟踪过程。整个多目标跟踪过程如图5所示。
1) 目标关联
使用穆恩克雷斯算法 [8] 进行目标关联,旨在解决指派问题。该算法中分配的数量与任务的数量需保持一一对应关系。假设有 M 个目标需要与 N 个目标进行匹配,则将使用穆恩克雷斯算法构建一个方阵,并采用传统的匈牙利算法获得匹配结果。
为了关联雷达与摄像头检测,结果可以分为三类:已分配的检测、未分配的雷达检测和未分配的摄像头检测。测量融合直接在已分配的检测上进行。未分配的摄像头检测被视为有效检测。考虑到毫米波雷达的高漏检率,未分配的雷达检测将被删除。
类似地,对于多目标跟踪,检测结果可以分为三类:未分配的检测、未分配的轨迹和已分配的轨迹。在后续处理中,未分配的检测用于在目标库中生成新轨迹;已分配的轨迹用于更新已有轨迹;未分配的轨迹用于删除已有轨迹。
IV. SIMULATION EXPERIMENT
A. 仿真环境
使用自动驾驶工具箱–MATLAB对提出的融合算法进行评估,该工具箱提供以下功能:1)用于构建特定道路场景的道路仿真工具;2)用于模拟道路上的车辆,并设置每辆车辆在特定时间的精确轨迹的车辆仿真工具;3)可模拟毫米波雷达和摄像头感知结果的传感器仿真工具。
设置一个无渠化和信号灯的道路交叉口作为仿真场景,用于评估所提出的融合感知方法。该场景由东西方向和南北方向的两条四车道双向道路组成,每条车道宽 3.6米。此场景的仿真步长为0.01秒。一辆车辆以15 m/s的恒定速度在纵向行驶,车辆中心位于水平坐标 1.8米处。
B. 评价指标
使用三个指标,包括平均残差(MR)、方差和残差平方和(RSS),来评估所提算法的有效性。在以下公式中,$x_{\text{actual},i}$ 表示车辆的实际位置,$x_{\text{estimated},i}$ 表示通过融合感知得到的车辆估计位置,$n$ 表示在周期内车辆位置被估计的总次数。
均值残差 计算了车辆感知结果与实际运行轨迹之间的平均误差,MR 公式为:
$$
MR = \frac{\sum_{i=1}^{n} (x_{\text{actual},i} - x_{\text{estimated},i})}{n}
\quad (1)
$$
方差 反映了不同检测方法获得的运动的稳定性。公式如下:
$$
\text{Variance} = \frac{\sum_{i=1}^{n} (x_i - \bar{x})^2}{n}
\quad (2)
$$
残差平方和 表示在每个采样点处理想值与估计值之间的误差平方和,用于评估。公式如下:
$$
RSS = \sum_{i=1}^{n} (x_{\text{actual},i} - x_{\text{estimated},i})^2
\quad (3)
$$
C. 传感器参数设置
在交叉口南向车道中心、距地面0.2 m处安装了一部毫米波雷达。其安装姿态角与地面平行,旨在避免雷达与检测平面之间的角度差异。在同一位置、距地面3 m处安装了一个摄像头,以获得更好的感知视野。
毫米波雷达的设置参考了大陆雷达ARS 404‐21 Premium的参数。雷达的远距离检测距离为170米,近距离检测距离为70米。远距离分辨率为0.75米,近距离分辨率为0.4米。远距离检测方位角为(−9°, +9°),测量间隔为50毫秒。
对于仿真相机参数,默认检测角度设置为(−45°, 45°),最大前向检测长度为150米。摄像头目标识别精度取决于所使用的图像处理算法,识别效果主要由边界框精度和误检数量决定。因此,在本仿真中,边界框精度设置为20,误检数量设置为0.5。
D. 实验结果
仿真结束后,实现了目标跟踪,实时车辆的轨迹以及摄像头、雷达和提出的融合算法的感知结果如图6所示,将从纵向和横向进行分析,评价指标如表1所示。

| 方法 | 平均残差 (MR) | 方差 | 残差平方和 (RSS) |
|---|---|---|---|
| 雷达 | 0.45 | 0.89 | 180.34 |
| 相机 | 0.38 | 0.76 | 165.21 |
| 融合算法 | 0.21 | 0.32 | 226.68 |
表1. 评价指标
1) 纵向分析
图7展示了摄像头、雷达系统和提出的融合算法在车辆纵向方向上的感知结果,以及目标跟踪的实现情况。由于摄像头、雷达和提出的融合算法在感知结果上没有明显差异,因此绘制了残差感知图,如图8所示。
根据摄像头、雷达和提出的融合算法感知到的纵向距离的方差,我们发现雷达获得的检测结果不够稳定,摄像头获得的检测结果同样不稳定。在应用我们提出的算法后,纵向方向上的感知稳定性得到了显著提升。
在应用提出的融合算法后,RSS值增加至226.68,根据纵向方向的残差分析,该现象的原因可能是当车辆接近路侧感知单元时,融合算法的感知位置从车辆中心移动到了车辆前方。

2) 横向分析
图9展示了摄像头、雷达以及融合算法对车辆在横向方向的感知结果,图10显示了摄像头、雷达和融合算法的残差感知,从中我们可以定位到车辆接近路侧感知单元的过程。根据横向残差,当车辆接近时,融合结果更接近真实值,同时摄像头和雷达产生的噪声也大幅降低。
在这种情况下,车辆将被视为一个矩形而非一个点。从这一角度来看,可以发现车辆的所有横向定位点均位于车辆宽度范围内,这意味着提出的融合算法在水平方向上实现了良好的感知结果。


V. CONCLUSION
在本研究中,我们提出了一种用于路侧相机和雷达的融合感知算法,作为边缘计算的应用,并通过仿真对融合算法进行了评估。仿真结果表明,该算法能够有效提高相机和雷达检测在纵向和横向上的稳定性。在未来工作中,我们将把融合算法部署在路侧MEC设备上,并根据测试结果进行进一步改进。


















 51
51

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









