 视觉-雷达融合在BEV目标检测中的进展与趋势
视觉-雷达融合在BEV目标检测中的进展与趋势





 文章探讨了传感器融合在自主机器人感知系统中的重要性,尤其是相机和雷达的互补性。介绍了BEV目标检测的任务、传感器选择、数据集和评估指标,并详细分析了早期融合、深度融合和后期融合的传感器融合技术。文章还指出,基于transformer的方法在视觉-雷达融合中表现出色,提出了未来可能的发展方向,包括transformer的扩展和协作感知。
文章探讨了传感器融合在自主机器人感知系统中的重要性,尤其是相机和雷达的互补性。介绍了BEV目标检测的任务、传感器选择、数据集和评估指标,并详细分析了早期融合、深度融合和后期融合的传感器融合技术。文章还指出,基于transformer的方法在视觉-雷达融合中表现出色,提出了未来可能的发展方向,包括transformer的扩展和协作感知。
后台回复【多传感器融合综述】获取图像/激光雷达/毫米波雷达融合综述等干货资料!
由于构建自主机器人感知系统的需求,传感器融合能够充分利用跨模态信息已引起研究人员和工程师的大量关注。然而,为了大规模地构建机器人平台,需要强调自主机器人平台带来的成本。camera和radar本身就包含互补的感知信息,有潜力大规模开发自主机器人平台。然而,与LiDAR与视觉融合相比,雷达与视觉融合的工作有限。本文通过对BEV目标检测系统的视觉毫米波雷打融合方法的调查来解决这一差距。首先将介绍背景信息,即目标检测任务、传感器选择、传感器设置、基准数据集和机器人感知系统的评估指标。随后,将介绍每种模态(相机和radar)数据表示,然后详细介绍基于子组的传感器融合技术,即早期融合、深度融合和后期融合,以便于理解每种方法的优缺点。最后,我们提出了视觉radar融合的未来可能趋势,以启发未来的研究。
定期更新的内容可在以下链接找到:https://github.com/ApoorvRoboticist/Vision-RADARFusion-BEV-Survey
领域应用背景
相机在BEV预测中的泛化能力不太好,因为它们接收的输入受到2D像素的限制,然而却包含非常丰富的语义和边界信息。radar的数据已经包括输入点云中的3D数据和速度数据,但缺乏密集的语义信息。由于这些原因,相机-radar传感器组合可以很好地一起工作,但是这些传感器接收的数据需要映射到单个坐标系,接收到的输入数据如图1所示: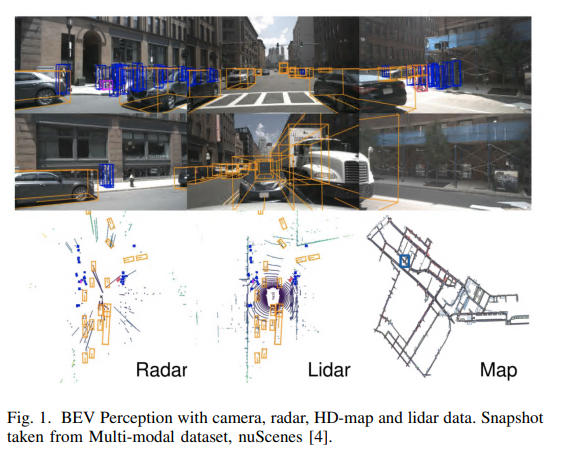
之前的工作只考虑了视觉和激光雷达方面,[7] 和[8]已经涵盖了视觉和radar,但他们对现代基于深度学习的技术的研究还不够深入,而这些技术正成为当今趋势。本文计划通过涵盖BEV背后的基础知识来解决这一差距,然后深入研究现代视觉radar融合技术,从而更加关注基于transformer的方法。本文的主要组织结构如下:首先在第二节中查看了解机器人BEV感知所需的背景信息,即关于目标检测任务、传感器选择、基准数据集、评估指标等信息。然后,将在第三节中介绍相机和radar的输入数据格式。在第四节中,将详细分析相机和radar融合方法所涉及的技术。此外,还将对它们进行分组,以便能够轻松地理解。稍后,在第五节中,将展示所讨论的方法如何评估相机radar基准nuScenes。然后在第六节中,将对当前的研究趋势进行可能的扩展,这可能会启发未来的研究。最后,在第七节中,将总结整体的研究结果!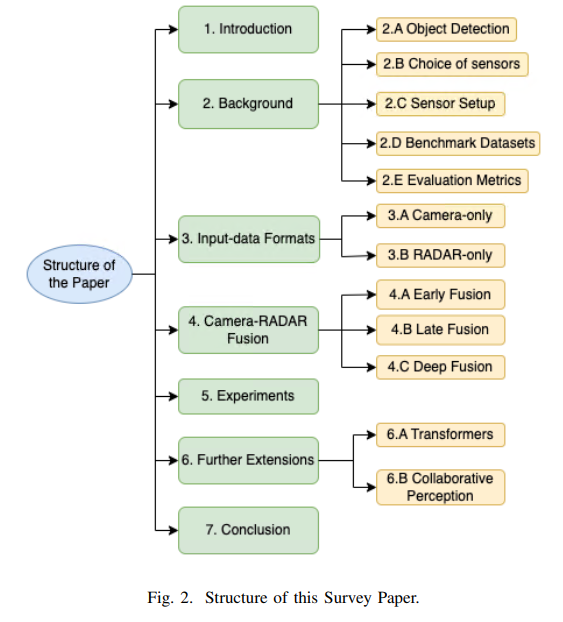
3D目标检测是机器人/自动驾驶平台的一项重要任务。目标检测是两个基本计算机视觉问题的结合,即分类和定位,其目的是检测预定义类的所有实例,并使用轴对齐的框在图像/BEV空间中提供其定位。它通常被视为一个利用大量标记图像的监督学习问题,目标检测任务中的几个关键挑战包括:
box BEV表示:相机图像在透视图中,但下游自治任务在鸟瞰图(BEV)中运行。因此,需要一种将透
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 857
857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









