




 本文探讨了数据仓库和大数据平台的发展,从湖仓分体到湖仓一体的演进。ANCHOR 标准定义了湖仓一体的六大特性:实时性、云原生、数据一致性、高并发、一份数据和多类型数据支持。文中通过建设银行和 Capital One 的案例,阐述了湖仓一体对企业在实时分析、数据一致性、成本效益和业务价值方面的提升。同时,文章介绍了 Lambda、Kappa 和新兴的 Omega 架构在实时处理中的角色和局限性,展示了 Omega 如何解决实时分析的全部需求,实现湖仓一体的全实时架构。
本文探讨了数据仓库和大数据平台的发展,从湖仓分体到湖仓一体的演进。ANCHOR 标准定义了湖仓一体的六大特性:实时性、云原生、数据一致性、高并发、一份数据和多类型数据支持。文中通过建设银行和 Capital One 的案例,阐述了湖仓一体对企业在实时分析、数据一致性、成本效益和业务价值方面的提升。同时,文章介绍了 Lambda、Kappa 和新兴的 Omega 架构在实时处理中的角色和局限性,展示了 Omega 如何解决实时分析的全部需求,实现湖仓一体的全实时架构。

引言:随着企业数字化转型进入深水区,越来越多的企业视湖仓一体为数字变革的重要契机,湖仓一体也受到了前所未有的关注。当然,关注度越高市场上的声音也就越嘈杂,很多过时甚至错误的湖仓一体技术和理念不胫而走,很有可能将转型中的企业引入歧途,推高数据孤岛,造成资源浪费甚至错过数字化转型的战略时机。
伪湖仓一体自然是我们不愿看到的,而想要理解什么是真正的湖仓一体,则需要对技术背景及其演进历程有清晰的认知,当然这对多数读者都很挑战,因此笔者尝试从技术背景和发展脉络的角度给出湖仓一体的终极答案。
一、从数据仓库说起
1990 年,数据仓库之父比尔·恩门 (Bill Inmon) 率先提出了数据仓库的概念,其专著《建立数据仓库》指出数据仓库为分析决策服务,是一个面向主题的、集成的、非易失的且随时间变化的数据集合。2000 年开始,数据仓库在国内得到了广泛的推广,电信和银行业最早建立起数据仓库。
比尔·恩门 (Bill Inmon)
1、发展背景
业务增长源源不断的产生数据,这些数据存储在业务数据库中,也就是我们常说的 OLTP 数据库。当积压的历史数据越来越多,对业务数据库产生负载,导致业务系统运行速度降低;同时,在日益激烈的市场竞争中,企业需要对积累的数据进行分析,获取更加准确的决策信息来完成市场推广、运营管理等工作。由此,提出将历史数据存储到数据仓库 (OLAP),改善业务系统数据库性能的同时,可以更专注的提升数据分析效率,辅助企业决策。
2、技术演进
传统关系型数据库的技术架构,尤其是 OLTP 数据库无法有效满足大量历史数据的存储、查阅以及数据分析需求。随着数据仓库技术进一步发展,分布式数据库产生,出现了以 Teradata 为代表的MPP 一体机 数据库产品,此后又出现了 Greenplum 和 Vertica 等基于标准 x86 服务器的 MPP 数据库,他们采用无共享架构 (Share-nothing) 以支持数据仓库的建设。这个阶段主要建设 OLAP 类型的系统,如数据仓库、ODS、数据集市、应用数据库、历史数据库以及报表、分析报告、数据挖掘、客户标签画像等。
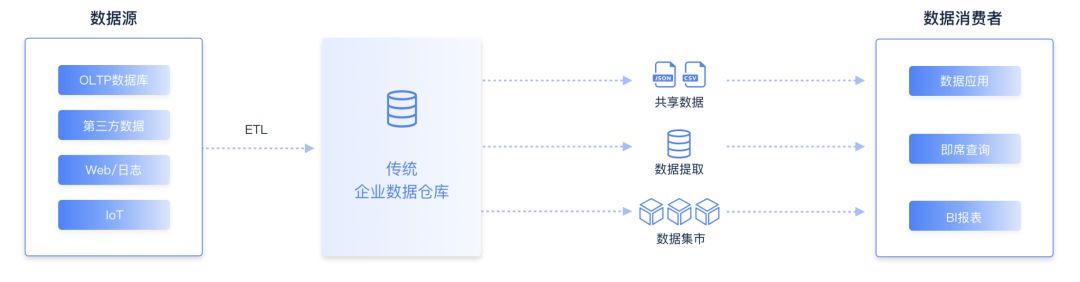
OLAP 系统建设
在数据模型方面,以银行业为例,很多银行建立主题模型都选用 Teradata FS-LDM (Financial Services Logical Data Model) 和 IBM BDWM (Banking Data Warehouse Model)。不同行业有不同的数据模型。
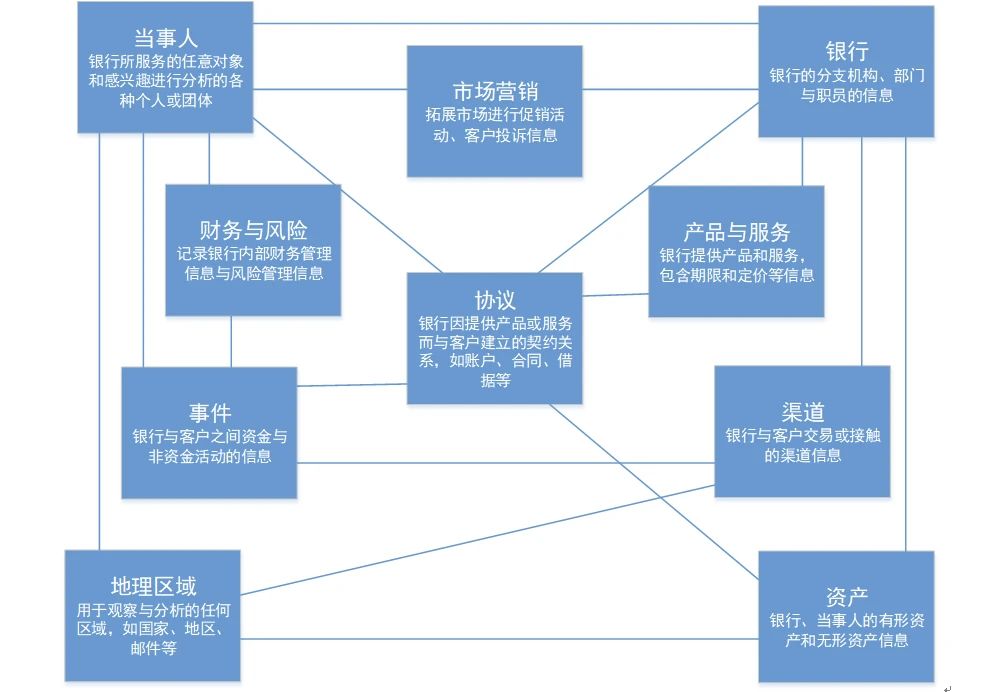
Teradata FS-LDM 图例
3、阶段特点
该阶段早期,不少企业直接采用了共享存储架构的 Oracle 和 Db2,也有不少客户采用了 MPP 无共享 Share-nothing 架构的产品。早期 MPP 采用软硬一体的专有服务器和昂贵的存储,比如 Teradata,后期 MPP 大多采用标准 x86 服务器,架构依然是无共享 Share-nothing 架构,数据以结构化为主,集群的扩展能力有限。基于共享存储架构的数据库集群规模通常在几十节点,MPP 基本在百节点级别,支持数据体量有限,很难超过 PB 级别。
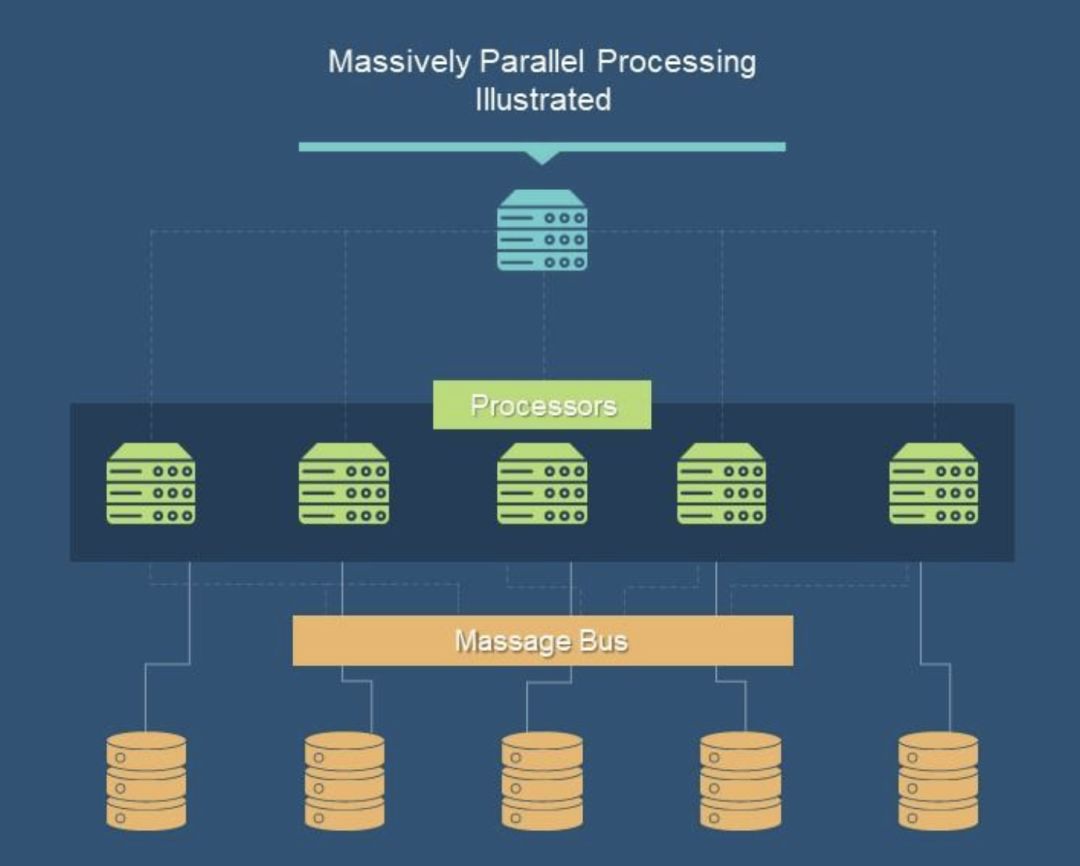
典型 MPP 架构
二、大数据平台逐渐流行
时间来到 2012 年,国内一些技术发展较快的行业,如电信和头部银行(国有大行和股份制银行)基本都完成了数据仓库的建设。彼时 Hadoop 技术快速普及,大数据平台开始受到关注,尤其受互联网行业迅速发展的影响,大数据平台迎来历史的高光时刻。

Hadoop 生态
1、发展背景
互联网以及很多行业线上业务的快速发展,让数据体量以前所未有的速度增长,企业对海量数据的处理有了更高要求,如非结构化数据处理、快速批处理、实时数据处理、全量数据挖掘。由于传统数据仓库侧重结构化数据,建模路径较长,面对大规模数据处理力有未逮,而企业亟需提升大数据处理时效,以更经济的方式发掘数据价值。
2、技术演进
企业开始使用 Hadoop 分布式大数据计算和存储,同时 Hive,Spark、Impala 等数据处理技术进一步发展,Spark Streaming、Flink 等实时数据处理技术也让大数据平台具备了实时数据处理能力。Hadoop 一般使用 HDFS 存储数据,其计算引擎使用 MapReduce,Spark 等实现。虽然 Hadoop 逻辑上实现了计算和存储分离,但是其物理部署架构依然强调在每一个节点同时部署计算节点和存储节点,通过将计算置于存储所在的位置,利用数据本地性提升计算性能。
3、阶段特点
Hadoop 得到了广泛的认可,大数据热让人们对 Hadoop 抱有更高的期待,认为既然 Hadoop 平台能解决很多数据处理和分析问题,自然可以替代传统的数据仓库。但是,随着 Hadoop 大数据平台建设逐步推广,企业尝试将 Hadoop 用于一些非核心场景(如银行的三方数据平台)之后,发现 Hadoop 不仅性能和并发支持有限,而且事务支持弱,交付、运维成本高,企业最终意识到基于 Hadoop 的大数据平台终究无法替代核心数仓。投身 Hadoop 技术的两家头部企业 Cloudera 和 Hortonworks 经历了上市的高光时刻,最终在合并后退市了。
三、无奈之举,湖仓分体
1、发展背景
无法替代数据仓库,但是 Hadoop 逐渐形成了自身特殊的定位——数据湖。Gartner 曾指出,数据湖存储着各种数据资产,这些资产使用与源数据类似或者相同的格式。数据湖对全量的、各种类型的数据进行存储和挖掘,为数据科学家提供基于任意原始数据开发应用的敏捷性,而不必局限于数仓的数据,这是数据湖优于传统数仓之处。但数据湖却始终无法满足用户在性能、事务等方面的要求,所以企业的 IT 建设通常先让所有数据入湖,便于自由灵活的数据分析和探索,在某个分析逐步成熟时,将其转移到数据仓库,这样就形成了数据湖和数据仓库互补的方式(如下图所示)。
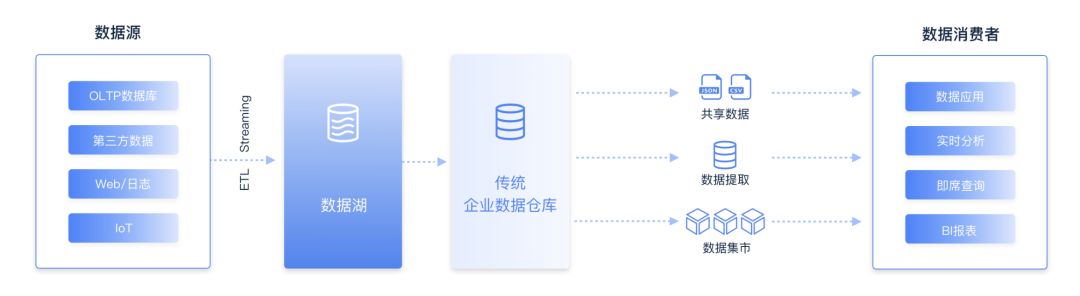
数据湖+数据仓库 互补
除了技术特性互补,数据湖和数据仓库在项目投入成本方面也有互补性。由于湖和仓的架构不同,长期项目投入的“性价比”差异很大。数据湖起步成本低,但随着数据体量增大,项目成本快速上升;数据仓库则恰恰相反,前期建设投入大,后期管理成本较低。

湖与仓项目长期成本的差异曲线
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









