




 集成学习(Ensemble Learning)通过结合多个模型的预测以提高预测性能,尤其适用于追求最佳性能的项目。Bagging是其一种方法,通过有放回抽样创建多样化的弱分类器。随机森林是Bagging的变种,通过随机选择特征和数据来构建多棵树,以降低方差。随机森林有多种变种,如Extra Trees和Isolation Forest,分别用于分类和异常检测。随机森林的优点包括并行训练、高维度数据处理能力和特征重要性评估,但可能对噪声特征敏感并可能导致过拟合。
集成学习(Ensemble Learning)通过结合多个模型的预测以提高预测性能,尤其适用于追求最佳性能的项目。Bagging是其一种方法,通过有放回抽样创建多样化的弱分类器。随机森林是Bagging的变种,通过随机选择特征和数据来构建多棵树,以降低方差。随机森林有多种变种,如Extra Trees和Isolation Forest,分别用于分类和异常检测。随机森林的优点包括并行训练、高维度数据处理能力和特征重要性评估,但可能对噪声特征敏感并可能导致过拟合。
我们在生活中做出的许多决定都是基于其他人的意见,而通常情况下由一群人做出的决策比由该群体中的任何一个成员做出的决策会产生更好的结果,这被称为群体的智慧。集成学习(Ensemble Learning)类似于这种思想,集成学习结合了来自多个模型的预测,旨在比集成该学习器的任何成员表现得更好,从而提升预测性能(模型的准确率),预测性能也是许多分类和回归问题的最重要的关注点。
集成学习(Ensemble Learning)是将若干个弱分类器(也可以是回归器)组合从而产生一个新的分类器。(弱分类器是指分类准确率略好于随机猜想的分类器,即error rate < 0.5)。
集成机器学习涉及结合来自多个熟练模型的预测,该算法的成功在于保证弱分类器的多样性。而且集成不稳定的算法也能够得到一个比较明显的性能提升。集成学习是一种思想。当预测建模项目的最佳性能是最重要的结果时,集成学习方法很受欢迎,通常是首选技术。
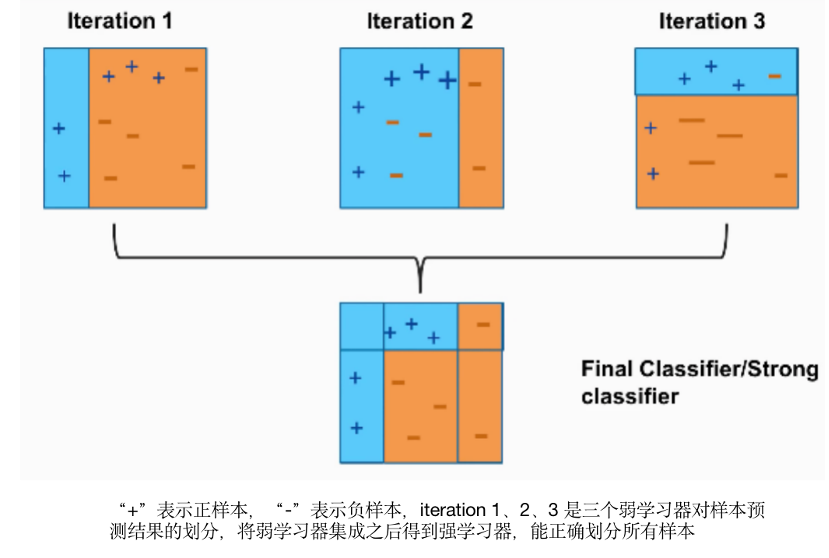
为什么要使用集成学习
(1) 性能更好:与任何单个模型的贡献相比,集成可以做出更好的预测并获得更好的性能;
(2) 鲁棒性更强:集成减少了预测和模型性能的传播或分散,平滑了模型的预期性能。
(3) 更加合理的边界:弱分类器间存在一定差异性,导致分类的边界不同。多个弱分类器合并后,就可以得到更加合理的边界,减少整体的错误率,实现更好的效果;
(4) 适应不同样本体量:对于样本的过大或者过小,可分别进行划分和有放回的操作产生不同的样本子集,再使用样本子集
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 1367
1367



 到【灌水乐园】发言
到【灌水乐园】发言







