




 本文详细介绍了如何使用MapReduce实现数字排序,包括MapReduce的运行流程、自定义MapReduceSort程序的规划、代码实现及遇到的问题和解决方案。通过实例展示了Map、Shuffle和Reduce阶段的关键步骤,帮助读者理解大数据环境下数据的排序过程。
本文详细介绍了如何使用MapReduce实现数字排序,包括MapReduce的运行流程、自定义MapReduceSort程序的规划、代码实现及遇到的问题和解决方案。通过实例展示了Map、Shuffle和Reduce阶段的关键步骤,帮助读者理解大数据环境下数据的排序过程。
目录
1. MapReduce 运行流程
MapReduce主要经过三个阶段:
① Map阶段
1)以<k1, v1>格式读取文本文件,其中k1为文本偏移量,通常定义为数字类型(如LongWritable),v2为文本,通常定义为Text类型
2)自定义语句,用于处理<k1, v1>及生成<k2, v2>
3)将2)中生成的<k2, v2>写入Context类的对象中
② Shuffle阶段
1)分区
2)排序
3)规约
4)分组
最后形成新的<k2, v2>并输出
③ Reduce阶段
1)以<k2, v2>形式读取数据
2)自定义语句,用于处理<k2, v2>及生成<k3, v3>
3)以<k3, v3>形式输出数据
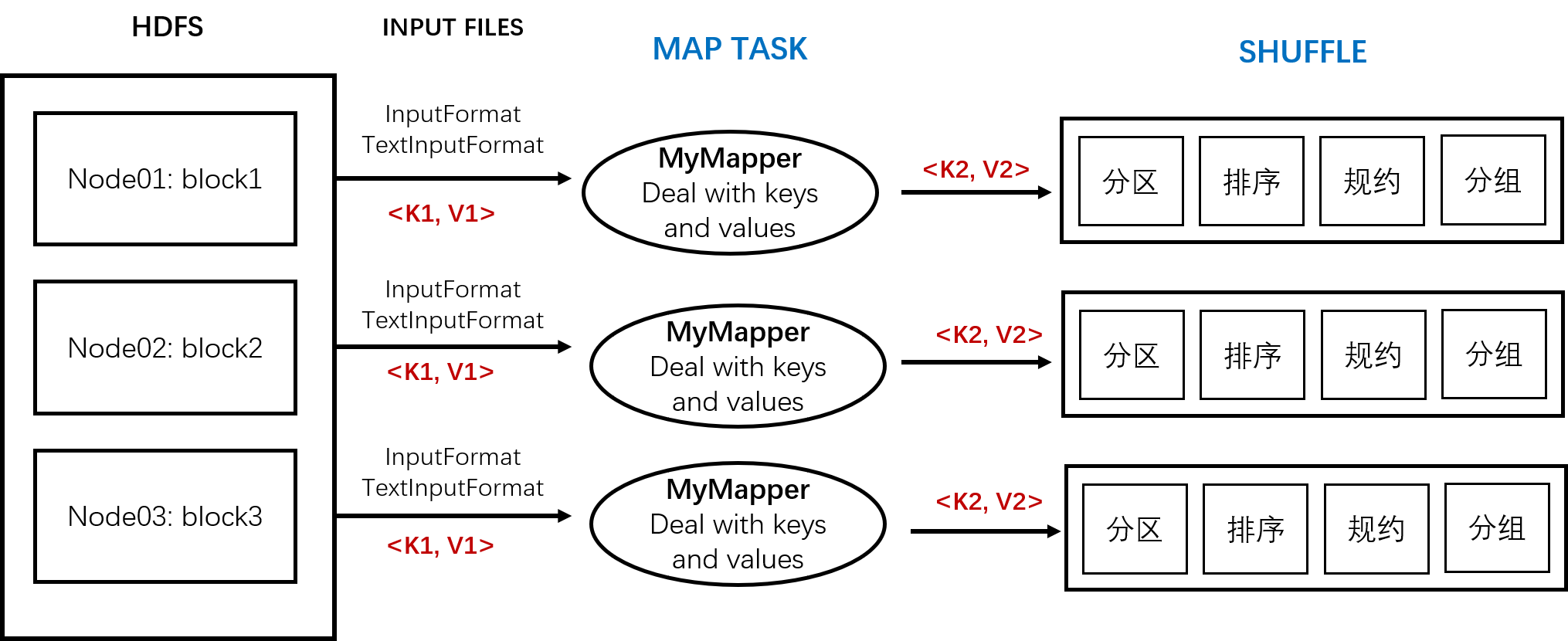

(图为自制,有参考视频内容)
2. 规划自定义的 MapReduceSort 程序
需求:
现有文件:
s1.txt:
35 12345 21 5 -8 365
s2.txt:
38 156 12 6 -2 -10
s3.txt:
45 2365 68 -15 -18 -30
运用MapReduce编写一个简单排序的程序,如果将上面三个文件作为输入,则排序后的输出结果如下所示:
1 -30
2 -18
3 -15
4 -10
5 -8
6 -2
7 5
8
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 897
897








 到【灌水乐园】发言
到【灌水乐园】发言







