




 Liuetal.sresearchproposesPVConvNet,amethodthataddressesLiDARpointcloudlimitationsbycombiningpixel-voxelsparseconvolutions,noise-resistantencoding,andaunifiedRoIpoolingstrategy.PVConvNetimproves3Ddetectionaccuracy,achieving86.92%mAPontheKITTItestset,outperformingexistingmultimodalmethods.
Liuetal.sresearchproposesPVConvNet,amethodthataddressesLiDARpointcloudlimitationsbycombiningpixel-voxelsparseconvolutions,noise-resistantencoding,andaunifiedRoIpoolingstrategy.PVConvNetimproves3Ddetectionaccuracy,achieving86.92%mAPontheKITTItestset,outperformingexistingmultimodalmethods.
Liu, H., Du, J., Zhang, Y., Zhang, H., & Zeng, J. (2024). PVConvNet: Pixel-Voxel Sparse Convolution for multimodal 3D object detection. Pattern Recognition, 149(110284), 110284. https://doi.org/10.1016/j.patcog.2024.110284
当前的仅使用激光雷达(LiDAR)的3D检测方法不可避免地受到点云稀疏性和语义信息不足的影响。为了缓解这一困难,最近的提案通过深度补全使LiDAR点云变得更密集,然后在数据级或结果级进行与图像像素的特征融合。然而,这些方法通常在融合效果和对图像信息在体素特征级融合方面的不充分利用方面存在问题。与此同时,由于深度补全的不准确性引入的噪声显著降低了检测的准确性。在本文中,我们提出了PVConvNet,这是一个用于多模态特征融合的统一框架,巧妙地结合了LiDAR点云、虚拟点和图像像素。首先,我们开发了一种高效的像素-体素稀疏卷积(PVConv),用于对点云和图像进行体素级特征融合。其次,我们设计了一种抗噪稀疏扩张卷积(NRDConv),用于对虚拟点的体素特征进行编码,有效降低噪声的影响。最后,我们提出了一种统一的RoI池化策略,即多模态体素-RoI池化,以提高提案细化的准确性。我们在广泛使用的KITTI数据集和更具挑战性的nuScenes数据集上评估了PVConvNet。实验结果显示,我们的方法在KITTI测试集上实现了86.92%的中等3D平均精度,优于现有的基于多模态的方法。
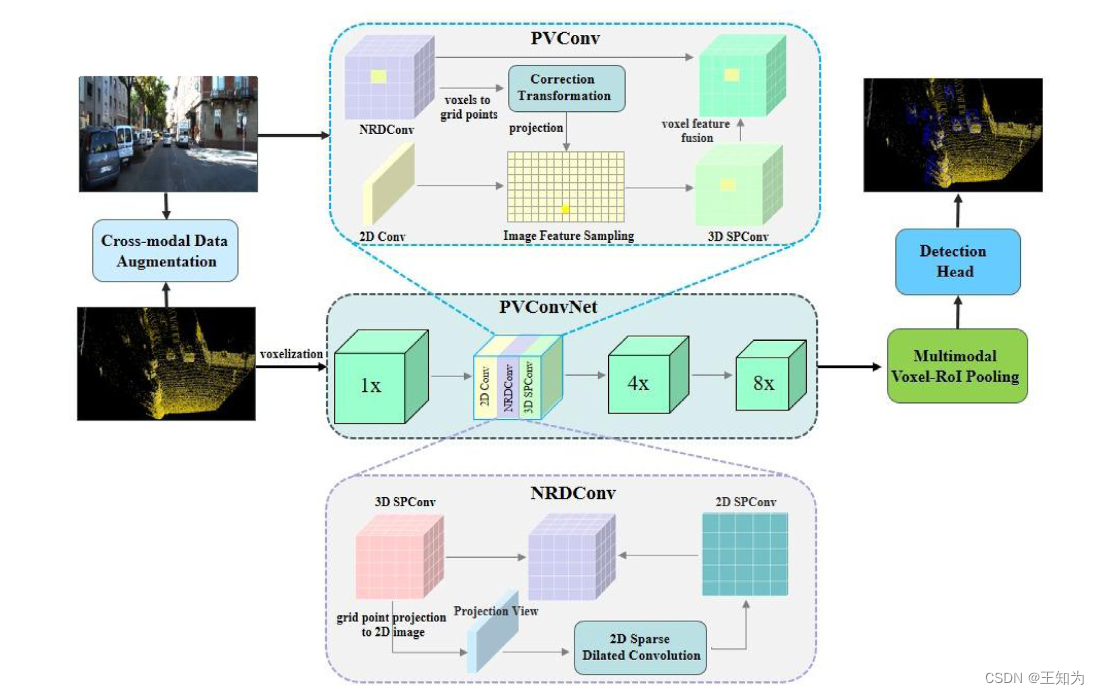
图1. 基于像素-体素稀疏卷积的多模态3D目标检测的统一框架示意图。PVConvNet通过四个堆叠的下采样PVConv执行图像和点云的主干特征提取,并生成用于3D检测的3D提案。PVConv对图像和点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1285
1285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











