









 华东师范大学的研究提出了一种无监督事件检测模型,利用有序对比学习和prompt-based预测,解决了预定义事件类型限制的问题。模型通过对比样本生成器、事件编码器和有序对比损失函数来处理可见和不可见事件类型,实验在ACE2005和FewShotED数据集上展示了其有效性。
华东师范大学的研究提出了一种无监督事件检测模型,利用有序对比学习和prompt-based预测,解决了预定义事件类型限制的问题。模型通过对比样本生成器、事件编码器和有序对比损失函数来处理可见和不可见事件类型,实验在ACE2005和FewShotED数据集上展示了其有效性。
文章目录
1 简介
论文题目:Zero-Shot Event Detection Based on Ordered Contrastive Learning and Prompt-Based Prediction
论文来源:NAACL findings 2022
组织机构:华东师范大学
论文链接:https://aclanthology.org/2022.findings-naacl.196.pdf
代码链接:https://github.com/KindRoach/NAACL-ZEOP
1.1 动机
- 没有注释的新事件不断出现,使有监督的事件检测方法不再适用。
- 现有的事件检测方法需要预定义的事件类型作为启发式规则或外部语义分析工具。

1.2 创新
- 基于有序的对比学习提出一个zero-shot事件检测模型。
- 将基于prompt的预测引入到zero-shot事件检测问题中,消除了对预定义事件结构和启发式规则的依赖。
2 方法

模型的整体框架如上图,给定可见的事件类型S和不可见的事件类型U,全部的样本首先被作为原始样本
x
i
x_i
xi输入到对比样例生成器,构建多个对比样例为
{
s
1
,
.
.
.
,
s
2
}
\{s_1,...,s_2\}
{s1,...,s2},然后事件编码器编码事件提及为
e
i
e_i
ei,最后通过原型网络(prototypical network)预测事件类型的概率分布为
p
i
p_i
pi。
2.1 Contrastive sample generator

如上图所示,构建四种对比样本,与原始样本的相似度逐渐减弱:
- Dropout sample: 相同的句子输入到预训练模型中两次,由于训练中网络结点会被随机dropout,因此可以获得不同的编码。
- Rewrite sample: 对原始事件提及进行文本的编辑,为了保证语义相似性,使用回译的方法对事件提及进行重写。
- Homogeneous sample:取样同类的事件类型,对应可见的事件类型,随机取样相同标签的事件;对于不可见的事件类型,从不可见事件类型的事件中随机取样。
- Heterogeneous sample:取样不同类的事件类型,对应可见的事件类型,随机取样不相同标签的事件;对于不可见的事件类型,从可见事件类型的事件中随机取样。
2.2 Event encoder

触发词预测的模型如上图所示,prompt模板为"This is event about[MASK]. <event mention>",其中[MASK]为BERT需要预测的触发词, <event mention>为描述事件的文本。给定输入序列为
t
=
{
w
0
,
w
1
,
w
2
,
.
.
.
,
w
l
}
t=\{w_0,w_1,w_2,...,w_l\}
t={w0,w1,w2,...,wl},对事件提及中的全部词,得到分布
p
m
(
w
m
=
w
i
∣
t
)
p_m(w_m=w_i|t)
pm(wm=wi∣t)。

事件类型预测的模型如上图,使用原型网络,定义一个原型矩阵C(维度为n*h,n=k+l,k为可见的事件类型数量,l为不可见的事件类型数量,h为BERT的编码维度),对CLS和上一阶段预测的MASK向量进行相加,然后通过与原型矩阵计算欧几里得距离,预测事件类型,公式如下(d为计算欧几里得距离):

2.3 Ordered contrastive loss
对于全部的样本,计算Ordered contrastive loss, p 0 p_0 p0表示为原始事件的事件类型概率分布, p 1 − p 4 p_1-p4 p1−p4分别表示生成的四种样本的事件类型概率分布,首先使用Wasserstein距离(公式2)计算与原始事件的距离(公式1),对比loss为公式3(对于不可见事件类型的样本,在第三阶段可能随机取样到相同的事件类型):
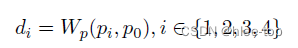
|
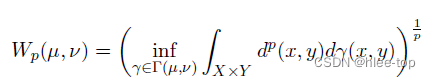
|
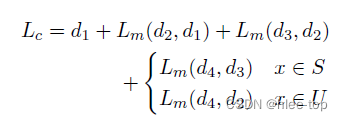
|
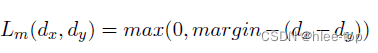
|
2.4 Supervised loss
对于可见事件类型的样本,使用监督学习的loss,总loss为两部分loss的和。
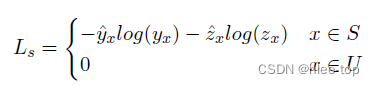
|
|
3 实验
实验数据集为ACE 2005和FewShotED(few-shot事件检测数据集),为了平衡可见事件类型和不可见事件类型的样本数,对每个事件类型的样本数量进行排序,奇数次序为可见类型,偶数次序为不可见类型,数据统计如下表:

实验结果如下图(Hungarian算法对预测的标签进行映射):

消融实验:

可视化分析:

不可见类型数量l对实验结果的影响(实际不可见类型的数量的1-5倍):



















 183
183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











