





博客主页:小馒头学python
本文专栏: Python爬虫五十个小案例
专栏简介:分享五十个Python爬虫小案例

🍬简介
随着网络技术的发展,数据抓取已经成为我们日常工作的一部分,尤其是在需要获取大量信息时,爬虫技术显得尤为重要。在这篇文章中,我们将学习如何爬取全国高校名单,获取各高校的基本信息,并将其保存到本地。无论你是数据分析师,还是想了解全国高校的分布情况,本篇文章都会为你提供一个完整的爬虫示范。
🍬所需工具与环境准备
在开始爬取全国高校名单之前,你需要配置好相关的开发环境。我们将使用 Python 作为编程语言,主要用到以下几个库:
- requests:用于发送网络请求,获取网页内容。
- BeautifulSoup:用于解析 HTML 网页。
- pandas:用于处理和保存数据。
安装这些库的命令如下:
pip install requests beautifulsoup4 pandas
🍬如何获取全国高校名单
🍬确定目标网站
要获取全国高校的名单,我们可以选择一个包含全国高校列表的开放网站。比如,你可以选择一个高等教育相关的门户网站,如 2024中国大学排名 或其他公开高校信息的站点。
🍬分析网页结构
在写爬虫之前,我们需要分析目标网页的结构,确定如何提取所需的信息。通常,我们会打开浏览器,右键网页并选择“查看网页源代码”,来了解各个元素的 HTML 标签及其结构。通过使用浏览器的开发者工具,我们可以定位到包含高校信息的部分。
例如,假设我们找到了一个包含高校名称、所在省份等信息的表格,接下来我们就可以开始写爬虫了。
🍬爬虫代码实现
🍬导入必要的库
首先,我们需要导入爬虫所需的库。代码如下:
import requests
from bs4 import BeautifulSoup
import pandas as pd
🍬获取网页数据
使用 requests 获取网页的 HTML 内容:
# 目标网站的URL
url = "https://www.shanghairanking.cn/rankings/bcur/2024"
# 模拟浏览器请求头,避免被反爬机制封禁
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# 发送请求获取页面内容
response = requests.get(url, headers=headers)
response.encoding = 'utf-8' # 确保中文显示正确
🍬解析数据
接下来,我们将使用 BeautifulSoup 对网页进行解析,从中提取出高校名称、地址等信息。假设高校名单在网页的一个表格中,代码如下:
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 提取所有的排名信息(假设每个排名信息都在<tr>标签中)
universities = soup.find_all('tr', {'data-v-68a1907c': True})
# 创建一个列表存储提取的数据
university_list = []
# 遍历所有大学排名信息
for university in universities:
# 初始化变量
rank = None
univname_cn = None
univname_en = None
location = None
score = None
# 获取排名
rank_tag = university.find('div', class_='ranking')
if rank_tag:
rank = rank_tag.get_text(strip=True)
# 获取大学名称(中文和英文)
univname_cn_tag = university.find('span', class_='name-cn')
univname_en_tag = university.find('span', class_='name-en')
if univname_cn_tag and univname_en_tag:
univname_cn = univname_cn_tag.get_text(strip=True)
univname_en = univname_en_tag.get_text(strip=True)
# 获取所有<td>元素并确保有足够数量
td_elements = university.find_all('td')
if len(td_elements) > 2:
location = td_elements[2].get_text(strip=True) # 获取第三个<td>元素
if len(td_elements) > 4:
score = td_elements[4].get_text(strip=True) # 获取第五个<td>元素
# 创建字典保存数据
university_data = {
'Rank': rank,
'Chinese Name': univname_cn,
'English Name': univname_en,
'Location': location,
'Score': score
}
# 将数据添加到列表
university_list.append(university_data)
🍬处理和存储数据
我们将数据存储到 pandas 的 DataFrame 中,便于后续处理或导出到 Excel 文件。
# 定义CSV文件路径
csv_file = "university_rankings.csv"
# 将数据保存到CSV文件
with open(csv_file, mode='w', newline='', encoding='utf-8-sig') as file:
writer = csv.DictWriter(file, fieldnames=['Rank', 'Chinese Name', 'English Name', 'Location', 'Score'])
writer.writeheader() # 写入表头
for university in university_list:
writer.writerow(university) # 写入每一行数据
print(f"Data has been saved to {csv_file}")
🍬注意事项与优化建议
在实际爬取过程中,可能会遇到一些挑战。以下是一些常见问题和优化建议:
- 反爬机制:许多网站会采取反爬虫措施,限制频繁访问。你可以通过设置请求间隔、使用代理、模拟浏览器请求等方式避免被封禁。
- 数据完整性:有些网站上的数据可能不完整或格式不统一,爬取时需要特别注意数据的清洗和标准化。
- 错误处理:在爬取过程中,可能会遇到一些网络请求失败的情况,建议增加错误处理机制,确保爬虫能够正常运行。
🍬完整源码
下图是完整的源码信息
import requests
from bs4 import BeautifulSoup
import csv
# 目标网站的URL
url = "https://www.shanghairanking.cn/rankings/bcur/2024"
# 模拟浏览器请求头,避免被反爬机制封禁
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# 发送请求获取页面内容
response = requests.get(url, headers=headers)
response.encoding = 'utf-8' # 确保中文显示正确
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 提取所有的排名信息(假设每个排名信息都在<tr>标签中)
universities = soup.find_all('tr', {'data-v-68a1907c': True})
# 创建一个列表存储提取的数据
university_list = []
# 遍历所有大学排名信息
for university in universities:
# 初始化变量
rank = None
univname_cn = None
univname_en = None
location = None
score = None
# 获取排名
rank_tag = university.find('div', class_='ranking')
if rank_tag:
rank = rank_tag.get_text(strip=True)
# 获取大学名称(中文和英文)
univname_cn_tag = university.find('span', class_='name-cn')
univname_en_tag = university.find('span', class_='name-en')
if univname_cn_tag and univname_en_tag:
univname_cn = univname_cn_tag.get_text(strip=True)
univname_en = univname_en_tag.get_text(strip=True)
# 获取所有<td>元素并确保有足够数量
td_elements = university.find_all('td')
if len(td_elements) > 2:
location = td_elements[2].get_text(strip=True) # 获取第三个<td>元素
if len(td_elements) > 4:
score = td_elements[4].get_text(strip=True) # 获取第五个<td>元素
# 创建字典保存数据
university_data = {
'Rank': rank,
'Chinese Name': univname_cn,
'English Name': univname_en,
'Location': location,
'Score': score
}
# 将数据添加到列表
university_list.append(university_data)
# 定义CSV文件路径
csv_file = "university_rankings.csv"
# 将数据保存到CSV文件
with open(csv_file, mode='w', newline='', encoding='utf-8-sig') as file:
writer = csv.DictWriter(file, fieldnames=['Rank', 'Chinese Name', 'English Name', 'Location', 'Score'])
writer.writeheader() # 写入表头
for university in university_list:
writer.writerow(university) # 写入每一行数据
print(f"Data has been saved to {csv_file}")
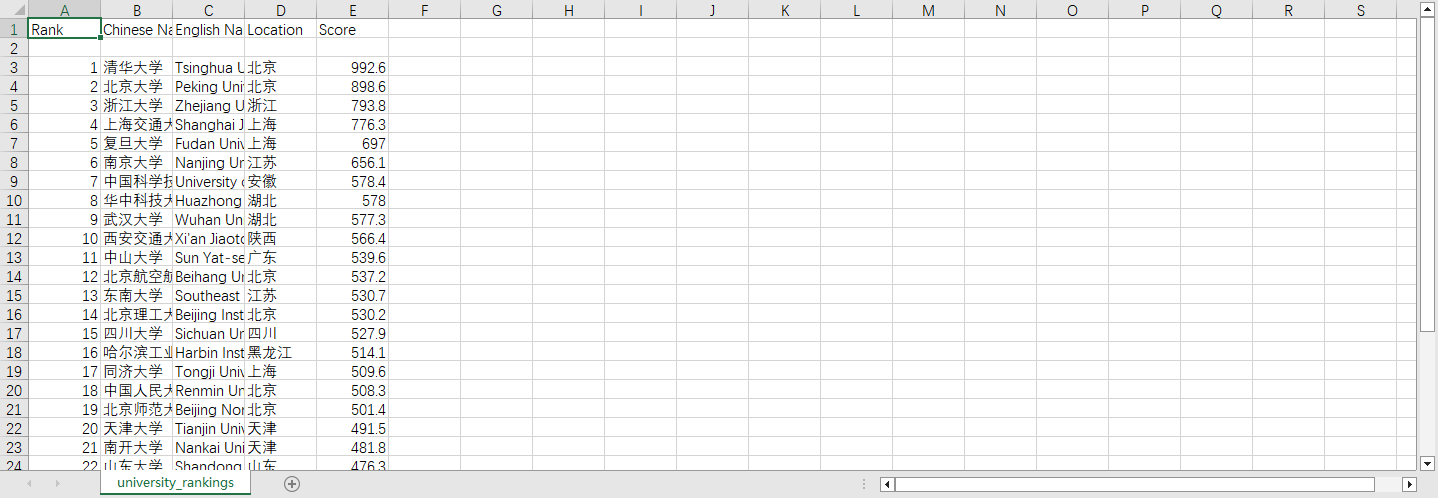
运行效果
🍬总结
本文介绍了如何通过 Python 爬虫爬取全国高校名单,并将数据保存为 CSV 文件。我们利用了 requests 获取网页内容,BeautifulSoup 解析 HTML,最后用 pandas 存储和处理数据。希望通过这篇博客,你能掌握基础的爬虫技能,并能够应用到其他项目中去。
如果你对爬虫开发、数据处理或者其他相关内容有更多的兴趣,欢迎关注我的博客,获取更多有趣的技术分享!
片转存中…(img-w016goPj-1732600097808)]
🍬总结
本文介绍了如何通过 Python 爬虫爬取全国高校名单,并将数据保存为 CSV 文件。我们利用了 requests 获取网页内容,BeautifulSoup 解析 HTML,最后用 pandas 存储和处理数据。希望通过这篇博客,你能掌握基础的爬虫技能,并能够应用到其他项目中去。
如果你对爬虫开发、数据处理或者其他相关内容有更多的兴趣,欢迎关注我的博客,获取更多有趣的技术分享!



















 2167
2167








 到【灌水乐园】发言
到【灌水乐园】发言









