



文章目录
一、引言
现在国内就业形势相比于之前来讲可能不是那么乐观,尤其是对于刚毕业的大学生而言,我表弟就是其中一员,整日在招聘网站苦苦寻找,像无头苍蝇一般,看了这家公司的基本要求,再看另一家,没有整体的分类与汇总很难掌握哪些公司的要求存在一些共性,这样求职的效率会大大降低,本节我们通过数据采集某招聘网站数据并将其作为数据交给大模型,从而筛选并找到心仪的工作。
二、基本的环境配置
本次我们的目标是采集某招聘网站,在实战之前,我们需要进行简单的环境配置,我们的整体步骤为:
- 创建虚拟环境(推荐使用Anaconda)
- 新建项目并激活虚拟环境
- 安装必要的依赖库
- 配置数据库
1. 创建虚拟环境
建议使用Anaconda进行环境管理,避免包冲突。打开命令行(Win+R 输入cmd),输入:
conda create -n data_caiji python=3.10
输入y确认,等待环境创建完成~
2. 新建项目并激活虚拟环境
完成上面的创建,接下来我们选择创建一个项目并配置一下环境

在此之前我们可以查看所有环境:
conda env list

输入下面的代码激活新环境:
conda activate data_caiji
3. 安装依赖库
在虚拟环境下,安装以下依赖:
pip install selenium pymysql beautifulsoup4
4. 配置数据库
本项目使用MySQL数据库,这里我们需要确保本地已安装MySQL版本8.0即可,并创建数据库job_data

建表SQL示例:
CREATE DATABASE IF NOT EXISTS job_data DEFAULT CHARSET utf8mb4;
USE job_data;
CREATE TABLE IF NOT EXISTS jobs (
id INT AUTO_INCREMENT PRIMARY KEY,
job_title VARCHAR(255),
salary_range VARCHAR(100),
work_location VARCHAR(100),
publish_time DATE,
job_description TEXT,
job_requirements TEXT,
company_name VARCHAR(255),
company_description TEXT,
detail_url VARCHAR(500)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
三、实战采集:某招聘网站
本节将详细介绍如何采集智联招聘的职位信息,并将数据存入MySQL数据库
1. 项目结构
下面我们简单的绘制一下项目整体流程:我们首先会使用Selenium启动浏览器,接下来我们会打开要采集的url地址,根据已经配置的代码进行获取职位相关信息,再经过数据处理后存入MySQL数据库
2. 核心代码讲解
2.1 MySQL数据库连接
import pymysql
DB_CONFIG = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': '123456',
'database': 'job_data',
'charset': 'utf8mb4'
}
def create_connection():
try:
conn = pymysql.connect(**DB_CONFIG)
return conn
except Exception as e:
print(f"数据库连接失败: {e}")
return None
2.2 浏览器初始化
- 第一步:设置User-Agent,这主要为了提升反爬能力
- 第二步:设置支持自动重连,防止因为网络波动造成的数据采集失败
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def init_browser():
chrome_options = Options()
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
chrome_options.add_argument("--disable-infobars")
chrome_options.add_argument("--disable-notifications")
chrome_options.add_argument(
"user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_experimental_option("detach", True)
driver = webdriver.Chrome(options=chrome_options)
driver.set_page_load_timeout(30)
return driver
2.3 职位列表采集
- 第一步:解析列表页,提取职位基本信息和详情页链接
- 第二步:支持多重CSS选择器兼容页面结构变化
def get_job_list(driver, keyword, page=1, retry=3):
base_url = f"https://sou.zhaopin.com/?jl=765&kw={keyword}&p={page}"
for attempt in range(retry):
try:
driver.get(base_url)
WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.joblist-box__item, .job-item, [class*="job"]'))
)
soup = BeautifulSoup(driver.page_source, 'html.parser')
job_items = soup.find_all('div', class_='joblist-box__item') or \
soup.find_all('div', class_='job-item') or \
soup.select('div[class*="job"]')
if not job_items:
print(f"第{attempt + 1}次尝试未找到职位元素")
time.sleep(random.uniform(3, 5))
continue
job_links = []
for item in job_items:
try:
job_data = {
'job_title': item.find('span', class_='jobname__title').text.strip() if item.find('span',
class_='jobname__title') else '无标题',
'salary_range': item.find('p', class_='job__salary').text.strip() if item.find('p',
class_='job__salary') else '面议',
'work_location': item.find('span', class_='job__location').text.strip() if item.find('span',
class_='job__location') else '地点未知',
'publish_time': process_publish_time(
item.find('span', class_='job__time').text.strip() if item.find('span',
class_='job__time') else ''),
'company_name': item.find('a', class_='company__title').text.strip() if item.find('a',
class_='company__title') else '公司未知',
'detail_url': item.find('a')['href'] if item.find('a') else ''
}
if job_data['detail_url'] and not job_data['detail_url'].startswith('http'):
job_data['detail_url'] = f"https://www.zhaopin.com{job_data['detail_url']}"
job_links.append(job_data)
except Exception as e:
print(f"解析职位列表项失败: {e}")
continue
return job_links
except Exception as e:
print(f"第{attempt + 1}次尝试失败: {e}")
time.sleep(random.uniform(5, 10))
if attempt == retry - 1:
print("达到最大重试次数,放弃本页")
return []
2.4 职位详情采集
- 第一步:进入详情页,提取职位描述、任职要求、公司介绍想要采集的信息
- 第二步:多种XPath定位,兼容页面变化,提高整体采集准确率
def get_job_detail(driver, job_data, retry=3):
for attempt in range(retry):
try:
driver.get(job_data['detail_url'])
WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="root"]'))
)
# 使用XPath获取关键字段
try:
job_title = driver.find_element(By.XPATH, '//*[@id="root"]/div[4]/div[1]/div/h3').text
except:
job_title = job_data.get('job_title', '无标题')
try:
work_location = driver.find_element(By.XPATH,
'//*[@id="root"]/div[4]/div[1]/div/div[2]/div[1]/ul/li[1]/a').text
except:
work_location = job_data.get('work_location', '地点未知')
try:
company_name = driver.find_element(By.XPATH, '//*[@id="root"]/div[5]/div[2]/div[2]/div[3]/a[1]').text
except:
company_name = job_data.get('company_name', '公司未知')
try:
company_desc = driver.find_element(By.XPATH, '//*[@id="root"]/div[5]/div[2]/div[2]/div[3]/div[2]').text
except:
company_desc = '无公司介绍'
# 获取职位描述和任职要求
job_desc = get_job_description(driver)
job_reqs = get_job_requirements(driver)
# 更新数据
job_data.update({
'job_title': job_title,
'work_location': work_location,
'company_name': company_name,
'company_description': company_desc,
'job_description': job_desc,
'job_requirements': job_reqs
})
return job_data
except Exception as e:
print(f"第{attempt + 1}次尝试获取详情失败: {e}")
time.sleep(random.uniform(3, 5))
if attempt == retry - 1:
print("获取详情失败,返回基础信息")
job_data.update({
'job_description': '获取失败',
'job_requirements': '获取失败',
'company_description': '获取失败'
})
return job_data
2.5 数据存储到MySQL
将采集到的数据存入MySQL
def save_job_to_db(job_data):
conn = create_connection()
if not conn:
return False
try:
with conn.cursor() as cursor:
# 确保日期有效
publish_time = job_data['publish_time'] if job_data['publish_time'] else datetime.now().strftime('%Y-%m-%d')
sql = """INSERT INTO jobs (
job_title, salary_range, work_location, publish_time,
job_description, job_requirements, company_name,
company_description, detail_url
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)"""
cursor.execute(sql, (
job_data['job_title'],
job_data['salary_range'],
job_data['work_location'],
publish_time,
job_data['job_description'],
job_data['job_requirements'],
job_data['company_name'],
job_data['company_description'],
job_data['detail_url']
))
conn.commit()
return True
except Exception as e:
print(f"保存数据失败: {e}")
conn.rollback()
return False
finally:
conn.close()
2.6 主函数编写
if __name__ == "__main__":
keyword = "Python" # 搜索关键词。自行替换
max_pages = 2 # 最大采集页数
crawl_zhilian(keyword, max_pages)
3. 运行效果与结果展示
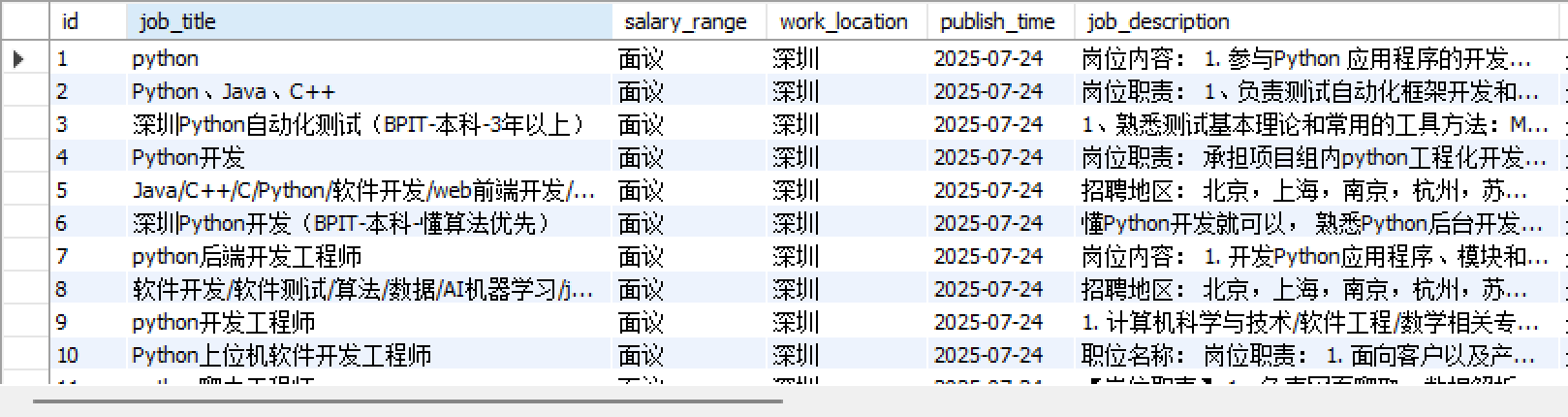
运行后,我们会在控制台显示部分数据

同时我们也可以看看MySQL数据库是否真的保存进去了,结果全部保存进去了
4. 大模型分析展示
因为刚刚我们只采用保存为MySQL数据库里面的形式,接下来我们可以加一个函数将其保存为csv文件
import csv
def export_jobs_to_csv(csv_filename='jobs_export.csv'):
conn = create_connection()
if not conn:
print("数据库连接失败,无法导出数据")
return
try:
with conn.cursor() as cursor:
cursor.execute("SELECT job_title, salary_range, work_location, publish_time, job_description, job_requirements, company_name, company_description, detail_url FROM jobs")
rows = cursor.fetchall()
columns = [desc[0] for desc in cursor.description]
with open(csv_filename, 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(columns) # 写表头
writer.writerows(rows)
print(f"数据已成功导出到 {csv_filename}")
except Exception as e:
print(f"导出CSV失败: {e}")
finally:
conn.close()
接下来我们可以将获取的数据交给deepseek,并附上简单的需求
我是一名即将毕业的毕业生,我想要找一些适合我的工作,并进行排序取前五,同时给我相关建议

四、结语
通过本篇实战,我们完成了从环境搭建、数据库设计,到Selenium爬虫开发、数据存储的全流程,你不仅可以采集招聘网站的数据,还可以通过采集到的数据交给大模型进行分析总结,帮助了我们更快的找到心仪的职位~~~


















 1433
1433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











