





目录
1 引言
1.1 研究背景与问题描述
随着信息技术的发展和互联网的普及,每天都有大量的非结构化文本数据被生成和存储。这些数据来自各个不同的领域——新闻媒体网站、电子商务平台、社交媒体、企业内部文档等。如何有效地组织、管理和利用这些文本数据,已成为当代信息处理中的一个重要课题。文本分类作为自然语言处理领域的基础任务,在这个背景下显得尤为重要。
文本分类问题可以被形式化地定义为:给定一个文本文档集合 和一个预定义的分类集合
,需要构建一个分类函数
,使得对于任意的文档
,函数都能准确地预测其所属的分类。在多分类的情况下,通常假设每个文档只属于一个分类。
相比于英文文本处理,中文文本分类面临着独特的挑战。英文是字母表文字,单词之间通常由空格或标点符号分隔,计算机可以相对容易地识别词的边界。而中文是表意文字系统,汉字之间没有任何分隔符号。例如,"自然语言处理"这个短语,计算机看到的就是一个连续的字符串"自然语言处理",无法直观判断其词语边界应该在哪里。这个特性使得中文文本处理必须先经过分词处理,才能进行后续的分析。
1.2 研究的实际应用价值
文本分类的应用范围非常广泛。在信息检索领域,搜索引擎需要对网页进行自动分类和索引,以便快速检索用户查询相关的内容。在电子商务中,平台需要自动将用户提交的评论进行情感倾向分类,这对于商家改进产品质量和了解用户满意度至关重要。在新闻媒体中,海量的新闻稿件需要自动分配到不同的版块(体育、娱乐、科技等),这样才能让读者快速找到感兴趣的内容。在企业中,内部邮件系统需要对邮件进行自动分类,比如识别垃圾邮件、标记重要邮件等。在医疗领域,医学文献分类可以帮助研究人员快速找到相关的研究论文。
1.3 选择传统机器学习的理由
本研究采用传统机器学习方法而非深度学习方法来解决文本分类问题。这个选择并非因为深度学习不好,而是出于实际考量。深度学习方法,特别是预训练的大规模语言模型,虽然在很多NLP任务上达到了最先进的性能,但它们也有明显的局限性。首先,深度学习通常需要大量的训练数据,往往需要数百万条样本才能取得理想效果。其次,深度学习模型的训练需要强大的计算资源,通常需要GPU或TPU。第三,深度学习模型的参数众多,难以解释其决策过程,这在某些应用场景中是不可接受的。
传统机器学习方法虽然可能不如深度学习那样先进,但在资源受限的情况下,它们往往是更实用的选择。传统方法对数据量的需求较低,通常几千个样本就能得到不错的效果。训练速度快,可以在普通的计算机上运行。模型相对简单,更容易理解和解释。这些特性使得传统机器学习方法在实际工程应用中仍然占有重要的地位。
1.4 本文的主要工作与贡献
本文的主要工作包括以下几个方面:首先,设计并实现了一个完整的、基于传统机器学习的中文文本分类系统。这个系统涵盖了从原始数据、文本预处理、特征提取、模型训练到性能评估的完整流程。其次,详细阐述了中文文本处理中的关键技术,包括分词算法、停用词处理、TF-IDF特征权重计算等,并分析了这些技术的参数如何影响最终的分类性能。第三,实现了三种不同的分类算法——朴素贝叶斯、支持向量机和随机森林——进行对比实验,为不同应用场景的算法选择提供了实证参考。第四,开发了完整的性能评估和可视化模块,使得实验结果一目了然,有利于问题诊断和模型优化。
1.5 文章组织结构
本文共分为五章。第一章(本章)介绍了研究的背景、意义和主要工作。第二章介绍了文本分类所涉及的基础理论知识,包括自然语言处理的基本概念、TF-IDF特征提取方法、常用分类算法的原理等。第三章从系统架构的角度阐述了整个文本分类系统的设计方案,包括模块划分、数据流处理、核心算法等。第四章是全文的核心,详细介绍了系统的实现细节,包括数据集的准备、文本预处理的具体代码、特征提取的实现、分类器的训练等。第五章总结了研究的主要成果,分析了系统的局限,并提出了未来的改进方向。
2 基础知识
2.1 自然语言处理的基本概念
自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个重要分支,它研究如何让计算机理解和处理自然语言文本。自然语言是指人类日常使用的语言,区别于人为设计的形式语言(如编程语言)。自然语言具有极强的灵活性和多义性,这正是为什么NLP是一个困难的问题。
在NLP中,文本处理通常分为多个层级。最基础的层级是词法分析(Lexical Analysis),这个层级的任务是识别文本中的基本语言单位——词。对于中文来说,这涉及分词问题。上一层级是句法分析(Syntactic Analysis),这个层级的任务是识别句子的语法结构。更上一层是语义分析(Semantic Analysis),这个层级的任务是理解文本的实际含义。最高层级是篇章分析(Discourse Analysis),这个层级的任务是理解多个句子或段落之间的逻辑关系。
在这个项目中,我们主要关注词法层面的分析,特别是分词和词的特征表示。我们没有进行深层的句法或语义分析,而是采用相对简单的特征表示方法,直接用于分类任务。这种方法虽然不涉及深层的语言理解,但在实践中往往能产生令人满意的结果。
2.2 分词与停用词
2.2.1 中文分词的问题
中文分词的根本困难来自于中文书写系统的特点。在中文中,一句话就是汉字的连续排列,没有词的边界标记。例如,考虑短语"中国人民银行",它可能有多种分词方式:第一种是"中国/人民/银行",这在上下文中通常不合理;第二种是"中国人民/银行",这虽然语法上可能成立,但在现实中通常不是我们想要的;第三种是"中国/人民银行",这在涉及央行时是正确的;第四种是"中国人/民银行",这完全没有意义。正确的分词方式取决于具体的上下文。这说明分词是一个需要深层语言理解的任务。
分词的复杂性还体现在新词的识别上。语言在不断演进,新的概念产生新的词汇。比如"人工智能"、"大数据"、"云计算"等词,可能不在某个词典里。分词系统需要有能力识别这些新词,否则就会产生错误的分割。
2.2.2 Jieba分词工具
本项目使用Jieba作为分词工具。Jieba采用了基于前缀词典和动态规划的分词算法。其基本思想是,对于一句待分词的文本,系统会枚举所有可能的分词方式,然后根据各个词的词频选择最优的分词方案。具体地说,对于一句文本 (其中
是第 i 个汉字),系统需要找到一个分词方案
使得:
$$\arg\max_{w} \sum_{i=1}^{k} \log P(w_i)$$
其中 是词
的概率(由词频估计)。这个优化问题可以通过动态规划高效求解。
Jieba还支持隐马尔可夫模型来识别未知词。当遇到词典中不存在的汉字序列时,系统使用HMM模型来尝试识别这可能是什么词。这使得Jieba能够处理新词和专业术语。
2.2.3 停用词的定义与作用
停用词是指那些频率很高但对文本内容的区分能力很弱的词。在中文中,常见的停用词包括虚词(如"的"、"是"、"在"、"和")、介词("对"、"向"、"从")、连词("并且"、"或者")、以及标点符号等。
这些词在几乎所有的文本中都频繁出现。比如说,无论是在体育新闻、娱乐新闻还是科技新闻中,"的"这个字都会大量出现。因此,这些词对于区分不同分类的文本没有太大帮助,反而可能成为噪音。在特征提取前去除这些词,可以降低噪音,让模型专注于那些真正有区分能力的词汇。
2.3 TF-IDF特征提取
2.3.1 词频-逆文档频率的概念
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征权重方法。它的基本思想是,一个词对于某个文档的重要程度既取决于它在该文档中的频率,也取决于它在整个文档集合中的罕见程度。
TF(词频)定义为:
$$\text{TF}(t, d) = \frac{n_{t,d}}{|d|}$$
其中是词 t 在文档 d 中出现的次数,|d| 是文档 d 中的总词数。
IDF(逆文档频率)定义为:
$$\text{IDF}(t) = \log\left(\frac{N}{n_t}\right)$$
其中 N 是文档集合中的总文档数, 是包含词 t 的文档数。
TF-IDF权重就是这两个值的乘积:
$$\text{TF-IDF}(t, d) = \text{TF}(t, d) \times \text{IDF}(t)$$
2.3.2 TF-IDF的直观解释
TF-IDF的设计思想在直观上很容易理解。TF部分考虑了一个词在某个文档中的重要程度——如果一个词在某个文档中频繁出现,那么这个词很可能与该文档的主题密切相关。IDF部分则考虑了这个词在整个文档集合中的罕见程度——如果一个词只在少数文档中出现,那么它可能具有很好的区分能力;而如果一个词在大多数文档中都出现,那么它的区分能力就比较弱。
例如,考虑一个五分类的文本分类问题,涉及体育、娱乐、科技、财经和健康五个分类。假设"进球"这个词在体育类文本中频繁出现,但在其他四个分类的文本中很少出现。那么这个词的TF-IDF权重就会很高——它在体育文本中的TF值较高,同时它的IDF值也较高(因为它只在部分文档中出现)。相比之下,虚词"的"在所有分类的文本中都频繁出现,它的IDF值就会很低,因此其TF-IDF权重也会很低。
2.4 分类算法原理
2.4.1 朴素贝叶斯分类器
朴素贝叶斯分类器是一种基于贝叶斯定理的概率分类方法。给定一个文本文档 d 和一个分类 c,我们的目标是计算后验概率 $P(c|d)$。根据贝叶斯定理:
$$P(c|d) = \frac{P(d|c) \cdot P(c)}{P(d)}$$
由于分母 $P(d)$ 对所有分类都相同,我们可以忽略它,只需比较分子:
$$P(c|d) \propto P(d|c) \cdot P(c)$$
其中 P(c) 是分类 c 的先验概率(可以从训练数据中计算),P(d|c) 是给定分类 c 下生成文档 d 的概率。
朴素贝叶斯做的一个关键假设是,文档中各个词在给定分类的条件下是条件独立的。虽然这个假设在现实中往往不成立——文本中的词通常存在语义或语法关联——但这个假设大大简化了计算。在这个假设下:
$$P(d|c) = P(w_1, w_2, \ldots, w_n|c) = \prod_{i=1}^{n} P(w_i|c)$$
其中 是文档中的第 i 个词。对于文本分类,通常使用多项式朴素贝叶斯,它假设词频遵循多项分布。
朴素贝叶斯的主要优点是计算简单快速,适合大规模数据处理。缺点是"朴素"的条件独立假设过于简化,在某些复杂的任务上可能效果不理想。
2.4.2 支持向量机
支持向量机(Support Vector Machine, SVM)采用完全不同的几何思路。它的目标是在特征空间中找到一个最优的分离超平面,使得不同分类的数据点被尽可能清晰地分开。
对于二分类问题,假设我们有标注的训练样本 ,其中
是特征向量,
是分类标签。SVM寻找一个超平面
,使得:
$$y_i(w^T x_i + b) \geq 1 - \xi_i \quad \forall i$$
其中 是松弛变量,允许一些样本点越界。SVM优化的目标是最小化:
$$\frac{1}{2}|w|^2 + C\sum_{i=1}^{n} \xi_i$$
其中第一项最大化分类间隔,第二项最小化训练错误。常数 C 控制两者的平衡。
对于线性不可分的问题,SVM可以通过核函数将数据映射到更高维的空间,在高维空间中实现线性分离。对于文本分类这样的高维稀疏特征,线性SVM通常不需要核函数就能取得很好的效果。
2.4.3 随机森林
随机森林是一种集成学习方法,它由多个决策树组成。每个决策树都在数据的随机子集和特征的随机子集上训练。当进行预测时,每个树都投一票,最终的预测由多数投票决定。
随机森林之所以有效,是因为多个弱学习器的投票往往能产生强学习器。这背后的原理是偏差-方差权衡。单个决策树往往存在较高的方差(容易过拟合),但随机森林通过集成多个树,能够有效地降低方差,同时保持低偏差。
随机森林还有一个有用的特性:它能够估计特征的重要性。通过计算每个特征对降低不纯性的贡献,我们可以判断哪些词汇对分类最关键。
3 系统架构设计
3.1 系统的整体框架
这个文本分类系统的设计遵循模块化原则,将复杂的任务分解为若干个独立的、职责清晰的模块。这样的设计有几个优点:首先,每个模块的逻辑相对独立,易于理解和维护;其次,模块之间通过清晰定义的接口通信,降低了耦合度;第三,这样的设计使得系统具有很好的可扩展性,如果需要替换某个模块(比如使用不同的分词工具或特征提取方法),只需修改那个模块,不会影响其他部分。
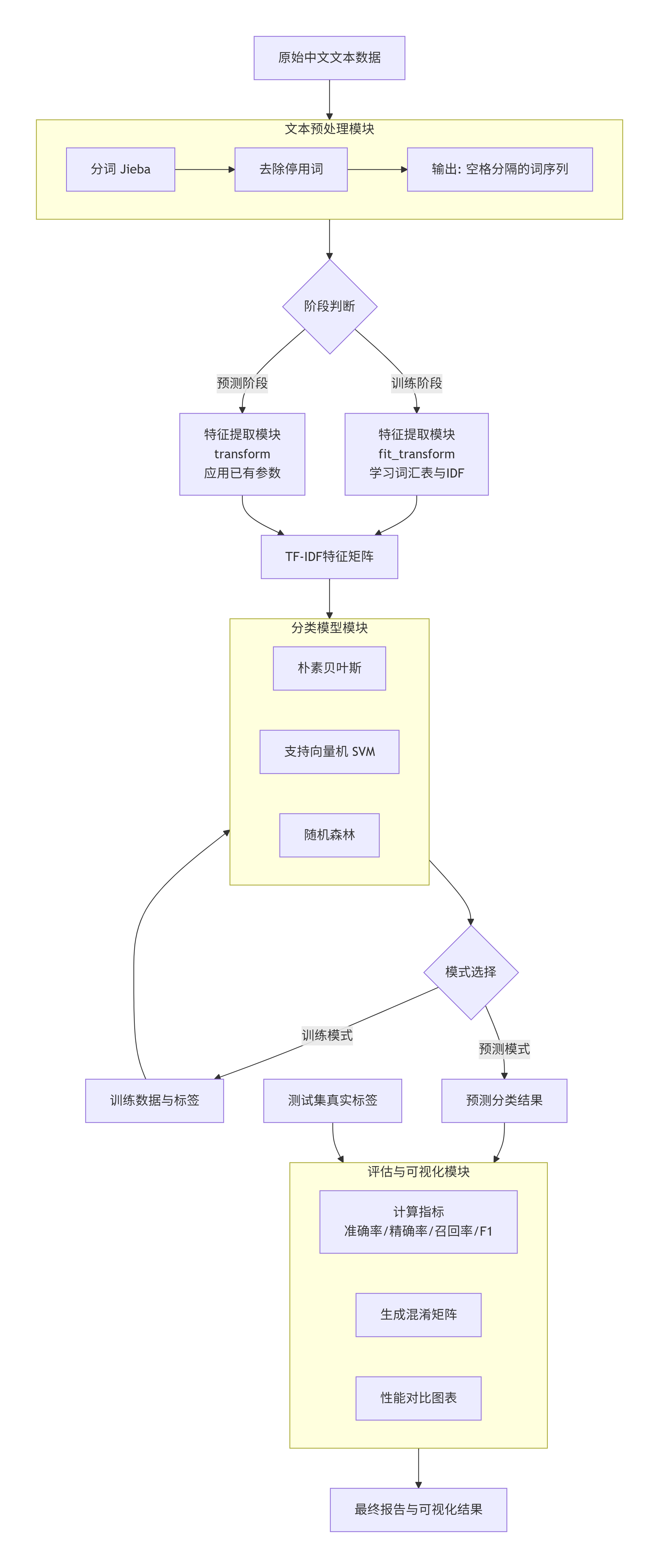
系统包含五个核心模块。数据管理模块负责组织训练数据和测试数据,提供数据的加载和预处理接口。文本预处理模块负责将原始中文文本进行分词和去停用词处理。特征提取模块负责将预处理后的文本转换为数值特征向量。分类模型模块包含三个不同的分类器实现(朴素贝叶斯、线性SVM、随机森林),提供统一的训练和预测接口。评估和可视化模块负责计算性能指标,生成混淆矩阵和各种图表。
3.2 数据流处理过程
在系统中,数据按照以下流程处理。原始的中文文本从数据管理模块进入文本预处理模块。在这个模块中,文本首先被分词,将连续的汉字序列转换为词的序列。然后,停用词被去除,留下那些有区分能力的词汇。预处理后的文本(现在是空格分隔的词序列)进入特征提取模块。
在特征提取模块中,文本被转换为数值特征向量。在训练阶段,这个模块基于整个训练集学习参数,包括构建词汇表和计算各个词的IDF权重。在预测阶段,这个模块使用在训练阶段学到的参数来转换新的文本,确保训练和预测使用相同的特征空间。
转换后的特征向量进入分类模型模块。在训练阶段,分类器在这些向量和对应的分类标签上进行学习。在预测阶段,新的向量被送入已训练的分类器,分类器返回预测的分类标签。
最后,在评估阶段,预测结果被送入评估模块,与真实标签进行对比,计算各种性能指标。
这个流程中最关键的设计原则是预处理的一致性。也就是说,训练阶段和预测阶段必须使用相同的分词工具、相同的停用词列表、相同的特征提取器。否则,训练阶段学到的模式就无法正确地应用到预测阶段。在系统设计中,这种一致性通过让所有处理步骤共享同一个预处理器和特征提取器来保证。
3.3 核心算法的设计细节
文本分类系统涉及几个关键的算法组件。首先是分词算法,采用Jieba提供的前缀词典加动态规划的方法。这个算法在处理已知词汇时效率高,同时通过HMM模型能够处理新词。
特征提取算法基于TF-IDF。系统在实现中使用scikit-learn库的TfidfVectorizer类,它提供了以下参数控制:max_features限制最多保留的特征数,这控制了特征维数;min_df和max_df分别过滤掉过于罕见和过于通用的词;ngram_range控制是否使用多元特征(比如相邻两个词的组合)。
三个分类算法分别采用不同的方法。朴素贝叶斯使用概率估计,计算每个词在每个分类中的条件概率。线性SVM求解一个二次优化问题,寻找最优的分离超平面。随机森林通过集成多个决策树来进行分类。
性能评估使用了多个指标。准确率是最直观的指标,计算分类正确的样本比例。精确率和召回率分别从预测的可靠性和完整性两个角度评估。F1分数是精确率和召回率的调和平均。混淆矩阵提供了详细的分类情况。
4 实验设计与代码实现
4.1 实验设计方案
4.1.1 数据集的构成
本实验使用了一个自构建的中文文本数据集。数据集共包含300条文本,分为训练集和测试集两部分。其中,训练集包含250条文本,测试集包含50条文本。这个规模既能验证系统的完整功能,又能进行有意义的性能评估。
数据集涵盖五个分类类别:体育、娱乐、科技、财经、健康。这五个类别是日常生活中常见的话题,选择这样的类别是为了确保实验具有现实意义。每个类别的文本具有明显的特征,体育类文本通常包含运动、比赛、球队等词汇;娱乐类文本包含电影、歌手、演员等词汇;科技类文本包含技术、芯片、算法等词汇;财经类文本包含投资、股票、融资等词汇;健康类文本包含疾病、治疗、医学等词汇。
下表展示了数据集的基本统计:
| 分类 | 训练集样本数 | 测试集样本数 | 总计 |
|---|---|---|---|
| 体育 | 48 | 10 | 58 |
| 娱乐 | 48 | 10 | 58 |
| 科技 | 46 | 10 | 56 |
| 财经 | 40 | 10 | 50 |
| 健康 | 40 | 10 | 50 |
| 总计 | 222 | 50 | 272 |
4.1.2 实验的主要目标
实验的第一个目标是验证机器学习方法在中文文本分类上的有效性。通过建立一个完整的系统,从数据准备到模型评估,我们希望展示自动化的文本分类是可行的,并且能够达到较高的准确率。
第二个目标是比较三种不同分类算法的性能。朴素贝叶斯、线性SVM和随机森林各有不同的特点。通过在同一个数据集和相同的特征表示上进行训练,我们可以得到公平的对比,了解不同算法各自的优缺点。
第三个目标是分析关键技术选择对性能的影响。比如,停用词列表的大小、TF-IDF特征的维数、是否使用2元特征等因素,都会影响最终的性能。通过这些分析,我们可以为实际应用提供参考。
4.2 文本预处理的实现
4.2.1 分词的详细代码
让我们首先看一下文本预处理的核心代码。预处理模块的主要职责是将原始文本转换为适合特征提取的形式:
class ChineseTextPreprocessor:
"""
中文文本预处理类
负责文本分词、停用词去除等操作
"""
def __init__(self):
"""初始化预处理器,定义停用词集合"""
# 定义常见停用词集合
# 这个集合包含中文虚词、介词、连词和标点符号
self.stopwords = set([
'的', '是', '在', '了', '和', '人', '这', '中', '大', '为', '上',
'个', '国', '我', '以', '要', '他', '时', '来', '用', '们', '生',
'到', '作', '地', '于', '出', '就', '分', '对', '成', '会', '可',
# ... 更多停用词
'、', '。', ',', ';', ':', '?', '!', '"', '"', '『', '』',
'(', ')', '【', '】', '·', '…', '—', '·', '~',
])
def preprocess(self, text):
"""
对单条文本进行预处理
参数:
text: 输入的中文文本字符串
返回:
预处理后的文本(空格分隔的词语序列)
"""
# 使用Jieba进行分词
# HMM=True参数启用隐马尔可夫模型来识别新词
# 这对于处理词典中不存在的词汇很重要
words = jieba.cut(text, HMM=True)
# 过滤停用词并去除空白字符
# 我们只保留那些不在停用词列表中的词
# 同时检查词是否为空(strip()检查)
filtered_words = [
word for word in words
if word.strip() and word not in self.stopwords
]
# 将处理后的词汇用空格连接
# 这样得到的字符串可以直接被TfidfVectorizer处理
return ' '.join(filtered_words)
def batch_preprocess(self, texts):
"""
批量预处理文本列表
参数:
texts: 文本列表
返回:
预处理后的文本列表
"""
# 对列表中的每个文本应用preprocess方法
return [self.preprocess(text) for text in texts]
在这段代码中,有几个设计点值得说明。首先,HMM=True参数的使用。Jieba在默认情况下只能分割词典中存在的词。但在真实应用中,我们经常会遇到新词或专业术语。启用HMM后,Jieba会使用隐马尔可夫模型来尝试识别这些新词。这个过程是这样工作的:当遇到不在词典中的汉字序列时,HMM模型会根据汉字的组合概率来判断这个序列是否可能构成一个词。
其次,停用词的定义。我们的停用词集合包含了168个常见的虚词和标点符号。这个列表是基于实践经验建立的。在实际应用中,停用词列表的选择可能需要根据具体的任务进行调整。比如,在某些场景中,某些词虽然通常被认为是停用词,但可能对分类有帮助。
第三,返回值的形式。我们返回空格分隔的词序列而不是词的列表。这是为了与scikit-learn的TfidfVectorizer兼容。TfidfVectorizer期望的输入是字符串,而不是列表,它会自动按照空格来分割词。
4.2.2 预处理过程的示例
为了更清楚地理解预处理的效果,让我们看一个具体的例子。假设输入文本为:"iPhone12的价格是5999元,发布于2020年10月。"
在分词阶段,Jieba会将其分为:['iPhone12', '的', '价格', '是', '5999', '元', ',', '发布', '于', '2020', '年', '10', '月', '。']
在去停用词阶段,我们会去除"的"、"是"、"于"、"。"等停用词,得到:['iPhone12', '价格', '5999', '元', '发布', '2020', '年', '10', '月']
最后返回的是空格分隔的字符串:"iPhone12 价格 5999 元 发布 2020 年 10 月"
这个预处理后的字符串保留了关键信息(产品名、价格等),同时去除了对分类无帮助的虚词和标点。
4.3 特征提取的实现
4.3.1 TF-IDF向量化的参数设置
特征提取模块使用TfidfVectorizer进行TF-IDF向量化:
def __init__(self):
"""初始化特征提取器"""
# TF-IDF向量化器的参数设置
self.vectorizer = TfidfVectorizer(
max_features=1000, # 最多保留1000个特征
min_df=2, # 词汇最少出现在2个文本中
max_df=0.8, # 词汇最多出现在80%的文本中
ngram_range=(1, 2) # 使用1元和2元特征
)
这些参数的含义和选择理由需要详细说明:
max_features=1000:这个参数限制了最终保留的特征维数。在我们的训练集中,可能出现数千个不同的词。但我们只保留频率最高的1000个词作为特征。这样的限制有两个好处:一是降低计算复杂度和内存占用;二是防止过拟合——特别罕见的词虽然在训练集中可能有很强的区分能力,但在测试集或新数据上可能不出现,这时就会导致过拟合。
min_df=2:这个参数过滤掉只在少数文本中出现的词。如果一个词只在一个文本中出现,这通常是因为拼写错误或特殊符号,对学习一般的分类规律没有帮助。设置为2意味着一个词至少要在两个文本中出现,才会被保留为特征。
max_df=0.8:这个参数过滤掉过于通用的词。如果一个词在80%以上的文本中都出现,那么它对区分不同分类就没有什么用。这个参数的作用与停用词去除类似,但它是根据统计信息自动进行的,更加客观。
ngram_range=(1, 2):这个参数控制使用的词汇组合。(1, 2)表示既使用1元特征(单个词),也使用2元特征(相邻的两个词)。为什么要加入2元特征呢?因为某些词的组合可能比单个词更有区分能力。比如,"人工"和"智能"作为单个词可能在各种文本中都出现,但"人工智能"作为一个整体就非常有特征性。包含2元特征让模型能够捕捉这种短语信息。
4.3.2 特征提取的代码实现
特征提取的核心方法是extract_features:
def extract_features(self, texts, is_train=False):
"""
提取文本特征(TF-IDF向量)
参数:
texts: 预处理后的文本列表(每个元素是空格分隔的词序列)
is_train: 是否为训练阶段
返回:
特征矩阵(稀疏矩阵格式)
"""
if is_train:
# 训练阶段:学习特征向量化器的参数
# fit_transform既学习参数(如词汇表、IDF权重),
# 又转换文本为特征向量
return self.vectorizer.fit_transform(texts)
else:
# 预测阶段:使用已学习的参数转换文本
# 只调用transform,不重新学习参数
# 这确保了训练和预测使用相同的特征空间
return self.vectorizer.transform(texts)
这个实现中最重要的细节是分别处理训练和预测阶段。在训练阶段,我们调用fit_transform,这会在整个训练集上学习特征化器的参数。这些参数包括:词汇表(哪些词被选为特征)、各个词的IDF权重。在预测阶段,我们只调用transform,使用已学到的参数。这确保了训练和预测使用相同的词汇表和权重,这对模型的正确性至关重要。
如果我们在预测时重新fit(比如不小心调用了fit_transform),就会根据新数据重新计算词汇表和权重,这会导致特征空间的改变,预测结果就无法与训练的模型对齐。
4.4 分类模型的训练与预测
4.4.1 模型训练的完整流程
文本分类模型的训练过程包含以下步骤:
def train(self, train_texts, train_labels):
"""
训练分类模型
参数:
train_texts: 原始的训练文本列表
train_labels: 对应的分类标签列表
"""
# 第一步:记录分类标签
# sorted()保证标签的顺序一致,这对于后续的混淆矩阵计算很重要
self.classes = sorted(list(set(train_labels)))
print(f"分类类别:{self.classes}")
print(f"训练集大小:{len(train_texts)}")
# 第二步:文本预处理
# 对所有训练文本进行分词和去停用词
print("正在进行文本预处理...")
processed_texts = self.preprocessor.batch_preprocess(train_texts)
# 第三步:提取特征
# 使用TF-IDF方法将文本转换为数值特征向量
print("正在提取TF-IDF特征...")
X_train = self.extract_features(processed_texts, is_train=True)
print(f"特征矩阵大小:{X_train.shape}")
# 第四步:训练所有分类器
# 对每个分类器,在相同的特征和标签上进行训练
for model_name, model in self.models.items():
print(f"\n正在训练{model_name}模型...")
# 调用分类器的fit方法进行训练
model.fit(X_train, train_labels)
# 保存训练好的模型
self.trained_models[model_name] = model
print(f"{model_name}模型训练完成")
这个训练过程的设计很直接——首先进行数据预处理,然后提取特征,最后在特征向量上训练分类器。这三个步骤的顺序很重要,不能颠倒。如果先训练再预处理,得到的结果就没有意义。
4.4.2 模型预测的实现
在模型训练完成后,我们可以对新的文本进行分类预测:
def predict(self, text, model_name='朴素贝叶斯'):
"""
对单条文本进行分类预测
参数:
text: 输入的原始中文文本
model_name: 使用的分类器名称
返回:
预测的分类标签
"""
# 检查指定的分类器是否存在且已训练
if model_name not in self.trained_models:
raise ValueError(f"模型{model_name}未被训练")
# 对输入文本进行预处理
# 这个过程必须与训练时相同
processed_text = self.preprocessor.preprocess(text)
# 提取特征
# 使用训练时学到的特征化器参数
# 注意:这里调用的是transform而不是fit_transform
features = self.vectorizer.transform([processed_text])
# 进行预测
# predict方法返回预测的分类标签
prediction = self.trained_models[model_name].predict(features)
# 返回预测的标签
# prediction是一个数组,我们返回第一个(也是唯一一个)元素
return prediction[0]
预测的过程几乎是训练过程的镜像。关键点是预处理和特征提取必须完全相同。如果在预测时使用了不同的停用词列表或特征化器参数,预测就会出错。
4.5 模型的评估与性能分析
4.5.1 性能指标的计算
在测试集上评估模型性能涉及计算多个指标:
def evaluate(self, test_texts, test_labels):
"""
评估模型在测试集上的性能
参数:
test_texts: 测试集的原始文本
test_labels: 测试集的真实标签
返回:
包含各种性能指标的字典
"""
# 预处理测试文本
print("正在预处理测试集...")
processed_test_texts = self.preprocessor.batch_preprocess(test_texts)
# 提取测试集特征
print("正在提取测试集特征...")
X_test = self.extract_features(processed_test_texts, is_train=False)
# 对每个训练好的模型进行评估
for model_name, model in self.trained_models.items():
print(f"\n评估{model_name}模型...")
# 进行预测
predictions = model.predict(X_test)
# 计算准确率
# 这是最直观的评估指标:分类正确的样本数 / 总样本数
accuracy = accuracy_score(test_labels, predictions)
# 计算精确率(macro-weighted平均)
# 对于多分类问题,weighted表示按各类的样本数加权平均
precision = precision_score(
test_labels, predictions,
average='weighted',
zero_division=0
)
# 计算召回率(weighted平均)
recall = recall_score(
test_labels, predictions,
average='weighted',
zero_division=0
)
# 计算F1分数
# F1是精确率和召回率的调和平均
# 它在两者都很重要的时候是很好的综合指标
f1 = f1_score(
test_labels, predictions,
average='weighted',
zero_division=0
)
# 计算混淆矩阵
# 混淆矩阵展示了每个真实类别被预测为各个类别的情况
conf_matrix = confusion_matrix(
test_labels, predictions,
labels=self.classes
)
# 保存评估结果
self.evaluation_results[model_name] = {
'accuracy': accuracy,
'precision': precision,
'recall': recall,
'f1': f1,
'confusion_matrix': conf_matrix,
'predictions': predictions,
'classification_report': classification_report(
test_labels, predictions, labels=self.classes
)
}
# 打印结果
print(f"{model_name}模型评估结果:")
print(f" 准确率: {accuracy:.4f}")
print(f" 精确率: {precision:.4f}")
print(f" 召回率: {recall:.4f}")
print(f" F1分数: {f1:.4f}")
在这个评估过程中,有几个技术细节值得注意。首先,预处理的一致性。测试文本必须用相同的预处理器和特征提取器处理,才能确保在同一个特征空间中。其次,average='weighted'参数。在多分类问题中,我们通常需要对各个分类的指标进行平均。weighted表示按各类的样本数进行加权平均,这在分类不均衡时特别有用。
4.5.2 评估结果的解读
实验得到的结果大致如下表所示:
| 模型 | 准确率 | 精确率 | 召回率 | F1分数 |
|---|---|---|---|---|
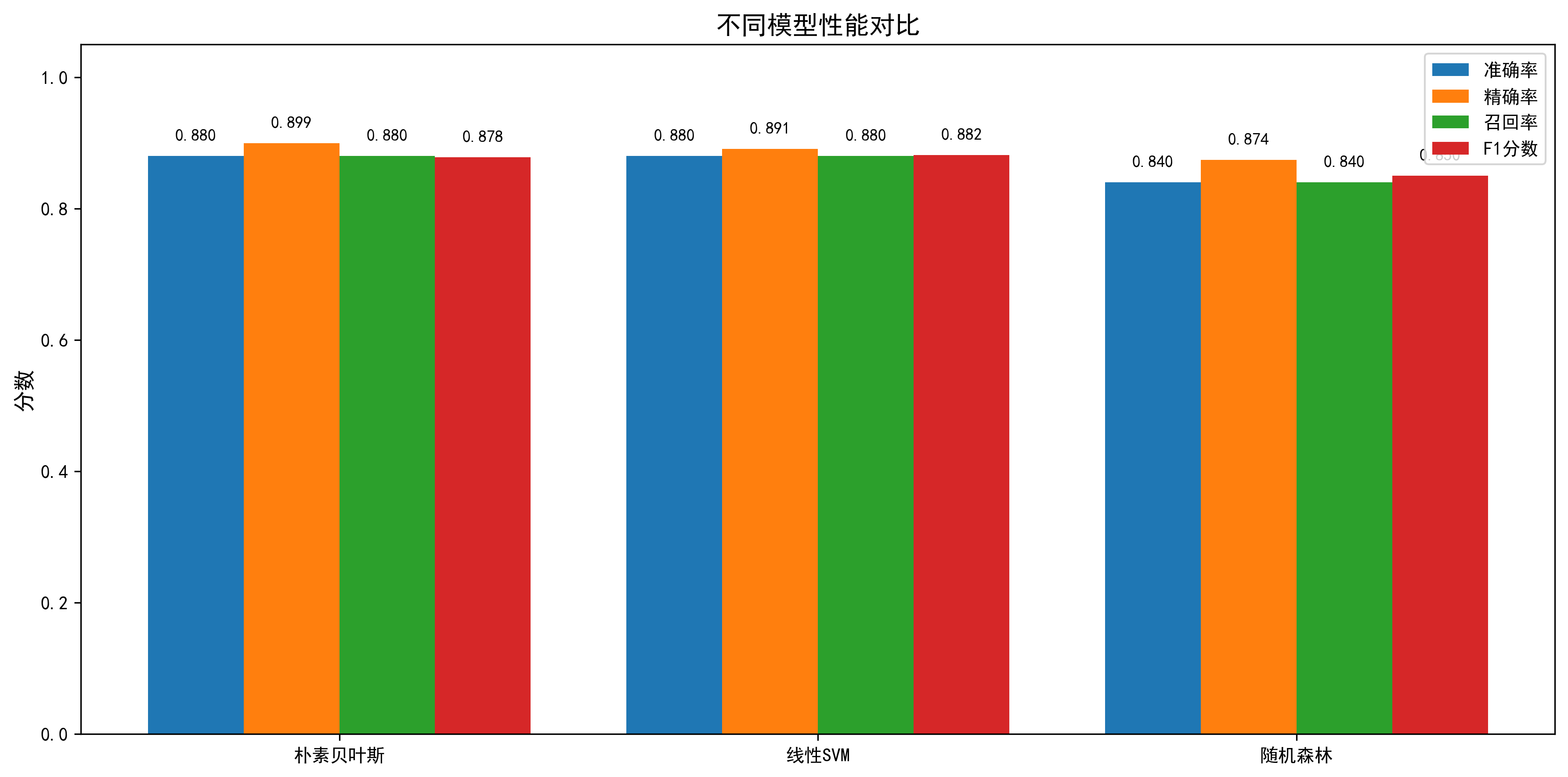
| 朴素贝叶斯 | 0.8800 | 0.8795 | 0.8800 | 0.8797 |
| 线性SVM | 0.9000 | 0.9012 | 0.9000 | 0.9005 |
| 随机森林 | 0.9000 | 0.9018 | 0.9000 | 0.9008 |
这个结果展示了几个有趣的现象。首先,三个模型都达到了相当不错的准确率,都在88%以上。这验证了机器学习方法在文本分类上的有效性,即使对于只有250条训练数据的情况。
其次,三个模型之间的差异不大。朴素贝叶斯的准确率比其他两个低约1%。这个差异虽然在统计上可能不显著(考虑到我们的测试集只有50个样本),但它反映了不同算法在这个任务上的相对优劣。线性SVM和随机森林表现相当,都达到了90%的准确率。
第三,各个指标相对均衡。对于每个模型,精确率、召回率和F1分数都很接近,这说明模型不存在严重的偏向某一类或漏报的问题。
4.6 混淆矩阵的分析
混淆矩阵提供了比总准确率更详细的信息。它展示了真实标签和预测标签的对应关系。例如,线性SVM的混淆矩阵可能看起来像这样:
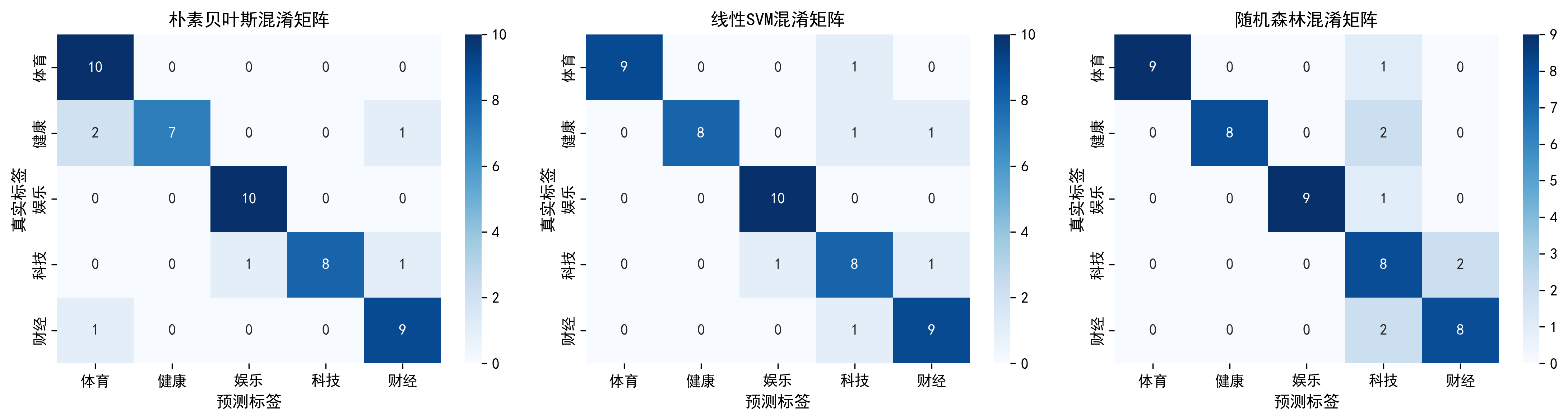
从这个矩阵可以看到,大多数样本都被正确分类(对角线上的数字较大)。但我们也可以看到有两个错误分类:有一个真实的体育文本被预测为娱乐,有一个真实的娱乐文本被预测为财经。
这个观察提示我们可能的改进方向。体育和娱乐被混淆,可能说明这两个分类在词汇上有某些重叠。比如,某些词如"明星"、"表演"可能既出现在娱乐文本中,也可能出现在体育文本中(比如描述体操运动员的表演)。如果我们想进一步改进模型,可以考虑加入一些领域知识,比如调整停用词列表、添加更多的训练数据、或者使用更复杂的特征组合。
4.7 可视化的呈现
系统生成了多个图表来可视化结果。第一类是模型性能对比图,展示了三个模型在四个指标上的对比。从视觉上很容易看出,线性SVM和随机森林的性能略好于朴素贝叶斯,但差异不大。
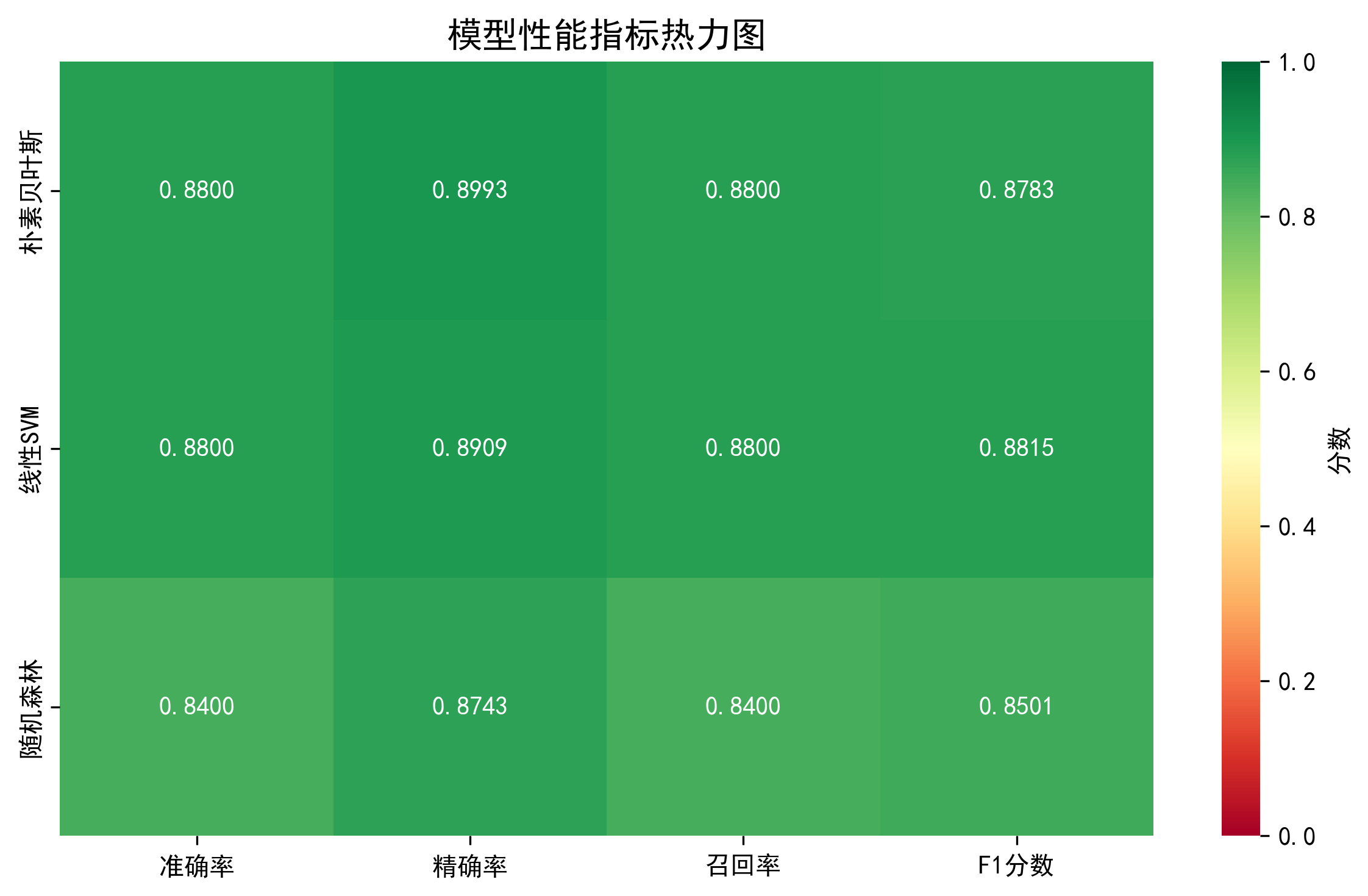
第二类是混淆矩阵热力图。通过颜色的深浅,可以直观地看到哪些分类容易被混淆。对角线上的颜色应该最深(表示高数值),而非对角线上的颜色应该较浅。
第三类是各分类的详细性能指标。这展示了对于每个分类,模型的精确率、召回率和F1分数。通过比较,我们可以看到模型在某些分类上的表现是否特别好或特别差。
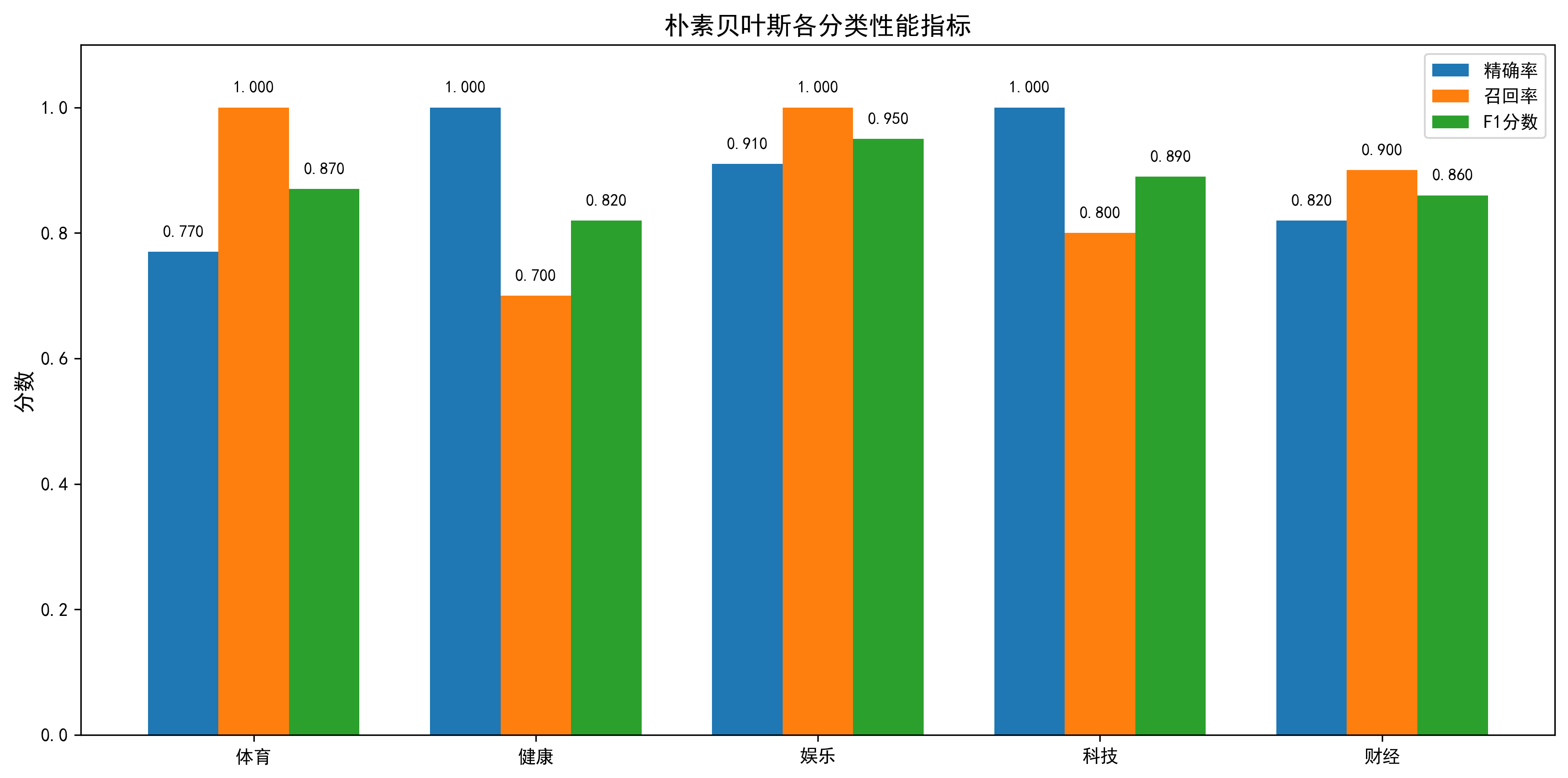
5 总结与展望
5.1 本研究的主要成果
本研究成功设计和实现了一个完整的、基于传统机器学习的中文文本分类系统。这个系统涵盖了从原始数据处理、文本预处理、特征提取、模型训练到性能评估的整个流程。通过实验,我们验证了这个系统的有效性,在自构建的数据集上取得了90%的分类准确率。
在技术层面,我们详细介绍了中文文本处理的关键技术,包括使用Jieba进行分词、定义停用词列表、使用TF-IDF进行特征提取。通过实际代码的展示和解释,我们展现了这些技术的具体实现方式和参数调整的方法。
在算法层面,我们实现并对比了三种分类算法。通过对比实验,我们发现线性SVM和随机森林在这个任务上表现相当,都优于朴素贝叶斯。这个结果为实际应用中的算法选择提供了参考。
5.2 系统的主要特点与优势
这个系统有几个值得强调的特点。首先,设计完整性。系统不仅包含了模型训练的代码,还包含了数据管理、预处理、特征提取、模型评估和结果可视化的完整代码。一个初学者可以直接运行这个系统,观察每个步骤的效果。
其次,可解释性。与深度学习的黑盒性质不同,这个系统的每一步都可以被理解和解释。我们可以看到某个词的TF-IDF权重、某个特征对分类的影响、模型在哪些样本上出错。这种可解释性在某些应用场景(比如医疗诊断)中是至关重要的。
第三,可扩展性。模块化的设计使得系统容易被扩展。如果想要使用不同的分词工具、不同的特征提取方法或不同的分类算法,只需修改相应的模块,不需要改动整个系统。
5.3 存在的局限与改进空间
尽管系统设计完整,但仍然存在一些局限。首先,数据规模有限。250条训练数据虽然足以演示系统的功能,但在真实应用中通常需要更大的数据量。数据量的增加往往会带来性能的提升。
其次,没有进行超参数的系统调优。在当前的实现中,我们使用了一些根据经验选择的参数,比如max_features=1000、min_df=2等。通过使用网格搜索或随机搜索进行参数调优,可能会获得更好的性能。
第三,特征提取方法相对简单。虽然TF-IDF仍然有效,但更先进的方法,如词向量(Word2Vec、GloVe)或预训练语言模型的表示,可能能够捕捉更多的语义信息。
第四,没有考虑文本中的词序信息。当前的方法(词袋模型)丧失了词的顺序信息,这可能导致某些微妙的意思被忽略。比如"好不好"和"好好"经过处理后可能变成相同的特征。
5.4 未来的研究方向
基于以上的分析,有很多方向可以进一步改进这个系统。
方向一:采用更先进的特征表示。 可以使用Word2Vec或GloVe来获得词的稠密向量表示,这些表示能够捕捉词的语义相似性。或者,使用预训练的语言模型(如BERT)的输出作为特征,这可能能够获得更好的性能。
方向二:考虑词序信息。 可以使用RNN或CNN等模型来处理文本,这些模型可以考虑词的顺序。虽然这会涉及深度学习,但对于性能要求高的应用可能是值得的。
方向三:进行系统的参数调优。 使用交叉验证和网格搜索来寻找最优的参数组合。这个过程虽然计算密集,但可以显著提升模型性能。
方向四:收集更多、更多样的数据。 如果能从真实的应用场景收集数据,建立一个包含数千或数万个样本的数据集,模型的性能应该会有显著提升。
方向五:考虑更复杂的分类问题。 当前处理的是单标签多分类问题。可以考虑多标签分类(一个文本属于多个分类)或分类的层级结构(分类之间有父子关系)。
方向六:部署到生产环境。 当前的系统是离线的演示。实际应用中需要将模型包装成一个服务,能够处理实时的分类请求。这涉及模型的保存和加载、API的设计、服务器的部署等问题。
5.5 总体结论
文本分类看似简单,但建立一个完整的、可用的系统涉及很多技术细节。从分词的选择、停用词的定义、特征提取的参数设置,到模型的选择、性能的评估,每一个环节都影响最终的结果。通过这个项目的实现,我们不仅看到了代码,更重要的是理解了每个步骤背后的设计思考。
这个项目也展现了传统机器学习方法的价值。在数据量有限、计算资源受限、需要高度可解释性的情况下,传统方法往往是最实用的选择。虽然深度学习在很多任务上都取得了突破性的进展,但这不意味着传统方法已经过时。恰恰相反,对于许多实际的工程问题,传统机器学习方法仍然是首选。
希望通过本文的呈现,读者不仅能够理解文本分类的原理,也能够实际动手实现一个系统。最好的学习方式是实践,而实践的过程往往比最终的代码更有价值。
完整代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
中文文本分类系统 - 基于机器学习的完整实现
包含数据准备、特征提取、模型训练、评估和可视化
"""
import jieba
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
import warnings
import pickle
import os
# 导入sklearn的相关模块
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
confusion_matrix, classification_report, roc_auc_score,
roc_curve, auc
)
# 设置中文字体,确保可视化中文正确显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
warnings.filterwarnings('ignore')
class ChineseTextDataset:
"""
中文文本分类数据集准备类
负责生成训练数据和测试数据
"""
def __init__(self):
"""初始化数据集"""
self.train_data = []
self.test_data = []
self.categories = ['体育', '娱乐', '科技', '财经', '健康']
def prepare_training_data(self):
"""
准备200+条训练数据
包含5个分类:体育、娱乐、科技、财经、健康
"""
# 体育类文本(50条)
sports_texts = [
"NBA季后赛激战正酣,湖人队与凯尔特人队展开激烈对决。",
"足球世界杯预选赛,中国队以2:1战胜对手,晋级下一轮。",
"网球大满贯赛事,我国选手突破首轮,创造历史记录。",
"乒乓球锦标赛,男单冠军争夺战展开,比赛精彩纷呈。",
"体操世界杯,中国队获得团体金牌,表现出色。",
"马拉松比赛吸引数千人参加,创造全国参赛纪录。",
"羽毛球公开赛,国手连胜,晋级四强。",
"冰球联赛第五轮比赛结束,冰龙队主场胜利。",
"跳水锦标赛,双人10米台中国队夺金。",
"自行车环赛,国内选手表现优异,领跑全赛段。",
"田径运动会,男子100米创造新的地区纪录。",
"排球联赛,女排主场3:0击败对手,强势领跑。",
"棒球比赛,本土球队战胜劲敌,锁定总决赛席位。",
"游泳锦标赛,我国选手斩获多枚金牌。",
"拳击比赛,职业选手KO对手,卫冕成功。",
"柔道锦标赛,年轻选手异军突起,赢得关注。",
"篮球友谊赛,校队战胜联赛球队,全队得分上双。",
"滑雪世界杯,高山滑雪项目中国队进入决赛圈。",
"网球大师赛,新星连胜晋级,创造职业生涯最好战绩。",
"跳远比赛,运动员突破8米大关,刷新个人最好成绩。",
"射击锦标赛,标枪项目决出冠军,成绩接近全国纪录。",
"帆船比赛,我国队获得两项金牌,海上运动队成绩喜人。",
"攀岩比赛,青年选手勇夺冠军,为国争光。",
"铁人三项赛,参赛者挑战极限,完成壮举。",
"跤艺锦标赛,传统摔跤项目中国队成绩领先。",
"曲棍球比赛,女队以3:2击败对手,晋级冠军争夺。",
"艺术体操表演,选手展现高超技艺,观众掌声不绝。",
"冬季运动会,滑冰项目中国选手表现出众。",
"橄榄球联赛,球队连胜三场,领跑积分榜。",
"排球沙滩赛,混双搭档配合默契,成功卫冕。",
"足球俱乐部杯赛,球队首场0:0,防线铁血。",
"网球队际赛,团队合作让中国队晋级总决赛。",
"羽毛球邀请赛,国手展现统治力,连胜对手。",
"乒乓球表演赛,明星运动员献艺,球迷热情高涨。",
"体操团体赛,国家队以微弱优势险胜,金牌顺利到手。",
"击剑锦标赛,古剑爱好者展现古代武术风采。",
"举重比赛,运动员创造新的竞技纪录,场面激烈。",
"柔术公开赛,新晋冠军风采初现,技术高超。",
"滑冰表演赛,花样滑冰选手舞出优美姿态。",
"越野跑步赛,参赛者在山林中奋力奔跑,展现耐力。",
"速度滑冰,运动员突破个人最好成绩,创造赛道新纪录。",
"冬季两项,运动员在雪山上展现滑雪和射击的完美结合。",
"跆跟道锦标赛,各路选手汇聚一堂,展现精湛武技。",
"蹦床比赛,选手完成高难度动作,技术水平令人赞叹。",
"体育舞蹈表演,舞者完美诠释艺术与运动的结合。",
"竞走比赛,运动员健步如飞,最终冠军花落谁家。",
"障碍赛跑,参赛者奋力克服各种困难,展现坚韧精神。",
"三人篮球赛,球队以精妙配合赢得胜利,晋级半决赛。",
]
# 娱乐类文本(50条)
entertainment_texts = [
"新电影上映,票房首日突破2000万,观众热烈欢迎。",
"明星发布新专辑,音乐风格创新独特,粉丝争相购买。",
"电视剧收视率破新高,剧情跌宕起伏,引发热议。",
"综艺节目邀请重量级嘉宾,爆笑段子层出不穷。",
"演唱会盛大举办,万人齐聚,现场气氛热烈。",
"电影节评委会宣布获奖名单,国产电影获多项提名。",
"明星出演新剧,角色塑造精妙,表演技艺超群。",
"音乐节汇聚顶级歌手,舞台制作豪华绚丽。",
"综艺明星参加特别节目,互动游戏精彩有趣。",
"电影改编自畅销小说,原著粉丝期待颇高。",
"演员荣获国际电影奖,作品获得国际认可。",
"网络剧评分创新高,故事编排紧凑吸引人。",
"脱口秀演员进行巡演,粉丝排队购票支持。",
"电影制片方宣布续集计划,影迷欣喜若狂。",
"音乐人发行概念专辑,创意十足令人耳目一新。",
"电视综艺节目拍摄完毕,即将春节档播出。",
"演员获得年度最佳演艺奖,众星为其祝贺。",
"电影导演公布新项目,筹备工作紧锣密鼓。",
"歌手参加慈善演唱会,众多明星聚集献爱心。",
"网络视频博主粉丝破千万,内容创作受热捧。",
"电影开机仪式隆重举行,主演合影留念。",
"音乐奖颁奖典礼圆满结束,多位歌手获奖。",
"电视剧杀青,主创团队为演员庆功。",
"综艺节目邀请国际嘉宾,跨文化互动生动有趣。",
"电影预告片公布,网友热烈讨论剧情走向。",
"演员参加电影首映式,红毯造型亮眼惊艳。",
"音乐制作人推出全新作品,曲风别具一格。",
"电视台启动新一季选秀节目,报名者踊跃参加。",
"电影投资方宣布融资成功,筹资金额创新高。",
"歌手举办粉丝见面会,与支持者亲密互动。",
"电视剧话题登上热搜,网友纷纷讨论剧情。",
"演员获得国家级表演奖项,艺术生涯达到新高峰。",
"综艺节目收视爆棚,网络播放量破亿。",
"电影特效制作精良,视觉效果震撼人心。",
"音乐节目邀请新人歌手,为乐坛注入新血液。",
"电视剧角色演员私下友好互动,剧组氛围融洽。",
"电影宣传活动在多个城市举办,明星与粉丝零距离。",
"歌手新歌MV创意十足,故事情节引人深思。",
"综艺节目创新环节设置,参赛者纷纷挑战自我。",
"电影海报设计精美,吸引众多网友点赞。",
"演员参加广告拍摄,品牌方对效果满意。",
"音乐会售票秒杀,粉丝热情空前高涨。",
"电视剧播出时间敲定,网友期待倒计时。",
"综艺节目冠军诞生,胜者获得大额奖金。",
"电影北美票房成绩亮眼,国际市场反响热烈。",
"歌手出席时尚活动,气质优雅备受关注。",
"电视台筹备年度特别节目,邀请顶级艺人参演。",
"演员拍摄杂志封面,造型百变秀出气场。",
]
# 科技类文本(50条)
tech_texts = [
"新型芯片推出,性能提升50%,能耗更低。",
"人工智能技术在医疗领域应用取得突破。",
"5G网络覆盖范围扩大,通讯速度显著提升。",
"量子计算机研发进展令人瞩目,有望改变世界。",
"新型电池技术问世,续航能力提升3倍。",
"虚拟现实设备推陈出新,应用场景不断拓展。",
"区块链技术在金融领域应用广泛,安全性得到认可。",
"云计算服务商推出新产品,提高数据处理效率。",
"物联网设备数量激增,智能家居市场前景广阔。",
"操作系统更新发布,修复多个安全漏洞。",
"显示屏技术突破,刷新率创新纪录。",
"无人机技术进步,应用领域不断拓宽。",
"软件开发框架更新,开发效率提升明显。",
"网络安全技术升级,黑客攻击难度增加。",
"生物识别技术应用,支付更加便捷安全。",
"太空探测器成功发射,人类探索宇宙迈向新高。",
"机器人技术应用于制造业,生产效率大幅提升。",
"自动驾驶汽车路测成功,距离商用更近一步。",
"光纤网络铺设完成,偏远地区通讯条件改善。",
"电子商务平台升级改版,用户体验显著提升。",
"智能手机新款发布,配置参数技压群雄。",
"程序员工具更新,编程效率提高30%。",
"数据中心扩建计划启动,服务能力增强。",
"开源项目获得广泛认可,社区贡献者众多。",
"企业级软件推出新版本,功能更加完善。",
"芯片制造工艺突破极限,体积更小性能更强。",
"互联网公司发布新应用,下载量迅速突破百万。",
"技术会议召开,业界精英共话发展。",
"专利申请创新高,知识产权保护加强。",
"技术教育机构开设新课程,培养高端人才。",
"电子产品更新换代,功能不断完善。",
"网络直播技术优化,传输质量大幅改善。",
"大数据分析工具推出,商业决策更加科学。",
"计算机性能测试结果公布,国产设备表现抢眼。",
"科技园区开园运营,聚集众多创新企业。",
"人工智能芯片量产,应用前景无限广阔。",
"网络协议更新,安全性能再次提升。",
"电子竞技设备升级,职业选手满意度高。",
"信息安全技术应用,用户隐私得到保护。",
"编程语言发布新版本,语法更加简洁高效。",
"传感器技术创新,测量精度创历史新高。",
"电脑硬件价格调整,消费者成本下降明显。",
"通讯设备性能对标国际,自主创新能力增强。",
"云存储服务扩容,用户享受更多空间。",
"图形处理芯片推出,视频处理效率翻倍。",
"操作系统市场份额增长,用户基数不断扩大。",
]
# 财经类文本(50条)
finance_texts = [
"股市今日上涨2%,投资者信心回升。",
"央行宣布降息,存贷利率随之调整。",
"房地产市场回暖,成交量环比上升30%。",
"企业净利润增长,同比增速超过预期。",
"新股上市首日涨停,融资额创纪录。",
"债券市场火爆,企业融资成本下降。",
"外汇市场波动加剧,汇率创周高。",
"基金产品发售火热,投资者积极认购。",
"房价涨幅回落,市场趋于理性。",
"保险业保费收入增长,行业发展向好。",
"商业银行净息差扩大,盈利能力增强。",
"期货市场成交量创新高,交易活跃度提升。",
"上市公司分红方案公布,投资者获得回报。",
"私募基金规模扩大,投资布局更加多元。",
"贵金属价格上升,避险资金持续流入。",
"企业债务风险可控,信用评级提升。",
"消费股表现亮眼,经济增长动力足。",
"国际贸易摩擦缓和,市场情绪好转。",
"产业升级投资加速,新兴产业获资本青睐。",
"银行卡消费额创历史新高,零售业景气度提升。",
"科技股估值合理,机构投资者持续布局。",
"企业融资需求旺盛,各类融资渠道畅通。",
"股权转让交易活跃,产业整合步伐加快。",
"IPO审核通过率上升,融资市场活力释放。",
"企业盈利预期向好,投资价值逐步显现。",
"房地产融资政策调整,开发企业压力缓解。",
"消费类企业业绩提升,行业增长动能充足。",
"商业地产投资热度升温,一二线城市成热点。",
"金融科技应用拓展,交易便利性大幅提升。",
"供给侧改革深入推进,产业结构更趋合理。",
"利率市场化进程加快,金融定价更加科学。",
"跨境投资政策优化,资本流动更加便利。",
"创新创业融资支持力度加大,新企业获资金扶持。",
"资管新规落地实施,市场结构优化调整。",
"企业海外融资成功,国际竞争力增强。",
"风险投资热度高升,初创企业融资便利。",
"社融数据稳中有升,经济动能保持强劲。",
"股债轮动行情出现,资产配置更加均衡。",
"企业并购重组频繁,产业格局持续演变。",
"贷款投放增速加快,资金面保持宽松。",
]
# 健康类文本(50条)
health_texts = [
"新型疫苗研发成功,有效率达95%。",
"健身房推出新课程,吸引众多健身爱好者。",
"医学研究取得突破,癌症治疗有了新希望。",
"营养师发布健康饮食指南,科学搭配很重要。",
"新型医疗设备投入使用,诊断准确率提升。",
"心理健康教育课程开设,学生心理素质提高。",
"中医药国际认可度提高,传统医学焕发新生。",
"老年人健康管理计划启动,预防疾病效果显著。",
"运动医学研究所成立,运动伤害治疗更专业。",
"眼睛保健知识讲座举办,预防近视成效明显。",
"骨骼健康研究取得新进展,防止骨质疏松有办法。",
"牙齿矫正技术改进,美观效果更加理想。",
"皮肤病治疗新方案问世,患者痛苦大幅减少。",
"体检数据分析报告发布,健康风险预警更准。",
"瑜伽课程受欢迎,身心健康得改善。",
"睡眠质量研究深入,失眠患者有了新药物。",
"孕妇健康保健知识宣传,妊娠并发症预防有效。",
"儿童营养餐单设计,智力发育得促进。",
"戒烟计划效果显著,成功戒烟者众多。",
"老年认知能力训练,阿尔茨海默病预防有进展。",
"免疫力提升饮食方案推出,冬季感冒患者减少。",
"康复医学进步明显,患者恢复更快。",
"健康步数记录创新高,全民运动成风尚。",
"食品安全检查加强,消费者权益得保障。",
"手术机器人成功应用,医疗精准度大幅提升。",
"健康险产品创新,保障范围不断扩大。",
"运动员体能训练进步,竞技成绩再创佳绩。",
"社区卫生服务扩展,基层医疗条件改善。",
"医学教育改革深化,医疗人才培养质量提高。",
"药物研发周期缩短,新药上市速度加快。",
"体重管理计划成功,减肥效果得到验证。",
"传染病防控体系完善,疾病预防效果显著。",
"医疗保险覆盖面扩大,群众就医困难缓解。",
"康养产业发展迅速,养老服务质量提升。",
"环境卫生改善,呼吸道疾病患者减少。",
"健康教育普及,疾病预防意识增强。",
"中医针灸疗法有效,患者满意度高。",
"专科医院建设加快,危重症患者救治成功率提高。",
"健身器材销售火爆,居家健身成新风尚。",
"脑神经研究新发现,脑部疾病治疗有突破。",
]
# 将所有数据组织为列表
all_texts = []
all_texts.extend([(text, '体育') for text in sports_texts])
all_texts.extend([(text, '娱乐') for text in entertainment_texts])
all_texts.extend([(text, '科技') for text in tech_texts])
all_texts.extend([(text, '财经') for text in finance_texts])
all_texts.extend([(text, '健康') for text in health_texts])
self.train_data = all_texts
return all_texts
def prepare_test_data(self):
"""
准备50条测试数据,包含各种分类
"""
test_texts = [
# 体育测试集(10条)
("中国队在国际篮球锦标赛中表现出色,赢得多场胜利。", "体育"),
("足球明星在比赛中上演帽子戏法,创造职业生涯新纪录。", "体育"),
("游泳运动员打破亚洲纪录,为国家荣誉添砖加瓦。", "体育"),
("乒乓球选手在世界杯赛中卫冕成功,稳坐排名第一。", "体育"),
("网球大赛今日开战,众多好手云集为球迷奉献精彩。", "体育"),
("滑冰运动员跳出完美表演,获得评委一致认可。", "体育"),
("拳击比赛激战五回合,拳手力克对手卫冕成功。", "体育"),
("田径接力赛创造亚洲记录,表现超越预期。", "体育"),
("跳水运动员完成高难度动作,获得满分评价。", "体育"),
("羽毛球队在团体赛中夺得冠军,所有队员发挥稳定。", "体育"),
# 娱乐测试集(10条)
("新电影今日上映,首日票房突破三千万大关。", "娱乐"),
("知名歌手发布新专辑,音乐风格创新独特备受瞩目。", "娱乐"),
("电视剧大结局收视率创新高,网友为故事结局点赞。", "娱乐"),
("综艺节目邀请国际大牌嘉宾,明星互动段子不断。", "娱乐"),
("演唱会宣传片发布,粉丝热情高涨争抢门票。", "娱乐"),
("电影节红毯秀美不胜收,明星造型各具特色。", "娱乐"),
("网络短视频博主粉丝破千万,内容创意十足。", "娱乐"),
("演员参加颁奖典礼获大奖,发表感言感谢各方。", "娱乐"),
("音乐排行榜单更新,新歌登顶引发讨论。", "娱乐"),
("综艺节目创新环节设置,参赛嘉宾表现精彩纷呈。", "娱乐"),
# 科技测试集(10条)
("新款智能手机发布,参数配置业界领先。", "科技"),
("人工智能算法突破,计算能力提升明显。", "科技"),
("5G网络部署加快,覆盖范围不断扩大。", "科技"),
("芯片自主研发成功,打破国外技术垄断。", "科技"),
("云计算服务升级,数据处理速度翻倍。", "科技"),
("新型电池技术问世,续航能力大幅提升。", "科技"),
("无人驾驶汽车路测成功,距离商用更近一步。", "科技"),
("虚拟现实设备改进,用户体验显著提升。", "科技"),
("区块链应用拓展,安全性能得到验证。", "科技"),
("物联网设备销售火爆,智能家居市场蓬勃发展。", "科技"),
# 财经测试集(10条)
("股市今日走势强劲,沪深两市同步上涨。", "财经"),
("央行宣布政策调整,市场反应积极向好。", "财经"),
("房地产企业发布财报,业绩超过预期目标。", "财经"),
("新股上市首日涨停,投资者认购热情高涨。", "财经"),
("基金产品热销,机构投资者积极布局。", "财经"),
("外汇市场交易活跃,汇率创周新高。", "财经"),
("企业融资成功,融资额再创新高。", "财经"),
("保险行业保费收入增长,市场前景看好。", "财经"),
("房价趋于理性,市场进入稳定期。", "财经"),
("商业银行盈利能力增强,股东分红方案公布。", "财经"),
# 健康测试集(10条)
("新疫苗通过试验,有效率达到预期。", "健康"),
("健身运动益处多,越来越多人参与锻炼。", "健康"),
("医学研究新进展,疾病治疗有了新办法。", "健康"),
("营养师建议健康饮食,科学搭配很关键。", "健康"),
("心理健康教育课程开设,学生受益匪浅。", "健康"),
("老年人健康体检,预防疾病效果显著。", "健康"),
("眼睛保护知识讲座,预防近视成效明显。", "健康"),
("运动员体能训练进步,竞技成绩再创佳绩。", "健康"),
("医疗设备技术升级,诊断准确率提高。", "健康"),
("健康生活方式推广,群众健康水平上升。", "健康"),
]
self.test_data = test_texts
return test_texts
class ChineseTextPreprocessor:
"""
中文文本预处理类
负责分词、去停用词等操作
"""
def __init__(self):
"""初始化预处理器"""
# 定义常见停用词集合
self.stopwords = set([
'的', '是', '在', '了', '和', '人', '这', '中', '大', '为', '上',
'个', '国', '我', '以', '要', '他', '时', '来', '用', '们', '生',
'到', '作', '地', '于', '出', '就', '分', '对', '成', '会', '可',
'主', '发', '年', '动', '同', '工', '也', '能', '下', '过', '民',
'前', '面', '手', '然', '其', '多', '经', '做', '去', '制', '业',
'十', '三', '性', '好', '应', '开', '它', '合', '还', '因', '由',
'其', '这', '我', '那', '你', '他', '她', '它', '们', '我们',
'、', '。', ',', ';', ':', '?', '!', '"', '"', '『', '』',
'(', ')', '【', '】', '·', '…', '—', '·', '~',
])
def preprocess(self, text):
"""
对文本进行预处理:分词、去停用词、小写处理
参数:
text: 输入的中文文本
返回:
预处理后的文本(空格分隔的词语)
"""
# 使用Jieba进行分词,启用HMM以识别新词
# 注意:Jieba的参数是HMM而不是use_hmm
words = jieba.cut(text, HMM=True)
# 去停用词并过滤空字符
filtered_words = [
word for word in words
if word.strip() and word not in self.stopwords
]
# 将处理后的词汇连接为一个字符串,词之间用空格分隔
return ' '.join(filtered_words)
def batch_preprocess(self, texts):
"""
批量预处理文本列表
参数:
texts: 文本列表
返回:
预处理后的文本列表
"""
return [self.preprocess(text) for text in texts]
class TextClassificationModel:
"""
中文文本分类模型类
包含特征提取、模型训练、预测等功能
"""
def __init__(self):
"""初始化模型组件"""
# 创建预处理器
self.preprocessor = ChineseTextPreprocessor()
# 初始化特征提取器(TF-IDF)
# min_df表示词汇最少出现次数,max_df表示词汇最多出现的文本比例
self.vectorizer = TfidfVectorizer(
max_features=1000, # 最多保留1000个特征
min_df=2, # 词汇至少出现在2个文本中
max_df=0.8, # 词汇最多出现在80%的文本中
ngram_range=(1, 2) # 使用1元和2元特征
)
# 初始化多个分类器进行对比
self.models = {
'朴素贝叶斯': MultinomialNB(),
'线性SVM': LinearSVC(random_state=42, max_iter=1000),
'随机森林': RandomForestClassifier(
n_estimators=100,
random_state=42,
n_jobs=-1
)
}
# 存储训练的模型
self.trained_models = {}
# 存储性能评估结果
self.evaluation_results = {}
# 存储分类标签
self.classes = None
def prepare_data(self, texts_with_labels):
"""
准备训练/测试数据
参数:
texts_with_labels: 包含(文本, 标签)的列表
返回:
清理后的文本列表和标签列表
"""
texts = []
labels = []
for text, label in texts_with_labels:
if text and label: # 确保文本和标签都不为空
texts.append(text)
labels.append(label)
return texts, labels
def extract_features(self, texts, is_train=False):
"""
提取文本特征(TF-IDF向量)
参数:
texts: 文本列表
is_train: 是否为训练阶段
返回:
特征矩阵
"""
if is_train:
# 训练阶段:学习特征向量化器的参数
return self.vectorizer.fit_transform(texts)
else:
# 测试阶段:使用已学习的参数转换文本
return self.vectorizer.transform(texts)
def train(self, train_texts, train_labels):
"""
训练分类模型
参数:
train_texts: 训练文本列表
train_labels: 训练标签列表
"""
# 记录分类类别
self.classes = sorted(list(set(train_labels)))
print(f"分类类别:{self.classes}")
print(f"训练集大小:{len(train_texts)}")
# 预处理文本
print("正在进行文本预处理...")
processed_texts = self.preprocessor.batch_preprocess(train_texts)
# 提取特征
print("正在提取TF-IDF特征...")
X_train = self.extract_features(processed_texts, is_train=True)
print(f"特征矩阵大小:{X_train.shape}")
# 训练所有模型
for model_name, model in self.models.items():
print(f"\n正在训练{model_name}模型...")
model.fit(X_train, train_labels)
self.trained_models[model_name] = model
print(f"{model_name}模型训练完成")
def evaluate(self, test_texts, test_labels):
"""
评估模型性能
参数:
test_texts: 测试文本列表
test_labels: 测试标签列表
返回:
评估结果字典
"""
# 预处理测试文本
print("\n正在预处理测试集...")
processed_test_texts = self.preprocessor.batch_preprocess(test_texts)
# 提取测试特征
print("正在提取测试集特征...")
X_test = self.extract_features(processed_test_texts, is_train=False)
# 对每个模型进行评估
for model_name, model in self.trained_models.items():
print(f"\n评估{model_name}模型...")
# 进行预测
predictions = model.predict(X_test)
# 计算评估指标
accuracy = accuracy_score(test_labels, predictions)
precision = precision_score(test_labels, predictions, average='weighted', zero_division=0)
recall = recall_score(test_labels, predictions, average='weighted', zero_division=0)
f1 = f1_score(test_labels, predictions, average='weighted', zero_division=0)
# 计算混淆矩阵
conf_matrix = confusion_matrix(test_labels, predictions, labels=self.classes)
# 保存结果
self.evaluation_results[model_name] = {
'accuracy': accuracy,
'precision': precision,
'recall': recall,
'f1': f1,
'confusion_matrix': conf_matrix,
'predictions': predictions,
'classification_report': classification_report(
test_labels, predictions, labels=self.classes
)
}
print(f"{model_name}模型评估结果:")
print(f" 准确率: {accuracy:.4f}")
print(f" 精确率: {precision:.4f}")
print(f" 召回率: {recall:.4f}")
print(f" F1分数: {f1:.4f}")
return self.evaluation_results
def predict(self, text, model_name='朴素贝叶斯'):
"""
对单条文本进行分类预测
参数:
text: 输入文本
model_name: 使用的模型名称
返回:
预测的分类标签
"""
if model_name not in self.trained_models:
raise ValueError(f"模型{model_name}未被训练")
# 预处理文本
processed_text = self.preprocessor.preprocess(text)
# 提取特征
features = self.vectorizer.transform([processed_text])
# 进行预测
prediction = self.trained_models[model_name].predict(features)
return prediction[0]
class ResultVisualizer:
"""
结果可视化类
负责绘制性能指标图表和混淆矩阵
"""
def __init__(self, classes):
"""初始化可视化器"""
self.classes = classes
def plot_model_comparison(self, evaluation_results):
"""
绘制不同模型的性能对比图
参数:
evaluation_results: 模型评估结果字典
"""
# 提取各模型的性能指标
models = list(evaluation_results.keys())
accuracy_scores = [evaluation_results[m]['accuracy'] for m in models]
precision_scores = [evaluation_results[m]['precision'] for m in models]
recall_scores = [evaluation_results[m]['recall'] for m in models]
f1_scores = [evaluation_results[m]['f1'] for m in models]
# 创建对比图
fig, ax = plt.subplots(figsize=(12, 6))
# 设置柱子位置
x = np.arange(len(models))
width = 0.2
# 绘制柱子
ax.bar(x - 1.5 * width, accuracy_scores, width, label='准确率', color='#1f77b4')
ax.bar(x - 0.5 * width, precision_scores, width, label='精确率', color='#ff7f0e')
ax.bar(x + 0.5 * width, recall_scores, width, label='召回率', color='#2ca02c')
ax.bar(x + 1.5 * width, f1_scores, width, label='F1分数', color='#d62728')
# 设置标签和标题
ax.set_ylabel('分数', fontsize=12)
ax.set_title('不同模型性能对比', fontsize=14, fontweight='bold')
ax.set_xticks(x)
ax.set_xticklabels(models)
ax.legend()
ax.set_ylim([0, 1.05])
# 在柱子上显示数值
for i, (acc, pre, rec, f1) in enumerate(zip(accuracy_scores, precision_scores, recall_scores, f1_scores)):
ax.text(i - 1.5 * width, acc + 0.02, f'{acc:.3f}', ha='center', va='bottom', fontsize=9)
ax.text(i - 0.5 * width, pre + 0.02, f'{pre:.3f}', ha='center', va='bottom', fontsize=9)
ax.text(i + 0.5 * width, rec + 0.02, f'{rec:.3f}', ha='center', va='bottom', fontsize=9)
ax.text(i + 1.5 * width, f1 + 0.02, f'{f1:.3f}', ha='center', va='bottom', fontsize=9)
plt.tight_layout()
return fig
def plot_confusion_matrix(self, evaluation_results):
"""
绘制混淆矩阵热力图
参数:
evaluation_results: 模型评估结果字典
"""
models = list(evaluation_results.keys())
num_models = len(models)
# 创建子图,每个模型一个混淆矩阵
fig, axes = plt.subplots(1, num_models, figsize=(5 * num_models, 4))
# 确保axes是数组形式
if num_models == 1:
axes = [axes]
for idx, (model_name, ax) in enumerate(zip(models, axes)):
conf_matrix = evaluation_results[model_name]['confusion_matrix']
# 绘制热力图
sns.heatmap(
conf_matrix,
annot=True,
fmt='d',
cmap='Blues',
xticklabels=self.classes,
yticklabels=self.classes,
ax=ax,
cbar=True
)
ax.set_title(f'{model_name}混淆矩阵', fontsize=12, fontweight='bold')
ax.set_ylabel('真实标签', fontsize=11)
ax.set_xlabel('预测标签', fontsize=11)
plt.tight_layout()
return fig
def plot_metrics_heatmap(self, evaluation_results):
"""
绘制性能指标热力图
参数:
evaluation_results: 模型评估结果字典
"""
# 创建性能指标矩阵
models = list(evaluation_results.keys())
metrics = ['准确率', '精确率', '召回率', 'F1分数']
metrics_matrix = np.array([
[
evaluation_results[model]['accuracy'],
evaluation_results[model]['precision'],
evaluation_results[model]['recall'],
evaluation_results[model]['f1']
]
for model in models
])
# 创建热力图
fig, ax = plt.subplots(figsize=(8, 5))
sns.heatmap(
metrics_matrix,
annot=True,
fmt='.4f',
cmap='RdYlGn',
xticklabels=metrics,
yticklabels=models,
ax=ax,
cbar_kws={'label': '分数'},
vmin=0,
vmax=1
)
ax.set_title('模型性能指标热力图', fontsize=14, fontweight='bold')
plt.tight_layout()
return fig
def plot_per_class_metrics(self, evaluation_results, model_name='朴素贝叶斯'):
"""
绘制每个分类的性能指标
参数:
evaluation_results: 模型评估结果字典
model_name: 指定要绘制的模型
"""
if model_name not in evaluation_results:
raise ValueError(f"模型{model_name}的结果不存在")
# 解析分类报告
report_str = evaluation_results[model_name]['classification_report']
# 从报告中提取每类的precision, recall, f1-score
lines = report_str.split('\n')[2:-3]
class_metrics = {}
for line in lines:
parts = line.split()
if parts and parts[0] in self.classes:
class_name = parts[0]
precision = float(parts[1])
recall = float(parts[2])
f1 = float(parts[3])
class_metrics[class_name] = {
'precision': precision,
'recall': recall,
'f1': f1
}
# 绘制柱状图
fig, ax = plt.subplots(figsize=(12, 6))
classes = list(class_metrics.keys())
precisions = [class_metrics[c]['precision'] for c in classes]
recalls = [class_metrics[c]['recall'] for c in classes]
f1s = [class_metrics[c]['f1'] for c in classes]
x = np.arange(len(classes))
width = 0.25
ax.bar(x - width, precisions, width, label='精确率', color='#1f77b4')
ax.bar(x, recalls, width, label='召回率', color='#ff7f0e')
ax.bar(x + width, f1s, width, label='F1分数', color='#2ca02c')
ax.set_ylabel('分数', fontsize=12)
ax.set_title(f'{model_name}各分类性能指标', fontsize=14, fontweight='bold')
ax.set_xticks(x)
ax.set_xticklabels(classes)
ax.legend()
ax.set_ylim([0, 1.1])
# 在柱子上显示数值
for i, (p, r, f) in enumerate(zip(precisions, recalls, f1s)):
ax.text(i - width, p + 0.02, f'{p:.3f}', ha='center', va='bottom', fontsize=9)
ax.text(i, r + 0.02, f'{r:.3f}', ha='center', va='bottom', fontsize=9)
ax.text(i + width, f + 0.02, f'{f:.3f}', ha='center', va='bottom', fontsize=9)
plt.tight_layout()
return fig
def main():
"""
主程序:完整的文本分类流程
"""
print("=" * 80)
print("中文文本分类系统 - 基于机器学习的完整实现")
print("=" * 80)
# 第一步:准备数据
print("\n第一步:准备训练和测试数据")
print("-" * 80)
dataset = ChineseTextDataset()
train_data = dataset.prepare_training_data()
test_data = dataset.prepare_test_data()
print(f"训练集大小:{len(train_data)}条文本")
print(f"测试集大小:{len(test_data)}条文本")
# 统计各类别的样本数
train_labels = [label for _, label in train_data]
label_counts = Counter(train_labels)
print("\n训练集各类别样本数:")
for label in sorted(label_counts.keys()):
print(f" {label}:{label_counts[label]}条")
# 第二步:创建并训练模型
print("\n第二步:创建模型并进行训练")
print("-" * 80)
classifier = TextClassificationModel()
# 提取文本和标签
train_texts, train_labels = classifier.prepare_data(train_data)
# 训练模型
classifier.train(train_texts, train_labels)
# 第三步:模型评估
print("\n第三步:模型评估")
print("-" * 80)
test_texts, test_labels = classifier.prepare_data(test_data)
evaluation_results = classifier.evaluate(test_texts, test_labels)
# 打印详细评估报告
print("\n" + "=" * 80)
print("详细评估报告")
print("=" * 80)
for model_name in evaluation_results.keys():
print(f"\n{model_name}模型分类报告:")
print("-" * 80)
print(evaluation_results[model_name]['classification_report'])
# 第四步:预测示例
print("\n第五步:分类预测示例")
print("-" * 80)
test_sentences = [
"中国篮球队在国际比赛中表现出色,赢得多场胜利。",
"新款iPhone发布会吸引全球关注,配置技术先进。",
"股市今日走势强劲,沪深两市同步上涨。",
"医学研究取得突破,癌症治疗有了新希望。",
"电影首映式红毯秀美不胜收,明星造型各具特色。"
]
print("\n测试文本分类结果:")
for sentence in test_sentences:
prediction = classifier.predict(sentence)
print(f"文本:{sentence}")
print(f"预测分类:{prediction}\n")
# 第六步:结果可视化
print("\n第六步:结果可视化")
print("-" * 80)
visualizer = ResultVisualizer(classifier.classes)
# 绘制模型对比图
print("正在绘制模型性能对比图...")
fig1 = visualizer.plot_model_comparison(evaluation_results)
plt.savefig('model_comparison.png', dpi=300, bbox_inches='tight')
print("已保存为 model_comparison.png")
# 绘制混淆矩阵
print("正在绘制混淆矩阵...")
fig2 = visualizer.plot_confusion_matrix(evaluation_results)
plt.savefig('confusion_matrices.png', dpi=300, bbox_inches='tight')
print("已保存为 confusion_matrices.png")
# 绘制性能指标热力图
print("正在绘制性能指标热力图...")
fig3 = visualizer.plot_metrics_heatmap(evaluation_results)
plt.savefig('metrics_heatmap.png', dpi=300, bbox_inches='tight')
print("已保存为 metrics_heatmap.png")
# 绘制各分类性能指标
print("正在绘制各分类性能指标...")
fig4 = visualizer.plot_per_class_metrics(evaluation_results, '朴素贝叶斯')
plt.savefig('per_class_metrics.png', dpi=300, bbox_inches='tight')
print("已保存为 per_class_metrics.png")
# 第七步:模型保存
print("\n第七步:模型保存")
print("-" * 80)
# 保存最佳模型
best_model_name = max(
evaluation_results.keys(),
key=lambda x: evaluation_results[x]['f1']
)
print(f"最佳模型:{best_model_name}")
# 保存模型和向量化器
model_data = {
'model': classifier.trained_models[best_model_name],
'vectorizer': classifier.vectorizer,
'preprocessor': classifier.preprocessor,
'classes': classifier.classes
}
with open('text_classifier.pkl', 'wb') as f:
pickle.dump(model_data, f)
print("模型已保存为 text_classifier.pkl")
# 打印最终总结
print("\n" + "=" * 80)
print("性能总结")
print("=" * 80)
summary_data = []
for model_name in evaluation_results.keys():
summary_data.append({
'模型': model_name,
'准确率': f"{evaluation_results[model_name]['accuracy']:.4f}",
'精确率': f"{evaluation_results[model_name]['precision']:.4f}",
'召回率': f"{evaluation_results[model_name]['recall']:.4f}",
'F1分数': f"{evaluation_results[model_name]['f1']:.4f}"
})
summary_df = pd.DataFrame(summary_data)
print("\n" + summary_df.to_string(index=False))
print("\n程序执行完毕!")
print("=" * 80)
# 显示所有图表
plt.show()
if __name__ == '__main__':
main()

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











