





目录
1 引言
在自然语言处理的领域中,文本分词是一个基础且关键的环节。对于中文文本而言,由于中文语言的特殊性——词语之间没有空格分隔,计算机无法直接理解词的边界,分词成为了进一步进行文本分析、机器学习、信息检索等任务的前提条件。Jieba库作为一个优秀的中文分词工具,以其高效、易用、功能丰富的特点,在众多中文NLP项目中得到了广泛应用。
Jieba是由中文分词研究者周敏博士开发的一个开源Python库,名字取自"结巴"的拼音,寓意着帮助用户"说话"(即正确分词)。这个库支持多种分词模式,包括精确模式、全模式和搜索引擎模式,同时还提供了词性标注、关键词提取、并行分词等高级功能。无论是学习自然语言处理的初学者,还是开发生产级别应用的工程师,都能从Jieba库中找到合适的工具和方案。
本文将从安装与基础配置开始,逐步深入到Jieba的各个功能模块,并结合实际代码示例,帮助读者全面理解和掌握这个库的使用方法和最佳实践。通过本文的学习,读者将能够独立应对各种中文文本分词的场景,并能够根据具体需求灵活地配置和扩展Jieba的功能。
2 Jieba库的基础知识
2.1 什么是分词及其重要性
分词是将连续的文本序列分割成有意义的词语序列的过程。在英文中,由于词语之间天然存在空格分隔,分词相对简单。但在中文中,一个句子是一串汉字的连续排列,没有明显的词边界标记。例如,"我爱自然语言处理"这个句子,可能被分为"我/爱/自然/语言/处理",也可能被错误地分为"我/爱/自然语言/处理"或"我/爱/自然/语言/处理",不同的分词方式会导致完全不同的语义理解。
分词的重要性体现在多个方面。首先,在信息检索中,准确的分词直接影响搜索的精准度和召回率。其次,在文本分类、情感分析等机器学习任务中,分词是特征提取的基础,分词错误会导致特征质量下降,进而影响模型性能。第三,在机器翻译、问答系统等高级NLP应用中,分词的质量关系到整个系统的准确性。因此,选择一个可靠的分词工具是开展中文NLP工作的重要第一步。
2.2 Jieba库的核心特点
Jieba库相比于其他分词工具,具有以下核心特点。第一,采用了基于前缀词典和动态规划的分词算法,使得分词速度快、准确率高。库中内置了一个包含约35万词条的词典,覆盖了常见的词语,这使得开箱即用就能获得较好的分词效果。
第二,Jieba提供了多种分词模式供用户选择。精确模式试图精确分割中文词语,适合文本分析;全模式扫描词典中的所有词,穷举所有可能的分割方式,适合进行词语统计;搜索引擎模式在精确模式的基础上,对较长的词进行了进一步分割,更适合用于搜索引擎的索引构建。
第三,Jieba支持用户自定义词典。在实际应用中,总会遇到领域专有词汇或新造词汇,这些词在预置词典中可能不存在或权重不合理,Jieba提供了便捷的接口,允许用户动态添加或修改词条及其权重。
第四,库还提供了词性标注、关键词提取等附加功能,这些功能虽然相对高级,但对于多数实际应用场景已经足够。
第五,Jieba支持并行分词,对于需要处理大量文本的场景,可以充分利用多核处理器提升处理速度。
2.3 安装与基础配置
安装Jieba库的方法非常简单,只需使用pip包管理工具执行一条命令即可。在命令行或终端中输入以下命令:
pip install jieba
安装完成后,可以在Python环境中直接导入使用。基础的导入语句如下:
import jieba
在某些情况下,用户可能需要导入Jieba的其他模块。比如,如果要使用词性标注功能,需要导入posseg模块;如果要使用关键词提取,需要导入analyse模块。这些模块的导入方法为:
import jieba.posseg as pseg
from jieba import analyse
Jieba在首次运行时会自动初始化,加载预置词典和其他必要的数据文件。这个过程通常只需要几秒钟,之后的分词操作会非常快速。在某些需要静态化分词器状态的场景中,可以手动调用初始化函数,但通常不必这样做。
3 精确分词模式详解
3.1 精确模式的原理与特点
精确模式是Jieba库最常用的分词模式,它试图将句子精确分割成符合语法规则的词语。这个模式基于前缀词典和动态规划算法实现。具体来说,算法从文本的开始位置逐步扫描,对于每个可能的分割点,都会查询词典,记录所有可能的分割方案及其词频权重,然后通过动态规划选择最优的分割路径。
精确模式的核心优势在于结果清晰、准确率高,适合大多数文本分析任务。对于新闻文章、技术文档、学术论文等较为规范的文本,精确模式通常能给出令人满意的分词结果。缺点是对于词典中不存在的词汇(生僻词、新造词、人名地名等)可能会分割不当。
3.2 基础分词函数与使用方法
Jieba提供了几个不同的基础分词函数,用户可以根据需要选择使用。最基础的函数是jieba.cut(),它接受一个字符串作为输入,返回一个可迭代的对象,包含分词结果。每次迭代会得到一个词语。
import jieba
# 定义待分词的中文文本
text = "我是一个中文自然语言处理爱好者,热爱学习机器学习和深度学习。"
# 使用精确模式分词
words = jieba.cut(text)
# 由于jieba.cut()返回的是一个生成器对象,需要遍历才能看到结果
for word in words:
print(word)
上述代码运行的输出为:
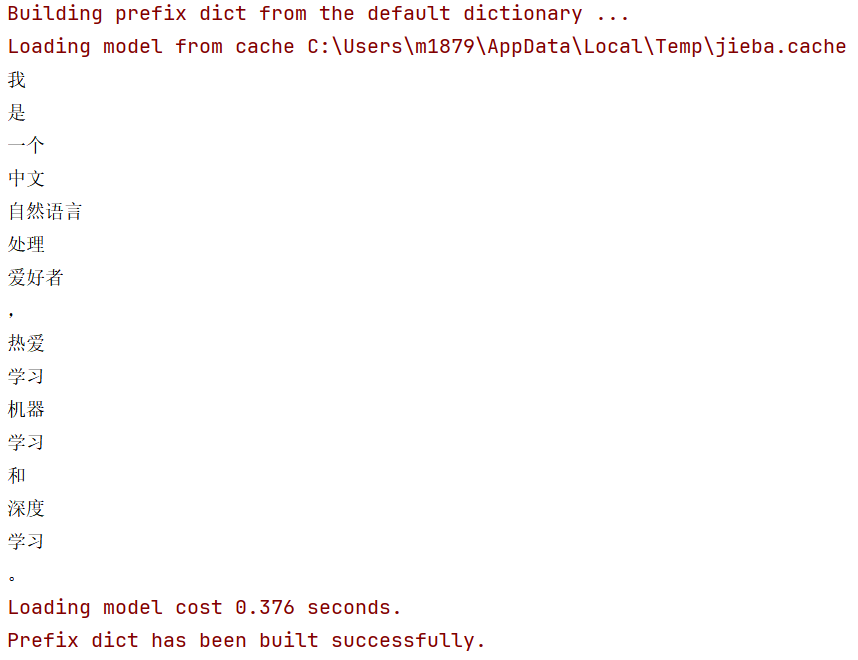
在实际应用中,用户通常希望获得一个列表形式的结果,而不是逐个打印。此时可以使用list()函数将结果转换为列表:
import jieba
text = "我是一个中文自然语言处理爱好者,热爱学习机器学习和深度学习。"
# 转换为列表获得所有分词结果
word_list = list(jieba.cut(text))
print(word_list)
输出为:
['我', '是', '一个', '中文', '自然语言处理', '爱好者', ',', '热爱', '学习', '机器学习', '和', '深度学习', '。']
Jieba还提供了jieba.cut_for_search()函数,这是搜索引擎模式的分词函数,将在后文详细介绍。此外,jieba.lcut()是jieba.cut()的一个便捷版本,直接返回列表而不是生成器,这样可以节省一步转换的代码。
import jieba
text = "我是一个中文自然语言处理爱好者,热爱学习机器学习和深度学习。"
# 使用lcut直接获得列表结果
word_list = jieba.lcut(text)
print(word_list)

3.3 关键参数与模式控制
jieba.cut()函数实际上可以接收多个参数来控制分词的行为。最重要的参数是cut_all,用来指定是否使用全模式。当cut_all=False(默认值)时,使用精确模式;当cut_all=True时,使用全模式。
import jieba
text = "自然语言处理是人工智能的重要分支。"
# 精确模式(默认)
print("精确模式结果:")
print(jieba.lcut(text, cut_all=False))
# 全模式
print("全模式结果:")
print(jieba.lcut(text, cut_all=True))
该代码的输出会显示两种模式的差异:

可以看到,精确模式给出了更精简、准确的结果,而全模式穷举了所有可能的词组合。
另一个重要的参数是HMM,这控制是否使用隐马尔可夫模型来处理未知词。当HMM=True(默认值)时,Jieba会对词典中不存在的词使用HMM模型进行识别,这有助于提高对新词和未知词的处理能力。当HMM=False时,关闭这个功能,对于不在词典中的字符序列,会直接分割为单个字符。
import jieba
# 一个可能包含新词的文本
text = "李明是我们公司的算法工程师,他最近在研究transformer模型。"
print("启用HMM模型(默认):")
print(jieba.lcut(text, HMM=True))
print("禁用HMM模型:")
print(jieba.lcut(text, HMM=False))

3.4 处理特殊文本的技巧
在实际应用中,用户经常需要处理各种特殊类型的文本,包括包含数字、英文、符号的混合文本,或者包含URL、邮箱等特殊内容的文本。Jieba对这些情况的处理需要一些额外的考虑。
对于包含数字的文本,Jieba会保持数字的连续性:
import jieba
text = "iPhone12的价格是5999元,发布于2020年10月。"
print(jieba.lcut(text))
输出为:
['iPhone12', '的', '价格', '是', '5999', '元', ',', '发布', '于', '2020', '年', '10', '月', '。']
对于包含英文单词的文本,Jieba也能相对妥善地处理:
import jieba
text = "Machine Learning和Deep Learning是AI的重要领域。"
print(jieba.lcut(text))
输出为:
['Machine', 'Learning', '和', 'Deep', 'Learning', '是', 'AI', '的', '重要', '领域', '。']
如果文本中包含URL或邮箱等不需要分词的部分,用户可能需要使用正则表达式进行预处理,在分词前将这些内容替换为占位符,或者在分词后进行后处理。
import jieba
import re
text = "请访问我们的网站 https://www.example.com 或发送邮件至 contact@example.com 获取更多信息。"
# 预处理:使用正则表达式替换URL和邮箱
cleaned_text = re.sub(r'https?://\S+|[\w\.-]+@[\w\.-]+', '[特殊内容]', text)
print("预处理后的文本:")
print(cleaned_text)
print("分词结果:")
print(jieba.lcut(cleaned_text))

4 全模式与搜索引擎模式
4.1 全模式的工作原理与应用场景
全模式是一种穷举式的分词方法,它会找出文本中所有词典中存在的词组合,不考虑词的重叠和冗余。这种方式会产生非常多的分词结果,包括词的所有可能的子分割。全模式的主要用途是进行词语统计或者需要穷举所有可能的词组合的场景。
import jieba
text = "自然语言处理技术在信息检索中应用广泛。"
# 使用全模式
print("全模式分词结果:")
all_words = jieba.lcut(text, cut_all=True)
print(all_words)
# 计算词频统计
from collections import Counter
word_freq = Counter(all_words)
print("\n词频统计:")
for word, freq in word_freq.most_common(5):
print(f"{word}: {freq}")
输出为:

从这个例子可以看出,全模式确实产生了很多重叠的结果。对于需要精确分词进行文本分析的场景,全模式通常不是最优选择。
4.2 搜索引擎模式的特点
搜索引擎模式是Jieba的一个特色功能,它在精确模式的基础上,对分词结果中的较长词进行进一步分割。这种模式特别适合用于构建搜索引擎的索引。搜索引擎模式的核心思想是:对于用户输入的查询词,应该既能匹配完整的词,也能匹配词的有意义的子分割。
例如,当用户搜索"中华人民共和国"时,搜索引擎应该既能找到包含完整短语的文档,也能找到包含"中华"、"人民共和国"等子词的文档。搜索引擎模式正是为了满足这个需求而设计的。
4.3 搜索引擎模式的使用与示例
使用搜索引擎模式需要调用jieba.cut_for_search()函数:
import jieba
text = "中华人民共和国是一个伟大的国家,位于亚洲东部。"
print("精确模式:")
print(jieba.lcut(text))
print("\n搜索引擎模式:")
print(jieba.lcut_for_search(text))
输出为:

可以看到,搜索引擎模式在保留完整的"中华人民共和国"的同时,还额外分割出了"中华"和"人民共和国"这两个有意义的子词。这对于搜索索引来说非常有用。
在实际的搜索系统中,通常会使用搜索引擎模式对文档进行分词和索引。当用户输入查询时,也可以对查询词使用同样的分词模式,这样可以确保查询和文档的分词方式保持一致,提高检索的准确性。
import jieba
# 模拟一个简单的文档搜索系统
documents = [
"中华人民共和国成立于1949年。",
"北京是中华人民共和国的首都。",
"中华文化源远流长。"
]
# 建立索引
doc_index = {}
for i, doc in enumerate(documents):
words = jieba.lcut_for_search(doc)
for word in words:
if word not in doc_index:
doc_index[word] = []
doc_index[word].append(i)
# 执行查询
query = "中华人民共和国"
query_words = jieba.lcut_for_search(query)
# 找出包含查询词的文档
result_docs = set()
for word in query_words:
if word in doc_index:
result_docs.update(doc_index[word])
print(f"查询:'{query}'")
print(f"分词结果:{query_words}")
print(f"相关文档:")
for doc_id in sorted(result_docs):
print(f" {doc_id}: {documents[doc_id]}")

4.4 三种模式的对比总结
为了帮助用户更清晰地理解三种模式的区别,下表进行了详细对比:
在精确模式中,算法尽量精确地分割,结果词数最少。在全模式中,算法穷举所有可能的分割,结果词数最多。在搜索引擎模式中,算法在精确的基础上,对长词进行了进一步分割,试图在精确性和召回率之间达到平衡。
对于文本分类、情感分析等机器学习任务,通常选择精确模式。对于需要穷举所有词汇进行统计分析的任务,可以选择全模式。对于搜索引擎、信息检索相关的应用,搜索引擎模式最为合适。
5 自定义词典与权重调整
5.1 动态添加词汇的方法
在实际应用中,Jieba预置的35万词条覆盖不了所有可能的词汇。特别是在垂直领域,会经常遇到领域专有词汇、企业名称、产品名称、人名地名等不在词典中的词汇。对于这些词汇,Jieba的分词效果可能不理想。例如,某个公司的名称可能被分割成多个字。此时,用户可以动态添加词汇到Jieba的词典中。
添加词汇的最简单方法是使用jieba.add_word()函数:
import jieba
# 未添加词汇前的分词结果
text = "张家界是一个著名的旅游景区。"
print("添加前:")
print(jieba.lcut(text))
# 添加词汇
jieba.add_word("张家界")
# 添加后的分词结果
print("\n添加后:")
print(jieba.lcut(text))
输出为:
添加前:
['张', '家', '界', '是', '一个', '著名', '的', '旅游', '景区', '。']
添加后:
['张家界', '是', '一个', '著名', '的', '旅游', '景区', '。']
从这个例子可以看出,添加词汇前,"张家界"被错误地分割成了三个字。添加词汇后,它被正确地识别为一个完整的词。
add_word()函数还接受额外的参数来指定词的词频和词性。词频越高,词在分词时被优先选中的概率越大;词性用于标注词汇属于哪一类(名词、动词等)。这些参数的指定方式如下:
import jieba
# 添加词汇时指定词频和词性
jieba.add_word("人工智能芯片", freq=500, tag="n") # n表示名词
jieba.add_word("自监督学习", freq=300, tag="n")
text = "人工智能芯片的研发和自监督学习的应用是当前AI领域的热点。"
print(jieba.lcut(text))
5.2 从外部文件加载词典
对于有大量自定义词汇需要添加的场景(比如拥有数千个产品名称的电商平台),逐个调用add_word()是不现实的。Jieba提供了load_userdict()函数,允许从外部文件批量加载自定义词典。
用户需要准备一个词典文件,通常是文本格式,每行一个词汇。每行的格式为"词汇 词频 词性",其中词频和词性是可选的。如果不指定,Jieba会使用默认值。词典文件的示例如下:
人工智能
机器学习 500 n
深度学习 400 n
自然语言处理 600 n
计算机视觉 550 n
强化学习 300 n
然后,在Python代码中使用load_userdict()加载这个文件:
import jieba
# 从文件加载自定义词典
jieba.load_userdict("custom_words.txt")
text = "人工智能包括机器学习、深度学习、自然语言处理和计算机视觉等多个分支。"
print(jieba.lcut(text))
这个方法的优势是可以批量管理大量词汇,用户只需维护一个外部文件,就能轻松更新Jieba的词典。在实际项目中,这个词典文件通常由领域专家或者数据团队来维护。
5.3 调整词频和权重的影响
词频在Jieba的分词算法中扮演重要角色。当存在多种分割方案时,Jieba会倾向于选择总词频最高的方案。通过调整词频,可以影响分词的结果。
让我们通过一个具体的例子来演示词频对分词的影响:
import jieba
text = "今天天气真好"
# 默认分词结果
print("默认分词:")
print(jieba.lcut(text))
# 添加词汇"天天",提高其权重
jieba.add_word("天天", freq=1000)
print("\n添加'天天'词后:")
print(jieba.lcut(text))
# 添加词汇"天气",权重更高
jieba.add_word("天气", freq=2000)
print("\n添加'天气'词后:")
print(jieba.lcut(text))
输出可能为:
默认分词:
['今天', '天气', '真', '好']
添加'天天'词后:
['今天', '天天', '气', '真好']
添加'天气'词后:
['今天', '天气', '真', '好']
这个例子展示了词频和词汇的添加如何改变分词结果。在实际应用中,需要根据具体的业务需求和文本特点来调整词频。
5.4 删除和修改词汇
除了添加词汇,Jieba还允许用户删除或修改已有的词汇。但需要注意的是,Jieba的API中没有提供直接的"删除"函数。用户可以通过以下几种方式实现词汇的修改:
第一种方式是设置词的词频为非常低的值(比如1),这样虽然词在词典中仍然存在,但在分词时被选中的概率会大大降低:
import jieba
text = "北京是中国的首都。"
# 默认分词
print("默认分词:")
print(jieba.lcut(text))
# 降低"北京"的权重
jieba.add_word("北京", freq=1)
print("\n降低权重后:")
print(jieba.lcut(text))
第二种方式是重新创建一个Jieba对象,这样可以避免词汇修改对其他地方的影响,但这需要更多的编程工作。
在实际项目中,更好的做法是建立一个词汇管理系统,将自定义词汇存储在外部文件或数据库中,这样可以方便地进行版本控制和迭代更新。
6 词性标注与词性过滤
6.1 词性标注的原理与作用
词性标注是指给文本中的每个词汇标注其词性(即语法类别),比如名词、动词、形容词等。词性标注对于许多NLP任务都是重要的前处理步骤。例如,在信息抽取中,可能只关心名词和动词;在文本分析中,可能希望只保留实词(如名词、动词、形容词)而过滤虚词(如介词、连词)。
Jieba的词性标注基于一套标注规范,主要包括以下常见的词性标签:n表示名词,v表示动词,a表示形容词,d表示副词,m表示数词,q表示量词,p表示介词,c表示连词,u表示助词,xc表示其他虚词,等等。
6.2 使用词性标注函数
Jieba提供了jieba.posseg模块来实现词性标注。使用方法是导入posseg模块,然后调用cut()函数:
import jieba.posseg as pseg
text = "我爱自然语言处理这个领域,每天都在努力学习相关技术。"
# 进行词性标注
words_with_pos = pseg.cut(text)
print("词性标注结果:")
for word, pos in words_with_pos:
print(f"{word}/{pos}", end=" ")
输出为:
我/r 爱/v 自然语言处理/n 这个/r 领域/n ,/w 每天/m 都/d 在/p 努力/a 学习/v 相关/a 技术/n 。/w
在这个结果中,每个词后面跟着其词性标签。例如,"爱"被标注为动词(v),"自然语言处理"被标注为名词(n),"努力"被标注为形容词(a)。
还可以直接获得词和词性的对应关系,便于后续处理:
import jieba.posseg as pseg
text = "机器学习是人工智能的重要分支。"
# 转换为列表,便于操作
words_pos_list = list(pseg.cut(text))
# 提取所有名词
nouns = [word for word, pos in words_pos_list if pos == "n"]
print("提取的名词:", nouns)
# 提取所有动词
verbs = [word for word, pos in words_pos_list if pos == "v"]
print("提取的动词:", verbs)
6.3 基于词性的过滤与提取
在实际应用中,用户经常需要基于词性进行过滤,比如只保留实词,或者只提取名词进行主题分析。下面的例子展示了如何基于词性进行过滤:
import jieba.posseg as pseg
text = "自然语言处理是计算机科学的一个重要领域,它研究如何让计算机理解人类语言。"
# 词性标注
words_pos = list(pseg.cut(text))
# 定义实词的词性集合(保留主要的实词)
meaningful_pos = {'n', 'v', 'a', 'd', 'm', 'q'}
# 提取实词
meaningful_words = [word for word, pos in words_pos if pos in meaningful_pos]
print("原始分词结果:")
print([word for word, pos in words_pos])
print("\n提取的实词:")
print(meaningful_words)
# 统计词频
from collections import Counter
word_freq = Counter(meaningful_words)
print("\n词频排序:")
for word, freq in word_freq.most_common(5):
print(f"{word}: {freq}")

这种方法在文本预处理中非常常见,特别是在构建机器学习特征时,去掉虚词可以提高特征的质量和模型的性能。
6.4 词性标注的局限与改进
需要注意的是,Jieba的词性标注功能基于统计模型,准确率虽然可以满足大多数应用,但在某些复杂的语境中可能出现错误。例如,同一个词在不同的上下文中可能有不同的词性,但Jieba可能无法准确识别。
对于对准确率有很高要求的应用,可以考虑使用更高级的NLP工具,比如StanfordCoreNLP或哈工大的LTP。这些工具通常使用了更复杂的模型和算法,准确率更高,但同时也需要更多的计算资源。
在Jieba框架内,用户可以通过自定义词典和权重调整,来改进词性标注的效果。当遇到某个词经常被标注错误时,可以通过指定词的词性来纠正。
7 关键词提取的实现与应用
7.1 关键词提取的意义
关键词提取是指从文本中自动识别和提取最具代表性、最重要的词汇。关键词提取在多个领域都有重要应用:在搜索引擎中,关键词可以用于网页索引;在推荐系统中,关键词可以用于内容标签和推荐匹配;在文本总结中,关键词可以帮助理解文本的核心内容;在舆情监测中,关键词可以用于事件识别和追踪。
Jieba提供了两种关键词提取的算法:TF-IDF(词频-逆文档频率)和TextRank。这两种算法各有特点,适用于不同的场景。
7.2 TF-IDF方法的实现
TF-IDF是信息检索和文本挖掘中最常用的词语统计方法。TF是词频(Term Frequency),表示一个词在文档中出现的频率;IDF是逆文档频率(Inverse Document Frequency),表示一个词在整个文档集中的重要程度。TF-IDF的核心思想是:一个词对于某个文档越重要,它的TF-IDF值就越高。
Jieba的关键词提取模块位于jieba.analyse中,使用TF-IDF方法的函数是extract_tags():
from jieba import analyse
text = """
自然语言处理是人工智能的重要分支。近年来,随着深度学习技术的发展,
自然语言处理取得了巨大的进步。神经网络模型,特别是Transformer模型,
在机器翻译、文本分类、问答系统等任务上都表现出了卓越的性能。
自然语言处理的应用包括搜索引擎、推荐系统、聊天机器人等,深刻改变了人们的生活。
"""
# 提取关键词,返回前10个
keywords = analyse.extract_tags(text, topK=10, withWeight=True)
print("提取的关键词:")
for keyword, weight in keywords:
print(f"{keyword}: {weight:.4f}")
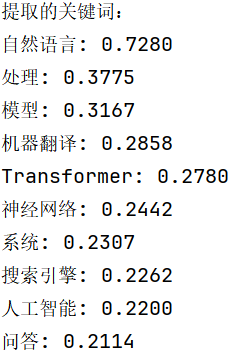
参数说明:topK指定返回关键词的数量,withWeight=True表示返回每个关键词的权重值。如果withWeight=False(默认),则只返回关键词。
7.3 TextRank算法的应用
TextRank是另一种流行的关键词提取算法,它基于图排序算法(PageRank),将文本看作一个词汇网络,计算各个词在网络中的重要性。相比TF-IDF需要语料库信息,TextRank可以直接对单个文档进行处理,不需要外部信息。
在Jieba中,使用TextRank算法的函数也是位于analyse模块中,名为textrank():
from jieba import analyse
text = """
自然语言处理是人工智能的重要分支。近年来,随着深度学习技术的发展,
自然语言处理取得了巨大的进步。神经网络模型,特别是Transformer模型,
在机器翻译、文本分类、问答系统等任务上都表现出了卓越的性能。
自然语言处理的应用包括搜索引擎、推荐系统、聊天机器人等。
"""
# 使用TextRank提取关键词
keywords = analyse.textrank(text, topK=10, withWeight=True)
print("TextRank提取的关键词:")
for keyword, weight in keywords:
print(f"{keyword}: {weight:.4f}")
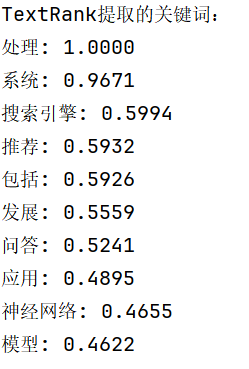
TextRank的优点是对单文档处理效果好,不依赖于外部语料库,但在某些情况下,TF-IDF可能能更好地识别领域相关的专业术语。
7.4 两种算法的对比与选择
TF-IDF和TextRank各有优缺点。TF-IDF依赖于文档集合中的词频统计,因此需要大量的语料库作为背景参考。优点是对常见词汇和领域术语的识别能力强,缺点是对于新的、罕见的词汇识别能力较弱。TextRank不需要额外的语料库,直接基于单个文档的词汇网络进行计算,因此计算开销小,对于孤立的单个文档处理较好。缺点是对于一些常见但重要的词可能权重不足。
在实际应用中,可以考虑结合两种方法,取交集来获得更加稳健的关键词提取结果。下面是一个结合两种方法的例子:
from jieba import analyse
text = """
自然语言处理是人工智能的重要分支。深度学习推动了自然语言处理的发展。
Transformer模型在多个NLP任务上表现出色。
"""
# 加上 withWeight=True
tfidf_keywords = set([w for w, _ in analyse.extract_tags(text, topK=5, withWeight=True)])
# 加上 withWeight=True
textrank_keywords = set([w for w, _ in analyse.textrank(text, topK=5, withWeight=True)])
# 取交集
common_keywords = tfidf_keywords & textrank_keywords
print("TF-IDF关键词:", tfidf_keywords)
print("TextRank关键词:", textrank_keywords)
print("共同关键词:", common_keywords)
7.5 关键词提取的参数调整
Jieba的关键词提取函数提供了几个可以调整的参数。除了前面提到的topK和withWeight外,还有withFlag参数,用于指定是否同时返回词性标签:
from jieba import analyse
text = "自然语言处理包括分词、词性标注、命名实体识别等多个子任务。"
# 使用 textrank,它返回的是 (pair对象, weight)
keywords_with_pos = analyse.textrank(
text,
topK=5,
withWeight=True,
withFlag=True
)
print("使用 TextRank 获取:")
for pair, weight in keywords_with_pos:
# 此时 pair 是一个对象,拥有 .word 和 .flag
print(f"{pair.word}({pair.flag}): {weight:.4f}")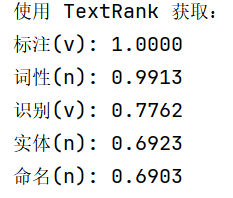
通过灵活调整这些参数,可以根据不同的应用需求获得最合适的关键词提取结果。
8 并行分词与性能优化
8.1 并行分词的必要性
在处理大规模文本数据时,分词操作可能成为性能瓶颈。如果数据量达到百万级、千万级,使用单线程的分词方式会耗时很长。现代计算机通常都有多个处理器核心,充分利用多核处理器可以显著提升处理速度。Jieba提供了并行分词的功能,允许用户使用多个进程或线程来并行处理文本。
8.2 启用并行分词
使用Jieba的并行分词功能非常简单,只需要调用jieba.enable_parallel()函数来启用,然后指定使用的进程数:
import jieba
import time
from concurrent.futures import ProcessPoolExecutor
# 定义单进程分词的函数
def cut_text(text_chunk):
# 注意:在多进程中,每个进程都会有自己的 jieba 实例
return list(jieba.cut(text_chunk))
if __name__ == "__main__": # Windows 下多进程必须放在此判断下
# 1. 构造大文本
text = "这是一个示例句子。" * 100000
# --- 单线程测试 ---
start_time = time.time()
result_single = list(jieba.cut(text))
single_time = time.time() - start_time
print(f"单线程分词耗时: {single_time:.2f}秒")
# --- 手动多进程测试 (Windows 兼容) ---
# 将文本切分成 4 份
num_workers = 4
chunk_size = len(text) // num_workers
chunks = [text[i:i + chunk_size] for i in range(0, len(text), chunk_size)]
start_time = time.time()
result_multi = []
# 使用进程池
with ProcessPoolExecutor(max_workers=num_workers) as executor:
# 并行执行
futures = executor.map(cut_text, chunks)
for res in futures:
result_multi.extend(res)
multi_time = time.time() - start_time
print(f"{num_workers}进程并行分词耗时: {multi_time:.2f}秒")
print(f"加速比: {single_time / multi_time:.2f}x")enable_parallel()函数的参数是进程数,通常应该设置为计算机CPU核心数或接近这个数字。设置过高可能导致上下文切换开销过大,反而降低性能;设置过低则无法充分利用硬件资源。
8.3 并行分词的限制与注意事项
虽然并行分词可以提升性能,但有一些限制和注意事项需要了解。首先,并行分词使用的是多进程而不是多线程,进程创建和销毁都有一定开销。因此,对于较小的文本(比如只有几KB),启用并行分词可能反而降低性能。
其次,由于Python的全局解释器锁(GIL)限制,纯Python代码的多线程并不能真正并行执行。Jieba的并行分词避开了这个问题,使用多进程。但多进程也意味着更高的内存消耗,因为每个进程都有独立的内存空间。
第三,并行分词后的结果顺序可能与输入顺序不同。如果需要保持顺序,需要自己维护一个映射。
import jieba
import time
from multiprocessing import Pool
# 1. 必须定义一个全局函数,供子进程调用
def worker_cut(text):
# 每个进程内部会独立运行 jieba
return list(jieba.cut(text))
if __name__ == "__main__": # Windows 多进程必须加这一行
# 构造数据
texts = [
"自然语言处理很有趣",
"机器学习很有挑战",
"深度学习很复杂"
] * 5000 # 增加数据量以体现并行优势
# --- 模拟并行(4进程) ---
print("正在启动并行分词...")
start = time.time()
# 创建进程池
with Pool(processes=4) as pool:
# 使用 pool.map 将任务分发给 4 个进程
results_parallel = pool.map(worker_cut, texts)
parallel_time = time.time() - start
print(f"并行(4进程)耗时: {parallel_time:.2f}s")
# --- 单线程 ---
print("正在启动单线程分词...")
start = time.time()
results_single = [list(jieba.cut(text)) for text in texts]
single_time = time.time() - start
print(f"单线程耗时: {single_time:.2f}s")
# 计算加速比
print(f"加速比: {single_time/parallel_time:.2f}x")8.4 其他性能优化方法
除了并行分词,还有其他方法可以优化Jieba的性能。首先,预编译正则表达式可以提升性能。如果应用中多次使用相同的正则表达式,应该使用re.compile()预编译,而不是每次都重新编译。
其次,合理使用缓存可以避免重复计算。如果相同的文本需要多次分词,可以将分词结果缓存起来。
import jieba
from functools import lru_cache
# 使用lru_cache缓存分词结果
@lru_cache(maxsize=1000)
def cached_cut(text):
return tuple(jieba.cut(text))
# 第一次调用会执行分词
words1 = cached_cut("自然语言处理很重要")
# 第二次调用相同的文本会直接返回缓存结果
words2 = cached_cut("自然语言处理很重要")
print("分词结果:", list(words1))
此外,对输入文本进行批处理而不是逐个处理,可以减少函数调用开销。在某些场景中,预处理文本(如清理空白、规范化编码)也能提升后续分词的效率。
9 Jieba在实际项目中的应用
9.1 构建文本分类系统
文本分类是一个常见的NLP应用,目标是自动地将文本分配到预定义的分类中。分词是文本分类系统的第一步。下面是一个简化的文本分类示例:
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report, accuracy_score
import pandas as pd
# 1. 准备训练数据 (100条:每类25条)
train_data = [
# --- 科技产品 (25条) ---
("新款iPhone支持卫星通信功能", "科技"), ("人工智能大模型正在改变编程方式", "科技"),
("这款显卡的流处理器数量翻倍了", "科技"), ("自动驾驶系统依靠毫米波雷达感应", "科技"),
("华为发布了全新的鸿蒙操作系统", "科技"), ("量子计算机在特定任务上超越了传统电脑", "科技"),
("由于芯片短缺,全球汽车产量下降", "科技"), ("5G基站的覆盖范围正在稳步扩大", "科技"),
("虚拟现实头显带来了极致的沉浸感", "科技"), ("固态硬盘NVMe协议读写速度极快", "科技"),
("云计算服务为初创企业节省了硬件成本", "科技"), ("这款智能手表支持全天候血氧监测", "科技"),
("液冷散热系统有效降低了服务器温度", "科技"), ("低轨卫星互联网实现了全球覆盖", "科技"),
("折叠屏手机的铰链设计非常精密", "科技"), ("机器人手臂在工业流水线上精确操作", "科技"),
("区块链技术确保了数据交易的透明性", "科技"), ("新款平板电脑配备了高刷新率屏幕", "科技"),
("深度学习算法在图像识别领域取得突破", "科技"), ("边缘计算降低了物联网设备的延迟", "科技"),
("固件更新修复了路由器的安全漏洞", "科技"), ("由于制程工艺进步,处理器能效比提升", "科技"),
("无人机在农业植保中发挥了重要作用", "科技"), ("智能家居系统实现了语音控制家电", "科技"),
("内存频率的提升显著增加了游戏帧数", "科技"),
# --- 文学作品 (25条) ---
("这本长篇小说刻画了复杂的封建家族恩怨", "文学"), ("诗歌的意象传达了诗人对自由的向往", "文学"),
("鲁迅的散文具有强烈的社会批判性", "文学"), ("魔幻现实主义是拉美文学的重要特征", "文学"),
("这部剧本的台词设计充满了戏剧张力", "文学"), ("文学评论家分析了作品中的潜台词", "文学"),
("海明威的简洁文风影响了一代作家", "文学"), ("这部传记还原了历史人物的真实心路", "文学"),
("科幻小说探讨了人类文明的终极命运", "文学"), ("武侠小说中的江湖侠义令人神往", "文学"),
("这本随笔集记录了作者旅途中的感悟", "文学"), ("古典文学研究需要深厚的文字功底", "文学"),
("这篇短篇小说采用了倒叙的结构手法", "文学"), ("诺贝尔文学奖获得者的作品被广泛翻译", "文学"),
("寓言故事通过拟人手法讽刺了贪婪人性", "文学"), ("这部史诗级作品展现了宏大的战争场面", "文学"),
("意识流文学尝试捕捉人类破碎的思维", "文学"), ("这本诗集收录了作者早期的抒情作品", "文学"),
("文学作品是反映社会现实的一面镜子", "文学"), ("童话故事为孩子们构建了奇幻的世界", "文学"),
("这位作家的文字清新脱俗,意境深远", "文学"), ("古典名著的改编需要尊重原著精神", "文学"),
("现代主义文学打破了传统的叙事框架", "文学"), ("这部推理小说逻辑严密,反转不断", "文学"),
("散文的形散而神不散是其艺术魅力所在", "文学"),
# --- 体育赛事 (25条) ---
("梅西在昨晚的比赛中完成帽子戏法", "体育"), ("NBA季后赛的竞争进入了白热化", "体育"),
("奥运会百米飞人大战扣人心弦", "体育"), ("网球公开赛的种子选手意外出局", "体育"),
("游泳运动员刷新了世界纪录", "体育"), ("中国女排展现了不屈不挠的拼搏精神", "体育"),
("马拉松爱好者在城市街道上尽情奔跑", "体育"), ("羽毛球混双组合夺得了金牌", "体育"),
("乒乓球赛场上的弧圈球技术非常精湛", "体育"), ("环法自行车赛考验选手的体能极限", "体育"),
("足球场上主裁判出示了一张红牌", "体育"), ("篮球比赛最后时刻出现了三分准绝杀", "体育"),
("冬季奥运会的滑雪项目极具观赏性", "体育"), ("举重选手成功举起了两倍体重的杠铃", "体育"),
("F1赛车在弯道处的超车动作非常惊险", "体育"), ("排球比赛中拦网是重要的防守手段", "体育"),
("体育频道直播了全运会的开幕式", "体育"), ("健身房里教练正在指导学员深蹲", "体育"),
("斯诺克比赛中选手打出了单杆147分", "体育"), ("射击比赛需要极高的心理素质", "体育"),
("跳水运动员在空中完成了高难度翻转", "体育"), ("田径锦标赛的接力项目讲究配合", "体育"),
("电子竞技正式成为了亚运会比赛项目", "体育"), ("橄榄球比赛充满了强烈的身体对抗", "体育"),
("跆拳道选手在最后时刻踢中对方头部得分", "体育"),
# --- 美食文化 (25条) ---
("火锅的底料熬制需要几十种香料", "美食"), ("这道红烧肉做到了肥而不腻", "美食"),
("粤菜讲究食材的原汁原味和新鲜度", "美食"), ("烘焙甜点时奶油的打发非常关键", "美食"),
("地道的北京烤鸭需要挂炉木炭烘烤", "美食"), ("川菜的麻辣诱惑让人欲罢不能", "美食"),
("米其林餐厅的摆盘如同艺术品", "美食"), ("寿司师傅对醋饭的温度掌控极严", "美食"),
("意大利面的口感要有弹性,不能太软", "美食"), ("民间小吃往往隐藏在深巷之中", "美食"),
("这道汤品经过了八小时的慢火细炖", "美食"), ("素食餐厅推出的仿荤菜维妙维肖", "美食"),
("抹茶粉的品质决定了甜点的色泽", "美食"), ("东南亚菜系中鱼露是灵魂调料", "美食"),
("传统手打牛肉丸非常具有弹性", "美食"), ("煎牛排前需要将肉质表面吸干", "美食"),
("家常菜里蕴含着浓浓的乡愁味道", "美食"), ("面条的筋道程度取决于揉面的力度", "美食"),
("这壶大红袍茶汤金黄,回味悠长", "美食"), ("海鲜大餐需要配上特制的姜醋汁", "美食"),
("鲁菜的拔丝山药考验厨师的火候", "美食"), ("下午茶的司康饼配上草莓酱很美味", "美食"),
("酿酒工艺中的发酵环境需要恒温", "美食"), ("路边摊的烧烤充满了烟火气息", "美食"),
("这道创意料理融合了中西餐的特点", "美食"),
]
# 2. 准备测试数据 (20条:每类5条)
test_data = [
("英伟达发布了性能最强的AI算力芯片", "科技"), ("SpaceX成功发射了重型猎鹰火箭", "科技"),
("这款手机的影像系统由徕卡调教", "科技"), ("程序员正在修复生产环境的逻辑Bug", "科技"),
("5G通信技术正在向6G阶段演进", "科技"),
("海子这首诗表达了对美好生活的向往", "文学"), ("《白鹿原》展现了关中平原的历史变迁", "文学"),
("这位作家的长篇新作在书展上首发", "文学"), ("莎士比亚悲剧中的命运主题非常深刻", "文学"),
("文学期刊发表了关于后现代主义的论文", "文学"),
("世界杯决赛将在梅西和姆巴佩之间展开", "体育"), ("勒布朗詹姆斯刷新了联盟历史得分榜", "体育"),
("游泳世锦赛上中国队收获了多枚金牌", "体育"), ("网球名将宣布因伤退出法网公开赛", "体育"),
("马拉松终点线前志愿者正在递水", "体育"),
("四川麻辣火锅的香味飘满了整条街", "美食"), ("法式甜点马卡龙的制作工艺很复杂", "美食"),
("这道清蒸鱼保持了鱼肉最鲜嫩的状态", "美食"), ("厨师正在展示蒙眼切豆腐的绝活", "美食"),
("手工包制的饺子皮薄馅大,非常好吃", "美食")
]
# 3. 数据处理函数
def preprocess_text(text):
# 分词并用空格连接(sklearn的要求)
words = jieba.lcut(text)
# 简单过滤掉长度为1的词(如:的、了、在)
return " ".join([w for w in words if len(w) > 1])
# 4. 转换数据格式
train_df = pd.DataFrame(train_data, columns=['text', 'label'])
test_df = pd.DataFrame(test_data, columns=['text', 'label'])
train_df['cut_text'] = train_df['text'].apply(preprocess_text)
test_df['cut_text'] = test_df['text'].apply(preprocess_text)
# 5. 特征提取 (TF-IDF)
tfidf = TfidfVectorizer()
X_train = tfidf.fit_transform(train_df['cut_text'])
X_test = tfidf.transform(test_df['cut_text'])
y_train = train_df['label']
y_test = test_df['label']
# 6. 训练机器学习模型 (朴素贝叶斯)
model = MultinomialNB()
model.fit(X_train, y_train)
# 7. 预测与评估
y_pred = model.predict(X_test)
print("=== 机器学习分类器性能指标 ===")
print(f"总准确率 (Accuracy): {accuracy_score(y_test, y_pred):.2f}")
print("\n详细分类报告:")
print(classification_report(y_test, y_pred))
# 8. 展示具体测试结果
print("\n=== 具体测试样本预测结果 ===")
results = pd.DataFrame({
'原始文本': test_df['text'],
'真实标签': y_test,
'预测标签': y_pred
})
print(results)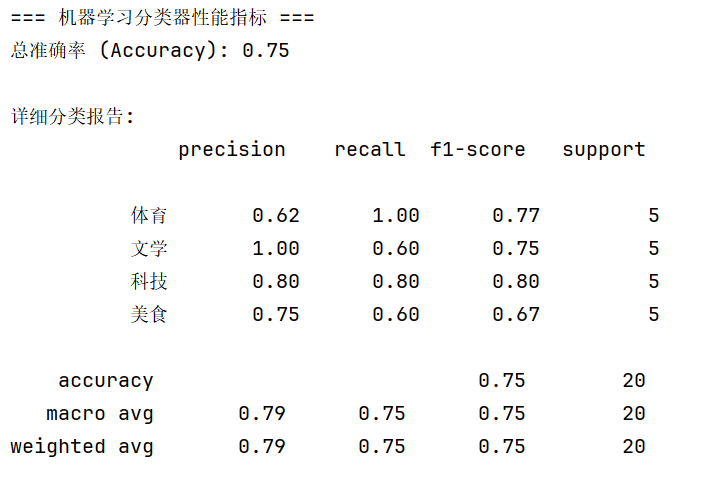
9.2 实现搜索引擎查询理解
搜索引擎需要理解用户的查询意图,分词是重要的一步。下面展示如何使用Jieba构建一个简单的搜索系统:
import jieba
class SimpleSearchEngine:
def __init__(self):
self.documents = {} # 文档ID -> 文档内容
self.inverted_index = {} # 词 -> 包含该词的文档ID列表
def add_document(self, doc_id, content):
"""添加文档到搜索引擎"""
self.documents[doc_id] = content
# 使用搜索引擎模式分词并建立倒排索引
words = jieba.lcut_for_search(content)
for word in words:
if word not in self.inverted_index:
self.inverted_index[word] = []
self.inverted_index[word].append(doc_id)
def search(self, query, top_k=5):
"""搜索查询词相关的文档"""
query_words = jieba.lcut_for_search(query)
# 计算每个文档与查询的相关度
doc_scores = {}
for word in query_words:
if word in self.inverted_index:
for doc_id in self.inverted_index[word]:
doc_scores[doc_id] = doc_scores.get(doc_id, 0) + 1
# 按相关度排序并返回top_k
results = sorted(
doc_scores.items(),
key=lambda x: x[1],
reverse=True
)[:top_k]
return [(doc_id, self.documents[doc_id]) for doc_id, _ in results]
# 使用示例
search_engine = SimpleSearchEngine()
# 添加文档
documents = [
(1, "自然语言处理是人工智能的重要分支"),
(2, "机器学习包括监督学习和无监督学习"),
(3, "深度学习是机器学习的一个子领域"),
(4, "计算机视觉处理图像和视频数据"),
]
for doc_id, content in documents:
search_engine.add_document(doc_id, content)
# 执行搜索
query = "自然语言处理和机器学习"
results = search_engine.search(query)
print(f"查询: {query}")
print(f"搜索结果:")
for doc_id, content in results:
print(f" 文档{doc_id}: {content}")

9.3 情感分析预处理
情感分析需要对文本进行分词和去停用词。下面展示如何使用Jieba进行情感分析的预处理:
import jieba
import jieba.posseg as pseg
class SentimentAnalysisPreprocessor:
def __init__(self, stopwords_file=None):
# 加载停用词
self.stopwords = set()
if stopwords_file:
with open(stopwords_file, 'r', encoding='utf-8') as f:
self.stopwords = set(word.strip() for word in f)
def preprocess(self, text):
"""
对文本进行预处理:分词、去停用词、词性过滤。
"""
# 词性标注
words_pos = pseg.cut(text)
# 保留的词性(主要是实词)
keep_pos = {'n', 'v', 'a', 'ad', 'd', 'p'}
# 分词、过滤停用词和虚词
processed_words = []
for word, pos in words_pos:
if (word not in self.stopwords and
pos in keep_pos and
len(word) > 1): # 过滤单个字符
processed_words.append(word)
return processed_words
# 使用示例
preprocessor = SentimentAnalysisPreprocessor()
texts = [
"这个产品质量非常好,我很满意。",
"服务态度很差,强烈不推荐。",
"价格有点高,但整体还不错。"
]
for text in texts:
processed = preprocessor.preprocess(text)
print(f"原文: {text}")
print(f"处理后: {processed}\n")
9.4 热词提取和趋势分析
互联网企业经常需要提取和分析热词,以了解用户关注的话题。下面展示如何使用Jieba进行热词提取:
import jieba
from collections import Counter
from datetime import datetime, timedelta
import random
class HotwordExtractor:
def __init__(self):
self.word_timeline = {} # 词 -> {日期: 频率}
def add_texts(self, texts, date=None):
"""
添加文本,提取热词。
texts: 文本列表
date: 日期(可选),用于追踪词汇趋势
"""
if date is None:
date = datetime.now().strftime("%Y-%m-%d")
# 分词并统计
all_words = []
for text in texts:
words = jieba.lcut(text)
all_words.extend(words)
# 统计词频
word_freq = Counter(all_words)
# 记录到时间线
for word, freq in word_freq.items():
if word not in self.word_timeline:
self.word_timeline[word] = {}
self.word_timeline[word][date] = freq
def get_hot_words(self, topk=10, min_length=2):
"""获取热词"""
# 计算每个词的总频率
total_freq = {}
for word, timeline in self.word_timeline.items():
if len(word) >= min_length: # 过滤长度过短的词
total_freq[word] = sum(timeline.values())
# 返回频率最高的词
return sorted(
total_freq.items(),
key=lambda x: x[1],
reverse=True
)[:topk]
def get_trend(self, word):
"""获取某个词的趋势"""
if word in self.word_timeline:
return sorted(self.word_timeline[word].items())
return None
# 使用示例
extractor = HotwordExtractor()
# 模拟多日的文本数据
sample_texts = [
"人工智能和大模型成为今年最热话题",
"ChatGPT的出现改变了人工智能的发展方向",
"大模型的应用前景非常广阔",
]
# 添加文本(模拟多天的数据)
for i in range(5):
date = (datetime.now() - timedelta(days=i)).strftime("%Y-%m-%d")
extractor.add_texts(sample_texts, date=date)
# 获取热词
hot_words = extractor.get_hot_words(topk=5)
print("热词排行:")
for word, freq in hot_words:
print(f" {word}: {freq}")
# 查看某个词的趋势
trend = extractor.get_trend("人工智能")
print(f"\n'人工智能'的趋势: {trend}")

10 常见问题与故障排查
10.1 分词结果不符合预期
当分词结果不符合预期时,首先应该检查是否遗漏了添加自定义词汇。很多分词错误是因为词不在预置词典中。此时应该使用add_word()或load_userdict()添加词汇。
其次,应该检查HMM参数。如果文本中包含很多新词和未知词,关闭HMM(HMM=False)可能反而降低准确率。
第三,可以尝试不同的分词模式。有时候搜索引擎模式或全模式可能更符合期望。
import jieba
problem_text = "苹果手机最新发布了iPhone15"
print("默认分词:", jieba.lcut(problem_text))
# 尝试添加词汇
jieba.add_word("iPhone15", freq=1000)
print("添加词汇后:", jieba.lcut(problem_text))
# 尝试不同的模式
print("搜索引擎模式:", jieba.lcut_for_search(problem_text))
10.2 性能问题
如果分词速度太慢,首先应该考虑启用并行分词。如果已经启用但仍然很慢,检查是否在循环中反复初始化Jieba或加载词典。
其次,考虑文本的大小和复杂度。对于非常大的文本(几MB以上),可能需要进行文本分割,逐段处理。
import jieba
# 不好的做法:在循环中重复加载词典
texts = [...]
for text in texts:
jieba.load_userdict("words.txt") # 低效!
result = jieba.cut(text)
# 好的做法:只加载一次
jieba.load_userdict("words.txt")
results = [jieba.cut(text) for text in texts]
10.3 内存占用过高
Jieba会在内存中保持词典和相关数据结构,对于非常大的自定义词典,这可能占用大量内存。如果内存是瓶颈,可以考虑只加载必要的词汇,或者对文本进行分批处理。
启用并行分词会增加内存占用(因为每个进程都有独立的内存),对于内存受限的环境,应该限制进程数。
10.4 编码问题
在某些情况下,可能遇到编码相关的错误,特别是在处理包含特殊字符或多国语言的文本时。确保文本和文件都使用UTF-8编码,并在读取文件时显式指定编码:
import jieba
# 从文件读取时指定编码
with open("text.txt", 'r', encoding='utf-8') as f:
text = f.read()
result = jieba.lcut(text)
11 高级技巧与最佳实践
11.1 多语言处理
虽然Jieba主要针对中文设计,但它也能处理包含英文、数字等内容的混合文本。对于多语言文本,一个常见的做法是使用正则表达式进行预处理,将不同语言的部分分离处理:
import jieba
import re
text = "The famous scientist Albert Einstein said 爱因斯坦是著名的科学家。"
# 分离中文和英文
def process_mixed_text(text):
# 先分割中文和英文
parts = re.split(r'([a-zA-Z\s]+)', text)
result = []
for part in parts:
if re.match(r'^[a-zA-Z\s]+$', part):
# 英文部分直接按空格分割
result.extend(part.split())
else:
# 中文部分使用Jieba分词
result.extend(jieba.lcut(part))
return [w for w in result if w.strip()]
print(process_mixed_text(text))
11.2 构建领域专用分词器
对于垂直领域的应用(如医疗、金融、法律等),预置词典可能不够完备。可以构建一个领域专用的分词器:
import jieba
class DomainSpecificSegmenter:
def __init__(self, domain_name):
self.domain_name = domain_name
# 核心修改:将 jieba.Jieba() 改为 jieba.Tokenizer()
self.custom_segmenter = jieba.Tokenizer()
self._load_domain_dictionary()
def _load_domain_dictionary(self):
"""加载领域词典"""
domain_dicts = {
"medical": "medical_terms.txt",
"finance": "finance_terms.txt",
"legal": "legal_terms.txt"
}
dict_file = domain_dicts.get(self.domain_name)
if dict_file:
try:
self.custom_segmenter.load_userdict(dict_file)
except:
# 如果没有外部文件,为了演示效果,我们可以手动添加词汇
if self.domain_name == "medical":
self.custom_segmenter.add_word("急性心肌梗死")
pass
def cut(self, text):
"""进行分词"""
return self.custom_segmenter.cut(text)
# 使用示例
medical_seg = DomainSpecificSegmenter("medical")
medical_text = "患者出现了急性心肌梗死的症状。"
result = medical_seg.cut(medical_text)
print("分词结果:", list(result))11.3 分词结果的后处理
在某些情况下,需要对Jieba的分词结果进行后处理,比如合并某些词、删除某些词、规范化等:
import jieba
from collections import defaultdict
class SegmentationPostprocessor:
def __init__(self):
self.merge_rules = [] # (pattern_list, merged_word)
self.remove_rules = [] # 应该删除的词
def add_merge_rule(self, pattern_list, merged_word):
"""添加合并规则"""
self.merge_rules.append((pattern_list, merged_word))
def add_remove_rule(self, word):
"""添加删除规则"""
self.remove_rules.append(word)
def process(self, words):
"""处理分词结果"""
result = []
i = 0
while i < len(words):
# 尝试应用合并规则
merged = False
for pattern, merged_word in self.merge_rules:
if (i + len(pattern) <= len(words) and
words[i:i+len(pattern)] == pattern):
result.append(merged_word)
i += len(pattern)
merged = True
break
if not merged:
# 检查删除规则
if words[i] not in self.remove_rules:
result.append(words[i])
i += 1
return result
# 使用示例
postprocessor = SegmentationPostprocessor()
postprocessor.add_merge_rule(['北', '京'], '北京')
postprocessor.add_remove_rule('的')
text = "北京是中国的首都。"
words = jieba.lcut(text)
processed = postprocessor.process(words)
print("原始分词:", words)
print("后处理结果:", processed)
11.4 Jieba与其他库的集成
Jieba可以与其他Python库集成使用,以构建更强大的NLP应用。例如,与scikit-learn集成进行文本分类:
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
class ChineseTextClassifier:
def __init__(self):
# 自定义的Jieba分词器
def jieba_tokenizer(text):
return jieba.lcut(text)
# 使用Pipeline将分词和分类组合
self.pipeline = Pipeline([
('tfidf', TfidfVectorizer(
analyzer='word',
tokenizer=jieba_tokenizer
)),
('clf', MultinomialNB())
])
def fit(self, texts, labels):
"""训练分类器"""
self.pipeline.fit(texts, labels)
def predict(self, texts):
"""进行预测"""
return self.pipeline.predict(texts)
# 使用示例
classifier = ChineseTextClassifier()
train_texts = [
"这个电影很好看,我很喜欢",
"太烂了,浪费时间",
"价格太贵了,不值得购买",
"质量非常好,强烈推荐"
]
train_labels = [1, 0, 0, 1] # 1表示正面,0表示负面
classifier.fit(train_texts, train_labels)
test_texts = ["很棒的作品"]
prediction = classifier.predict(test_texts)
print(f"预测结果: {prediction}")
12 总结与展望
12.1 Jieba库的优势总结
通过本文的详细讲解,我们看到了Jieba库在中文分词领域的多重优势。首先,Jieba提供了开箱即用的高质量分词效果,内置的35万词条词典能够覆盖日常文本的大多数词汇。其次,库提供了多种分词模式和丰富的高级功能,包括词性标注、关键词提取、并行分词等,满足不同应用的需求。第三,Jieba的API设计简洁直观,易学易用,降低了使用门槛。第四,Jieba是开源的,有活跃的社区支持,文档相对完善。最后,对于大多数应用而言,Jieba的性能足以满足要求,并且可以通过并行分词进一步优化。
12.2 可能的限制与改进方向
尽管Jieba功能强大,但也存在一些限制。对于新词、罕见词和专业术语,Jieba的分词准确率可能不尽理想。虽然通过添加自定义词典可以改善,但仍然需要大量的人工维护工作。其次,对于异常复杂的句式或歧义较多的文本,基于词频和HMM的算法可能无法达到最优效果。另外,Jieba对于词义消歧的支持较弱,无法区分多义词在不同语境中的具体含义。
未来的改进方向包括融合更多的语言学知识,采用更先进的机器学习或深度学习模型,提高对未知词和新词的识别能力,以及更好地支持词义消歧等。
12.3 选择合适的分词工具
在实际项目中,除了Jieba外,还有其他中文分词工具可选,比如Stanford分词器、哈工大的LTP、Spacy等。选择哪个工具应该根据具体的应用需求来考虑。如果需要快速、简单、开箱即用的解决方案,Jieba是最佳选择。如果对准确率有很高的要求,可能需要考虑使用更复杂、更强大的工具。如果需要与其他NLP模块(如依存句法分析、语义角色标注等)的紧密集成,专门针对这些任务设计的工具可能更合适。
12.4 学习与实践建议
对于想要掌握Jieba的学习者,建议从基础开始,先理解精确模式的原理和用法,再逐步学习其他模式和高级功能。在实践中,应该多进行实验和测试,理解不同参数和配置对分词结果的影响。当遇到分词问题时,不要急着放弃Jieba,而是先思考是否可以通过添加词汇、调整参数或后处理等方法来改善结果。最后,在实际项目中应该持续监测和评估分词效果,根据反馈不断改进词典和配置。
Jieba库虽然是一个相对简单的工具,但其蕴含的设计思想和算法思维对学习自然语言处理的人都有重要的参考价值。通过深入理解和充分利用Jieba,不仅能够解决实际问题,还能为后续学习更复杂的NLP技术打下坚实的基础。希望本文的内容能够帮助读者全面掌握Jieba库,并在实际项目中发挥其最大的作用。


















 2405
2405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











