





1 引言
在当今信息爆炸的时代,我们每天都被海量的文本内容所淹没。无论是学术论文、新闻报道、技术文档还是社交媒体内容,我们需要快速地理解和消化大量信息。然而,逐字逐句阅读每一份冗长的文档已经成为一种奢侈。这就是文本自动总结技术应运而生的原因。自动总结不仅可以帮助我们节省宝贵的时间,还能够帮助我们快速抓住信息的核心要点,提高工作效率和学习效果。
文本自动总结是自然语言处理领域中一个重要的研究课题,它涉及多个领域的知识交叉,包括文本处理、信息提取、图论算法和统计分析等多个方面。传统的总结方法主要分为两大类:一类是抽取式总结,它从原文本中直接抽取关键句子来组成摘要;另一类是生成式总结,它利用神经网络模型根据原文本的语义理解来生成新的文本。在实际生产环境中,特别是在中国大陆,由于网络限制和成本考虑,使用本地的传统自然语言处理方法往往更加实用和经济。
本文将详细探讨如何使用Python编程语言结合传统的自然语言处理技术来实现一个功能完整、实用高效的长文章自动总结系统。这个系统不仅要能够处理各种格式的文本文件,还要能够正确处理中文字符,支持中文路径的文件访问,这些都是在实际生产环境中必须解决的问题。相比于依赖云端API的方法,本地自然语言处理方法具有多个优势:首先是完全离线工作,无需网络连接和API密钥;其次是没有隐私泄露的风险,所有数据都保留在本地;再次是没有API调用的成本开销;最后是可以根据具体需求进行定制和优化。我们将从理论基础开始,逐步深入到系统架构设计、具体实现、性能优化和实际应用等多个层面。
2 文本处理与自然语言处理基础
2.1 文本处理的核心概念
文本处理是信息处理中最基本也是最重要的部分。在深入讨论自动总结之前,我们需要理解计算机如何理解和处理人类的自然语言。这个过程远比想象中复杂,因为人类语言充满了歧义、隐喻和上下文依赖等特性,而计算机需要将这些模糊的概念转化为可以处理的数学模型。根据Jurafsky和Martin在其经典著作《Speech and Language Processing》中的论述,自然语言的处理涉及多个层次的分析,从表面上看似简单的字符流,到底层的语义和实用意义的理解,整个过程需要多种算法和知识来支撑。
文本的最基本单位是字符,这些字符串联在一起形成单词,单词又组成句子,句子构成段落和文章。在处理文本时,我们需要考虑编码问题,特别是当涉及到中文这样的非ASCII字符时。中文的处理涉及到特殊的编码方式,通常使用UTF-8编码来确保可以正确地处理各种符号和字符。这不仅包括常见的汉字,还包括标点符号、数字、英文字母等混合内容。在Windows系统上,有些应用程序可能使用GBK或GB2312编码,这要求我们的系统必须能够自动检测和处理各种编码方式。
文本预处理是任何自然语言处理任务的第一步。在原始文本被输入到任何算法或模型之前,必须对其进行清洗和规范化。这个过程包括去除不必要的空白符、处理特殊符号、统一字符大小写等等。特别地,对于中文文本,我们需要进行分词处理,即将连续的中文字符序列分割成有意义的单词。这个过程的复杂性在于,不同的分词方式可能导致完全不同的语义理解。例如,"研究生命起源"这个句子可以被分为"研究/生命/起源"或"研究生/命起源"或其他方式,而每种分法都会改变句子的意思。
2.2 分词与词汇分析
分词是中文自然语言处理中的一个基础但关键的步骤。与英文不同,英文单词之间由空白符自然分隔,而中文是一个连续的字符流,没有明显的词界标记。这意味着我们需要使用特定的算法来识别词界。理解分词的原理对于构建可靠的文本处理系统至关重要。根据Sun和Huang (2016)在《Chinese word segmentation: Another decade review (2007-2017)》中的综述,中文分词的研究已经经历了十多年的发展,从最初的基于字典的方法演进到现在的深度学习方法,每一步的发展都是为了解决前一步方法中存在的问题。
在现代的中文处理中,常用的分词方法包括基于字典的方法、基于统计的方法和基于深度学习的方法。基于字典的方法最简单,它维护一个单词字典,然后尝试在文本中匹配这些单词。最大正向匹配算法是这类方法中的代表,它从左到右扫描文本,每次选择最长的匹配单词。然而,这种方法存在明显的局限性,特别是在处理歧义和新词时。当遇到未在字典中的词汇时,最大匹配算法会将其分解为单个字符,这会导致语义的破坏。
基于统计的方法则考虑了单词出现的频率和单词之间的共现关系。根据Spärck Jones (1972)的开创性工作《A statistical interpretation of term specificity and its application in retrieval》,统计方法能够更好地捕捉单词的重要性和相关性。在中文分词中,这类方法认为高频共现的字符序列更可能构成一个单词。这些方法需要大量的训练数据来学习单词的统计特性,但一旦训练完成,它能够更好地处理歧义和新词问题。条件随机场(CRF)和隐马尔可夫模型(HMM)是这类方法中的代表算法,它们可以考虑词语出现的上下文,从而做出更加准确的分词决策。
在我们的总结系统中,我们将使用业界成熟的分词工具库jieba,这个工具已经预训练好了中文分词模型,结合了多种分词方法的优点。jieba库支持多种分词模式,包括精确模式、全模式和搜索引擎模式。对于文本总结任务,精确模式通常是最合适的选择,因为它能够去除冗余分词,使得分词结果更加准确。jieba库还支持加载自定义字典和调整词频,这使得我们可以针对特定的领域进行优化。
2.3 文本表示方法
文本表示是连接人类语言和机器学习算法之间的桥梁。算法需要某种形式的数值表示来处理文本数据。最简单的表示方法是词袋模型(Bag of Words),它将文本表示为一个向量,向量的每一维对应一个词汇表中的单词,而向量的值则是该单词在文本中出现的频数。这种方法虽然简单直观,但它忽略了单词之间的顺序关系,对文本的语义捕捉能力有限。在处理总结任务时,我们不需要完全理解每个单词的精确语义,只需要理解哪些词是重要的,词袋模型因此就足够了。
TF-IDF(Term Frequency-Inverse Document Frequency)是在词袋模型基础上的一个改进,它不仅考虑单词在文本中出现的频率(Term Frequency),还考虑了单词的重要性(Inverse Document Frequency)。这个方法的奠基性工作由Spärck Jones在1972年发表的论文《A statistical interpretation of term specificity and its application in retrieval》中详细阐述。这个方法的直观思想是,出现在少数文本中的单词通常更有代表性,而出现在大多数文本中的单词则缺乏区分能力。例如,在一个文本集合中,"的"、"是"、"在"这样的虚词会在几乎所有文本中出现,因此它们的IDF值会很低,说明它们对识别文本的重要内容没有帮助。相反,"人工智能"、"深度学习"这样的专业词汇可能只在少数文本中出现,因此具有较高的IDF值。TF-IDF方法在信息检索和文本分类中被广泛应用,它为文本提供了一个简单但有效的数值表示。在我们的总结系统中,我们将使用TF-IDF来计算每个句子的重要性得分。
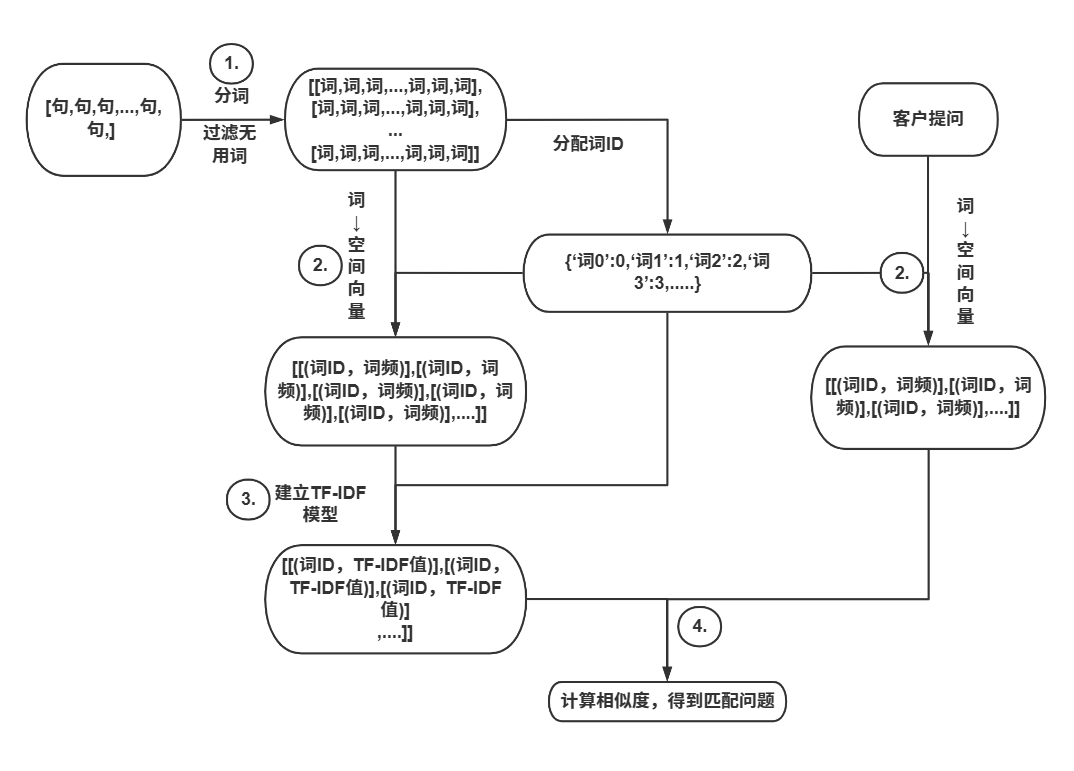
TextRank是一个基于图论的文本表示和处理方法。这个方法的核心思想是将文本中的句子或词语表示为图的节点,如果两个句子有相似的词汇,就在它们之间建立边。然后,使用PageRank算法来计算每个节点的重要性。根据Mihalcea和Tarau (2004)在《TextRank: Bringing order into text》中的论述,这个方法能够同时考虑词的重要性和句子之间的关系,从而能够更加准确地识别关键句子。这个方法的优点在于它不需要任何训练过程,这使得它可以直接应用于任何文本,无论是什么领域或语言。
2.4 句子级别的语义理解
在文本总结任务中,我们不仅需要理解单词的含义,还需要理解句子的整体语义。一个句子是由多个单词按照特定的语法规则组合而成的,这种组合方式能够产生新的、不能简单地由各个单词的含义相加得到的含义。Jurafsky和Martin在《Speech and Language Processing》中详细讨论了这种组合性(Compositionality)的原理和应用。
在传统的自然语言处理方法中,句子级别的理解通常通过多种方式进行。最简单的方法是基于词的重要性,如果一个句子包含了很多重要的词汇,那么这个句子就被认为是重要的。重要性通常用TF-IDF分数来衡量。在计算了每个词的TF-IDF分数后,可以将句子中所有词的TF-IDF分数相加,或者取平均值,作为句子的重要性得分。这种方法虽然简单,但在很多情况下表现出色。
另一种方法是基于词的出现频率。信息论告诉我们,高频词通常是常用词,而低频词往往包含更多的信息。因此,一个包含较多低频但有意义的词的句子通常比一个包含常用词的句子更重要。这种方法的思想是,低频词的出现往往表明这个句子涉及到特定的主题或新的信息。
基于图的方法是计算句子重要性的一种强大技术。Mihalcea和Tarau (2004)提出的TextRank算法在这个领域做出了重要贡献。在这种方法中,文本被表示为一个图,其中节点是句子,边的权重表示两个句子之间的相似度。然后,可以使用PageRank算法来计算每个节点的重要性。PageRank算法由Brin和Page (1998)在他们的论文《The anatomy of a large-scale hypertextual web search engine》中首次提出,用于计算网页的重要性。这个算法的基本思想是,一个节点的重要性由指向它的节点的重要性决定。在应用到文本总结时,相似度高的句子被认为是相互支持和强化的,因此它们的重要性会相互提升。这个方法能够同时考虑句子的内容和句子之间的关系,从而能够更加准确地识别关键句子。
3 传统自然语言处理方法的原理与应用
3.1 抽取式总结的理论基础
抽取式总结(Extractive Summarization)是最传统也是最稳定的文本总结方法。这种方法通过从原文本中选择重要的句子,然后按原有的顺序将这些句子组合在一起,形成摘要。根据Nenkova和McKeown (2012)在《A survey of text summarization techniques》中的综述,抽取式总结的优点是简单直接,生成的摘要总是来自原文本,因此通常是语法正确和事实准确的。它的缺点是生成的摘要可能不够流畅,而且被选中的句子之间可能存在冗余或连接不足。
抽取式总结涉及两个核心问题:首先,如何计算每个句子的重要性得分;其次,如何选择得分最高的句子组成摘要。这两个问题的解决方案直接影响了最终摘要的质量。
计算句子重要性的方法多种多样。一个直观的方法是基于词的重要性,根据Spärck Jones (1972)的理论,出现在少数文本中的词往往更有代表性。如果一个句子包含了很多这样的重要词汇,那么这个句子就被认为是重要的。重要性通常用TF-IDF分数来衡量。在计算了每个词的TF-IDF分数后,可以将句子中所有词的TF-IDF分数相加,或者取平均值,作为句子的重要性得分。这种方法虽然简单,但在很多实际应用中表现相当不错。
另一个常用的计算句子重要性的方法是基于词的出现频率。这种方法的思想是,出现在原文本中多次的词往往代表了文本的主要内容。因此,包含高频词的句子更可能是重要的。例如,在一篇关于气候变化的文章中,"全球变暖"、"温室气体"、"碳排放"这样的词可能会多次出现,包含这些词的句子很可能是对文章内容的准确总结。
TextRank算法提供了一个更加复杂但也更加强大的方法。Mihalcea和Tarau (2004)在《TextRank: Bringing order into texts》中提出了这个算法,并证明了它在文本总结和关键词提取中的有效性。在TextRank中,句子被表示为图的节点,如果两个句子共享足够多的词汇,就在它们之间建立加权边。然后使用基于PageRank的迭代算法来计算每个句子的得分。这个方法的优点是它不需要任何训练过程,可以直接应用于任何文本。而且它能够考虑句子之间的相互关系,一个句子的重要性不仅取决于它本身包含的词汇,还取决于它与其他重要句子的相似度。
3.2 评估指标与质量衡量
评估文本总结的质量是一个重要的课题。一个好的摘要应该具备几个关键的特性:首先,它应该忠实于原文本,保留原文本的主要思想和事实;其次,它应该简洁,能够用尽可能少的文字表达最多的信息;再次,它应该连贯,句子之间的逻辑关系清晰;最后,它应该易读,使用清晰的语言。这些特性往往是相互制约的,需要在实现中进行权衡。
在学术研究中,最常用的自动评估指标是ROUGE(Recall-Oriented Understudy for Gisting Evaluation)。Nenkova和McKeown (2012)在他们的综述中详细讨论了ROUGE指标及其他评估方法。ROUGE族指标包括ROUGE-N、ROUGE-L和ROUGE-S等多种变体。ROUGE-N是基于N-gram的重叠度量,它计算生成的摘要与参考摘要之间的N-gram重叠率。例如,ROUGE-1衡量单词级别的重叠,ROUGE-2衡量二元组的重叠。这种计算方式能够衡量生成摘要对参考摘要的召回率和精确率。ROUGE-L基于最长公共子序列,考虑了单词的顺序,这使得它能够更好地评估摘要的连贯性。这些指标都是基于词汇重叠的,它们衡量的是生成摘要与参考摘要的相似度。
3.3 TextRank算法的深入分析
TextRank是一个基于图的排序算法,用于提取关键词和关键句子。Mihalcea和Tarau在2004年的论文《TextRank: Bringing order into texts》中提出了这个算法,它的核心思想来自于PageRank算法,后者由Brin和Page (1998)在《The anatomy of a large-scale hypertextual web search engine》中提出,用于网页重要性的计算。TextRank的巧妙之处在于它能够将PageRank的思想从链接网络转化到文本结构中。
在TextRank算法中,文本被建模为一个图,其中节点可以是词汇或句子,边表示词汇或句子之间的关系。对于句子级别的总结,每个句子是一个节点。如果两个句子共享足够多的词汇,就在它们之间建立一条带权重的边。权重通常由两个句子的相似度决定,可以使用余弦相似度或其他相似度度量来计算。
建立好图之后,使用PageRank算法来计算每个节点的得分。根据Brin和Page (1998)的原始论文,PageRank算法的基本原理是迭代计算,每个节点的得分由指向它的其他节点的得分加权平均得到。这样,经过多次迭代,重要的节点(即与许多其他重要节点相连的节点)会获得较高的得分。
TextRank算法的一个重要优势是它不需要任何训练过程。这意味着它可以直接应用于任何文本,无需标注数据或预训练模型。这使得它特别适合于处理多种领域和语言的文本。另一个优势是它能够自动识别哪些句子对整体内容最具代表性,而不需要人工干预。
3.4 TF-IDF方法的实现与应用
TF-IDF是信息检索和文本处理中最基础的方法之一。根据Spärck Jones (1972)的经典论文《A statistical interpretation of term specificity and its application in retrieval》,这个方法虽然简单,但能够有效地衡量词汇的重要性。TF代表Term Frequency,即一个词在文档中出现的频率。IDF代表Inverse Document Frequency,即逆文档频率。TF-IDF的核心思想是,一个词对于一个文档的重要性取决于两个因素:这个词在该文档中出现的频率,以及这个词在整个文档集合中出现的稀有程度。
TF通常计算为词在文档中出现的次数,或者为了避免长文档的偏差,可以使用归一化的TF,即词频除以文档的总词数。这样可以使得不同长度的文档具有可比性。
IDF的计算方法通常是使用对数函数来避免数值太大。IDF的公式是log(总文档数 / 包含该词的文档数)。这样,如果一个词出现在很多文档中,它的IDF值就会很小,说明它缺乏区分能力。相反,如果一个词只出现在少数文档中,它的IDF值就会很大,说明它能够很好地识别这些文档的特定内容。
将TF和IDF相乘得到TF-IDF分数,这个分数反映了一个词对一个文档的重要性。在文本总结中,我们可以将整个原文本视为一个"文档集合",每个句子视为一个小的"文档"。计算每个词在每个句子中的TF-IDF分数,然后将一个句子中所有词的TF-IDF分数相加或取平均值,就可以得到这个句子的重要性得分。
TF-IDF方法的优点是简单直观,计算速度快,而且对于许多应用都能给出合理的结果。缺点是它没有考虑词序和句子结构,而且对于所有文本都使用相同的权重策略,可能不够灵活。
4 系统架构设计
4.1 整体框架结构
一个完整的自动总结系统涉及多个组件的协调。从高层次看,系统可以分为几个主要部分:输入处理、文本预处理、总结生成和输出处理。这种分层的架构设计使得系统具有良好的可维护性和可扩展性。
输入处理部分负责读取各种格式的输入文件。在我们的系统中,主要处理TXT文件,但架构应该足够灵活以支持其他格式如DOC、PDF等。这个部分需要正确处理中文路径和中文字符,确保在Windows和Linux等不同操作系统上都能正常工作。在中文系统中,路径可能包含中文字符,而不同的系统使用不同的路径分隔符,例如Windows使用反斜杠而Linux使用正斜杠。
文本预处理部分包括多个步骤。首先是编码检测和规范化,确保无论文件使用什么编码,都能正确读取。这对于处理来自不同来源的文件特别重要,因为不同的编辑器和操作系统可能使用不同的默认编码。其次是文本清洗,去除不必要的空白符、特殊符号等。这一步很重要,因为原始文本中可能包含多余的空格、制表符或其他格式化字符,这些可能会干扰后续的处理。再次是文本分割,将长文本分割成更小的单元,通常是句子或段落。对于非常长的文本,可能需要进一步分割成固定大小的块,以便进行处理。
总结生成部分是系统的核心。它应用选定的总结算法,例如TextRank或TF-IDF,来识别关键句子并生成摘要。这个部分需要处理多个总结单元的结果,如果原文本被分割成多个部分,需要确保最终的摘要是一致的和连贯的。
输出处理部分负责将生成的摘要以合适的格式输出。这可能包括保存到文件、显示到控制台或返回给调用者。输出应该清晰地显示摘要的信息,包括摘要长度、原文长度和压缩率等元数据。
4.2 文本分割策略
当文本过长时,需要对文本进行分割。根据文本处理的最佳实践,有多种分割策略,每种都有其优缺点。选择合适的分割策略对于保证总结质量很重要。
最简单的分割方法是按字符数分割。这种方法速度快,易于实现,但可能会在单词或句子的中间进行分割,破坏语义的完整性。例如,如果在一个字符的位置进行分割,可能会将一个完整的词汇分割成两部分。
更智能的方法是按句子分割。首先使用自然语言处理工具识别文本中的句子边界,然后按句子边界进行分割。这样可以保证每个分割单元都包含完整的语义单位。然而,这种方法的准确性依赖于句子识别的准确性。对于中文文本,句子通常由标点符号如句号、问号、感叹号等标记。
还有一种方法是按段落分割。段落通常由空行或缩进表示,是文本中自然的逻辑单位。按段落分割既保留了语义的完整性,又使得分割单元通常较大。这种方法对于处理结构清晰的文本特别有效,例如新闻文章或学术论文。
在我们的实现中,我们将使用一种混合的方法,首先按段落分割,然后如果某个段落仍然过长,再按句子进行分割。这样可以在保留语义完整性和处理效率之间找到良好的平衡。
4.3 模块设计与依赖关系
一个好的系统设计应该遵循模块化原则,即将系统分解为多个相对独立的模块,每个模块负责特定的功能。这样可以提高代码的可维护性、可测试性和可扩展性。
在我们的系统中,可以设计以下几个主要模块。首先是文件处理模块,负责文件的读取和写入。这个模块应该处理编码检测、路径处理等问题。其次是文本处理模块,包含文本清洗、分词、分割等功能。这个模块应该提供多种文本处理方法供上层调用。再次是总结算法模块,实现具体的总结算法如TextRank和TF-IDF。这些算法应该被设计成可以相互替换的,以便系统能够灵活选择使用哪种算法。最后是总结协调模块,负责协调各个模块完成总结任务。
这些模块之间存在依赖关系。文件处理模块和文本处理模块是相对独立的,都可以独立地进行单元测试。总结算法模块则依赖于文本处理模块提供的分词和分割功能。总结协调模块则依赖于其他所有模块,负责调用它们完成任务。这种分层的依赖关系使得系统的结构清晰,便于理解和维护。
4.4 错误处理与日志机制
在生产环境中,错误处理是至关重要的。系统应该能够优雅地处理各种错误情况,包括文件不存在、编码错误、分词失败等。
一个健全的错误处理策略应该包括多个层次。首先是输入验证,检查输入参数的有效性。例如,应该验证文件路径是否正确,文件是否存在。其次是异常捕获,使用try-except块捕获可能出现的异常。再次是错误恢复,在可能的情况下尝试恢复或重试。例如,如果一种编码方式失败,可以尝试其他编码方式。最后是错误报告,向用户清晰地报告发生了什么错误,以便用户采取相应的行动。
日志记录是帮助调试和监控系统的重要机制。系统应该在关键点记录信息,包括输入、输出、错误等。日志应该包含足够的信息以便排查问题,但又不应该太详细导致性能下降。通常,可以设置不同的日志级别,如DEBUG、INFO、WARNING、ERROR等,在不同的环境中使用不同的日志级别。在开发环境中,可以使用DEBUG级别以获得详细的调试信息。在生产环境中,可以使用INFO级别以记录重要事件。
5 关键技术的深入分析
5.1 文件编码处理
在处理文本文件时,编码问题常常是一个陷阱。不同的操作系统和应用程序可能使用不同的编码方式。在Windows上,某些应用程序默认使用GBK或GB2312编码。在Mac和Linux上,通常使用UTF-8。这种差异可能导致文件无法正确读取或显示出乱码。
在Python中,处理编码的最佳实践是明确指定编码。当打开文件时,应该使用encoding参数。然而,如果文件使用的编码事先不知道,需要进行编码检测。chardet库是一个流行的Python库,可以自动检测文本的编码。它通过分析文本的字节模式来推断编码方式。使用chardet库很简单,只需要读取文件的字节,将其传递给chardet的detect函数,就能获得编码方式和检测的置信度。
编码检测的原理是基于不同编码的字节模式特征。例如,UTF-8编码的多字节字符有特定的字节模式,GBK编码也有其特定的字节模式。chardet库通过分析这些模式,可以推断出最可能的编码方式。然而,这种推断不是百分百准确的,因此返回的结果包含一个置信度参数,表示检测结果的可靠程度。
在我们的系统中,我们将实现一个智能的文件读取函数。这个函数首先尝试使用UTF-8编码读取文件。如果失败,则使用chardet库进行编码检测,然后使用检测到的编码重新尝试读取。如果检测的置信度不够高,我们会有多个备选编码,依次尝试。这种方法可以处理大多数常见的编码情况。
5.2 中文路径处理
在Windows和Linux系统上,路径的表示方式不同。Windows使用反斜杠(\)作为路径分隔符,而Linux使用正斜杠(/)。在处理中文路径时,这个问题变得更加复杂,因为需要正确处理包含中文字符的字符串。
Python的pathlib库提供了一个跨平台的方式来处理路径。Path类能够自动处理不同系统上的路径分隔符差异。更重要的是,pathlib库能够正确处理包含中文字符的路径。使用pathlib库的好处是代码变得更加简洁和可读。例如,不需要手动处理路径连接或分隔符转换,Path类会自动处理这些细节。
在打开文件时,可以将pathlib.Path对象直接传递给open函数,Python会自动将其转换为正确的字符串表示。这消除了很多手动路径操作的需要,使得代码更加可靠。Path对象还提供了很多有用的方法,例如exists()可以检查路径是否存在,is_file()可以检查是否是文件,parent可以获取父目录等。
5.3 流式处理与内存优化
当处理非常大的文本文件时,一次性将整个文件加载到内存中可能导致内存溢出。流式处理是处理这个问题的一种方法。流式处理的基本思想是一次只处理文件的一小部分,处理完成后丢弃,然后读取下一部分。这样,内存使用量保持恒定,无论文件有多大。
Python的open函数默认支持流式读取,可以使用for循环逐行读取文件。这在处理超大文件时非常有用。然而,对于总结任务,我们通常需要考虑整个文档的内容,这使得流式处理变得复杂。一种方法是将流式读取与文本分割结合起来,即在读取文件的同时,进行分割并处理。这样可以控制内存使用同时完成处理。
另一个需要考虑的问题是处理的效率。对于非常大的文件,分割成大量小块可能导致处理时间过长。因此,需要在内存使用和处理效率之间进行权衡。通常,可以使用缓冲区的方式,读取一定大小的内容到内存中,处理完后再读取下一部分,这样可以平衡内存和效率。
5.4 图论算法在文本处理中的应用
图论算法在文本处理中有广泛的应用。TextRank算法就是一个例子,它将文本建模为一个图,然后应用图论算法来识别重要的句子。根据Mihalcea和Tarau (2004)的研究,这种方法能够有效地应用于文本摘要和关键词提取任务。
图论算法的基本概念包括图、节点、边和权重。在TextRank中,句子是节点,句子之间的相似度是边的权重。PageRank算法是一个迭代算法,由Brin和Page (1998)首先提出,每一步计算每个节点的得分。得分的更新规则是,一个节点的新得分等于一个基础值加上所有指向它的节点的得分加权平均。
实现PageRank算法需要处理稀疏矩阵和迭代计算。为了提高效率,可以使用邻接表或邻接矩阵来表示图。对于文本总结中的图,通常节点数不是很大(最多几百个句子),所以使用稠密矩阵是可以接受的。
6 系统实现细节
6.1 初始化与配置管理
系统的初始化涉及多个方面。首先是配置的读取。系统需要许多配置参数,如总结方法的选择、摘要长度等。这些参数不应该硬编码在代码中,而应该从外部来源读取。常见的做法是使用配置文件或命令行参数。
配置文件提供了很好的灵活性。可以使用JSON、YAML或INI格式的配置文件。这样,不同的应用场景可以有不同的配置,而不需要修改代码。例如,可能想为不同类型的文章使用不同的总结比例,这可以通过配置文件轻松实现。
命令行参数提供了即时的灵活性。用户可以在运行程序时指定参数,覆盖配置文件中的默认值。这使得系统可以快速地调整行为而无需修改配置文件。
6.2 文本处理流程
文本处理流程包括多个步骤,每一步都很重要。首先是文件的读取。使用之前讨论的方法,正确处理编码和路径。这一步的质量直接影响后续处理的准确性。
其次是文本的清洗。这包括去除多余的空白符,处理特殊符号,去除HTML标签等。对于不同的应用,清洗的程度可能不同。对于新闻文章,可能需要去除标签和元数据。对于学术文章,可能需要保留引用和脚注。
再次是文本的分割。使用之前讨论的方法,按句子或段落分割。分割的粒度应该根据应用的需求进行选择。对于总结任务,分割成句子通常是最合适的,因为摘要也是由句子组成的。
最后是文本的分词。使用jieba库对分割后的句子进行分词。分词的结果是每个句子被分解为词语的序列。这些词语将被用于计算句子的重要性。
6.3 总结算法的实现
在我们的系统中,我们实现了两种主要的总结算法:TextRank和TF-IDF。这两种算法代表了传统自然语言处理方法中最常用的两种方法。
TextRank算法的实现包括以下步骤。首先,构建一个图,其中每个句子是一个节点。然后,计算句子之间的相似度。相似度可以使用多种方式计算,例如两个句子共有词语的数量或余弦相似度。为了避免过度相似的节点占主导地位,可以使用一个相似度阈值,只有当两个句子的相似度超过阈值时才在它们之间建立边。
一旦图构建完成,就应用PageRank算法来计算每个节点的得分。PageRank的迭代公式基于Brin和Page (1998)的原始工作,是:每个节点的新得分等于(1-d)/N + d * sum(PR(i)/L(i)),其中d是阻尼因子(通常设为0.85),N是节点总数,PR(i)是指向该节点的节点的得分,L(i)是指向节点的链接数。
TF-IDF算法的实现相对简单。首先计算所有词的IDF值,基于Spärck Jones (1972)的方法。然后,对于每个句子,计算其中每个词的TF-IDF值,并求和或平均作为句子的得分。
6.4 结果的优化与整理
生成的摘要可能需要进行一些优化。首先,可能需要进行去重,即移除重复的句子或高度相似的句子。这可以通过比较每对句子的相似度,然后移除冗余的句子来实现。
其次,可能需要进行顺序调整。虽然我们通常按原文的句子顺序生成摘要,但有时候可能需要根据内容进行重新组织,例如按照时间顺序或因果关系。
最后,可能需要进行质量检查。例如,检查摘要是否在指定的长度范围内,检查是否包含必要的信息等。
7 实际应用与案例分析
7.1 新闻文章总结
新闻文章总结是一个常见的应用场景。新闻通常有一个明确的结构,包括标题、导语、正文和结尾。导语通常已经总结了新闻的核心内容,生成的摘要应该更加简洁。
在处理新闻文章时,可能需要去除与实际新闻无关的部分,如广告、评论或相关链接。这可能需要一些预处理步骤。
7.2 学术论文总结
学术论文的总结更具挑战性。论文通常包含大量的技术词汇、公式和引用。在总结时需要保留这些技术细节,同时使摘要易于理解。
一个常见的方法是首先提取论文的结构信息,如摘要、关键词、主要发现等。然后,基于这些信息和正文内容生成更加精确的摘要。
7.3 客户评论汇总
在电商和服务领域,经常需要汇总客户评论。大量的客户评论可能包含相似的意见和建议。使用文本总结技术,可以将这些评论浓缩成关键点和主要意见,帮助企业快速理解客户的需求。
7.4 会议记录与备忘录
会议记录通常很冗长,包含很多不相关的讨论。使用自动总结,可以快速生成会议的主要议题、决定和行动项。这大大提高了工作效率。
8 性能优化与扩展
8.1 响应时间优化
在某些应用中,响应时间很重要。如果用户需要等待很长时间才能获得摘要,用户体验会很差。因此,优化响应时间是重要的。
一个方法是使用更高效的算法。例如,TF-IDF通常比TextRank快,因为它不需要构建和处理图。对于大多数应用,TF-IDF提供了一个很好的性能和质量的平衡。
另一个方法是使用缓存。如果相同的文本被多次总结,可以缓存之前的结果,避免重复处理。缓存可以大大提高性能,特别是在处理相似文本时。
8.2 成本优化
对于许多应用,成本是一个重要的考虑。使用本地的自然语言处理方法而不是云端API已经大大降低了成本。进一步的成本优化可以通过选择更快的算法、优化代码效率、减少不必要的计算等来实现。
8.3 算法选择与权衡
在选择总结算法时需要考虑多个因素:性能、质量、速度和可用资源。没有完美的算法选择,只有针对特定应用的最优选择。
对于对质量要求很高的应用,应该选择性能最好的算法,即使它更慢。对于对速度敏感的应用,可能需要选择较快的算法。对于对成本敏感的应用,应该选择消耗最少资源的算法。
8.4 扩展性设计
系统应该能够轻松地扩展以支持新的功能。例如,可能需要支持新的文件格式、新的总结方法或多语言支持。
一个可扩展的设计应该使用插件或策略模式。例如,文件读取可以实现为一个插件系统,每个文件格式有一个对应的读取器插件。同样,总结方法也可以实现为一个插件系统,支持多个不同的总结算法。
9 调试与测试
9.1 单元测试
单元测试是确保代码质量的重要手段。应该为每个函数和模块编写单元测试。单元测试应该覆盖正常情况和边界情况。
对于文件处理模块,测试应该包括正常文件、空文件、非常大的文件、包含特殊字符的文件等。对于文本处理模块,测试应该包括各种编码的文本、包含HTML标签的文本、包含多种语言的文本等。
9.2 集成测试
集成测试是测试多个模块之间的交互。它验证系统的不同部分能否正确地协同工作。
集成测试应该测试完整的工作流,从读取文件到输出结果。应该测试正常情况和错误情况。
9.3 性能测试
性能测试评估系统在各种条件下的表现。应该测试系统在处理不同大小文件时的性能,测试系统在不同的参数设置下的表现等。
9.4 用户验收测试
最后,应该进行用户验收测试,即邀请实际用户使用系统并收集反馈。这种测试可以发现在实验室环境中可能遗漏的问题。
10 最佳实践与建议
10.1 代码组织与可维护性
好的代码组织是长期维护的基础。代码应该被组织成清晰的模块和文件。每个文件应该有明确的职责。相关的功能应该被分组在一起。
文件命名应该清晰明确。应该避免使用通用名称如utils.py,除非这些文件确实包含通用的工具函数。
函数和变量的命名应该是描述性的。好的命名可以使代码的意图清晰明确,减少对注释的需要。
10.2 文档与注释
代码注释应该解释为什么,而不是是什么。如果代码本身清晰,通常不需要注释来解释是什么。但解释为什么做某事的决策往往很有价值。
除了代码注释外,应该有项目级别的文档。这包括README文件,说明项目的目标、功能和使用方法。
10.3 版本管理与协作
使用版本控制系统如Git是必要的。代码的每个版本都应该被标记,重要的改变应该被注释。
在协作开发时,应该使用分支来隔离不同开发者的工作。代码审查是确保代码质量的重要过程。
10.4 持续改进
系统开发不是一个一次性的过程,而是一个持续的过程。应该定期收集用户反馈,根据反馈进行改进。应该跟踪系统的性能指标,识别需要改进的领域。
11 总结与展望
11.1 技术总结
我们在本文中详细讨论了使用Python和传统自然语言处理技术实现自动文本总结系统的各个方面。从理论基础的文本处理和自然语言处理,到具体的系统设计和实现,再到性能优化和实际应用,我们建立了一个完整的框架。关键的技术点包括:正确处理文件编码,使用成熟的分词工具,应用TextRank和TF-IDF等算法,以及合理的系统架构设计。这些技术都有深厚的理论基础。Mihalcea和Tarau (2004)在TextRank上的工作、Spärck Jones (1972)在TF-IDF上的工作、以及Brin和Page (1998)在PageRank上的工作都为我们的实现提供了坚实的理论支持。通过正确地处理这些方面,我们可以建立一个功能完整、质量高、可维护的系统。
11.2 未来展望
文本总结技术仍在不断发展。虽然我们在本文中重点讨论了传统的自然语言处理方法,但随着深度学习技术的成熟,本地运行的神经网络模型也变得越来越可行。未来,我们可能看到更多基于Transformer架构的开源模型能够在普通的计算机上运行,这将进一步提高总结的质量。
多语言总结也是一个重要的研究方向。随着全球化,跨语言的内容处理变得越来越重要。一个系统应该能够处理多种语言的文本,甚至生成不同语言的摘要。
交互式总结是另一个有趣的方向。用户可能想要进一步精化摘要,例如要求总结专注于特定的方面或以特定的风格表达。一个好的系统应该支持这种交互。
11.3 实践建议
对于想要实现类似系统的开发者,有几个建议。首先,从简单的原型开始。不要试图一次性实现一个完美的系统,而应该先实现一个可以工作的基础版本,然后逐步改进。
其次,充分测试。特别是处理不同类型的输入时,充分的测试可以避免意外的错误。编写清晰的测试可以作为代码的文档,帮助新开发者理解代码的行为。
再次,关注用户体验。系统不仅要在技术上正确,还要易于使用。提供清晰的错误消息,提供进度提示,这些都能改善用户体验。
最后,保持代码的简洁和可读性。代码最终是给人读的,计算机会执行。清晰的代码更容易维护、扩展和协作。通过遵循这些原则和最佳实践,我们可以构建出真正高质量、可靠的自动文本总结系统。这样的系统不仅在学术研究中有价值,在实际应用中也能创造显著的价值。
完整代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
自动文章总结系统 - 完整实现(传统NLP方法)
该模块提供了一个功能完整的文本自动总结工具,支持:
1. 中文路径和中文字符的正确处理
2. 自动编码检测
3. 智能文本分割
4. TextRank和TF-IDF算法实现
5. 完全离线工作,无需任何外部API
6. 交互式和命令行两种使用模式
"""
import os
import sys
import re
import math
import logging
from pathlib import Path
from typing import List, Dict, Tuple, Optional, Set
from collections import defaultdict, Counter
from datetime import datetime
# 第三方库导入 - 需要通过pip安装
# pip install jieba chardet numpy
try:
import chardet
except ImportError:
print("缺少chardet库,正在尝试安装...")
os.system("pip install chardet")
import chardet
try:
import jieba
except ImportError:
print("缺少jieba库,正在尝试安装...")
os.system("pip install jieba")
import jieba
try:
import numpy as np
except ImportError:
print("缺少numpy库,正在尝试安装...")
os.system("pip install numpy")
import numpy as np
# ==================== 日志配置 ====================
def setup_logger(log_file: Optional[str] = None) -> logging.Logger:
"""
配置日志系统,支持控制台和文件输出
使用UTF-8编码确保中文字符正确输出
参数:
log_file: 日志文件路径,如果为None则只输出到控制台
返回:
配置好的logger对象
"""
logger = logging.getLogger('TextSummarizer')
# 清空之前的处理器,避免重复日志
logger.handlers.clear()
logger.setLevel(logging.DEBUG)
# 创建控制台处理器,使用UTF-8编码支持中文输出
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setLevel(logging.INFO)
console_format = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S'
)
console_handler.setFormatter(console_format)
logger.addHandler(console_handler)
# 如果指定了日志文件,创建文件处理器
if log_file:
file_handler = logging.FileHandler(log_file, encoding='utf-8')
file_handler.setLevel(logging.DEBUG)
file_format = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
file_handler.setFormatter(file_format)
logger.addHandler(file_handler)
return logger
logger = setup_logger()
# ==================== 文件处理模块 ====================
class FileHandler:
"""
负责处理文件的读写,包括编码检测和中文路径支持
这个类封装了与文件系统相关的所有操作,确保在不同平台上的正确性
"""
@staticmethod
def detect_encoding(file_path: Path, sample_size: int = 10000) -> str:
"""
自动检测文件编码
该方法读取文件的开始部分,使用chardet库分析字节序列来推断编码。
chardet库通过分析字节模式的特征来识别编码方式,例如UTF-8、GBK等
都有特定的字节模式。这种方法对于处理未知编码的文件很有用。
参数:
file_path: 文件路径(Path对象)
sample_size: 用于检测的样本字节数
返回:
编码字符串(如'utf-8', 'gb2312'等)
"""
try:
# 读取文件的前sample_size个字节用于检测
with open(file_path, 'rb') as f:
raw_data = f.read(sample_size)
# 如果文件太小,读取整个文件
if len(raw_data) < sample_size:
with open(file_path, 'rb') as f:
raw_data = f.read()
# 使用chardet检测编码
detection = chardet.detect(raw_data)
encoding = detection.get('encoding', 'utf-8')
confidence = detection.get('confidence', 0)
# 对检测结果的置信度进行验证
if confidence < 0.5:
logger.warning(f"编码检测置信度较低 ({confidence:.2%}),将使用UTF-8作为备选")
return 'utf-8'
logger.debug(f"检测到编码: {encoding} (置信度: {confidence:.2%})")
return encoding if encoding else 'utf-8'
except Exception as e:
logger.error(f"编码检测失败: {e},使用UTF-8作为默认编码")
return 'utf-8'
@staticmethod
def read_file(file_path: str) -> str:
"""
读取文本文件,支持中文路径和自动编码检测
该方法是FileHandler中最重要的方法,它处理了多个编码相关的问题:
1. 正确处理包含中文字符的文件路径(使用pathlib库)
2. 自动检测文件编码(使用chardet库)
3. 处理编码错误的情况(使用errors参数)
参数:
file_path: 文件路径字符串
返回:
文件内容
异常:
FileNotFoundError: 文件不存在
Exception: 无法读取文件
"""
# 将字符串路径转换为Path对象,确保正确处理中文路径
path = Path(file_path)
# 验证文件存在且是一个文件
if not path.exists():
raise FileNotFoundError(f"文件不存在: {file_path}")
if not path.is_file():
raise ValueError(f"路径不是文件: {file_path}")
logger.info(f"开始读取文件: {file_path}")
# 首先尝试使用UTF-8编码读取
try:
with open(path, 'r', encoding='utf-8') as f:
content = f.read()
logger.info(f"成功使用UTF-8编码读取文件")
return content
except UnicodeDecodeError:
# 如果UTF-8失败,进行编码检测
logger.debug("UTF-8解码失败,正在进行编码检测...")
detected_encoding = FileHandler.detect_encoding(path)
try:
with open(path, 'r', encoding=detected_encoding, errors='replace') as f:
content = f.read()
logger.info(f"成功使用{detected_encoding}编码读取文件")
return content
except Exception as e:
logger.error(f"使用{detected_encoding}编码读取失败: {e}")
# 最后的备选方案,使用errors='replace'忽略无法解码的字符
with open(path, 'r', encoding='utf-8', errors='replace') as f:
content = f.read()
logger.warning("使用UTF-8 (忽略错误字符) 读取文件")
return content
@staticmethod
def write_file(file_path: str, content: str) -> None:
"""
写入文本文件,支持中文路径和UTF-8编码
参数:
file_path: 文件路径字符串
content: 要写入的内容
"""
path = Path(file_path)
# 确保父目录存在
path.parent.mkdir(parents=True, exist_ok=True)
with open(path, 'w', encoding='utf-8') as f:
f.write(content)
logger.info(f"成功写入文件: {file_path}")
# ==================== 文本处理模块 ====================
class TextProcessor:
"""
负责文本的预处理和分割
这个类包含了文本清洗、规范化、分词和分割的所有方法,
确保输入到总结模型的文本质量高且格式一致。
"""
# 中文常用的虚词和停词,这些词通常不重要
STOPWORDS = set([
'的', '是', '在', '和', '了', '了', '就', '有', '还', '这', '那',
'不', '也', '能', '又', '很', '要', '把', '被', '给', '比', '最',
'从', '到', '上', '下', '前', '后', '左', '右', '中', '间', '里',
'外', '对', '向', '往', '来', '去', '过', '通过', '为', '与', '因',
'由', '所', '着', '等', '及', '或', '但', '而', '如果', '则', '否',
'a', 'an', 'and', 'are', 'as', 'at', 'be', 'by', 'for', 'from',
'in', 'is', 'it', 'of', 'on', 'or', 'to', 'with', ',', '。', '!',
'?', ';', ':', '、', '"', '"', ''', ''', '【', '】', '(', ')',
'《', '》', '…', '—', ' ', '\n', '\r', '\t'
])
@staticmethod
def clean_text(text: str) -> str:
"""
清洗文本,去除不必要的字符和格式
该方法执行以下清洗操作:
1. 移除多余的空白符
2. 规范化空格和制表符
3. 移除控制字符
4. 处理特殊情况如多个换行符
参数:
text: 原始文本
返回:
清洗后的文本
"""
if not text:
return text
# 移除控制字符(除了换行符和制表符)
text = ''.join(char for char in text if ord(char) >= 32 or char in '\n\t\r')
# 将多个连续的空行替换为单个空行
text = re.sub(r'\n\s*\n+', '\n\n', text)
# 移除行首行尾的多余空格
lines = text.split('\n')
lines = [line.strip() for line in lines]
text = '\n'.join(lines)
# 移除仅包含空格的行
lines = [line for line in text.split('\n') if line.strip()]
text = '\n'.join(lines)
logger.debug(f"文本清洗完成,清洗后长度: {len(text)}")
return text.strip()
@staticmethod
def split_into_sentences(text: str) -> List[str]:
"""
将文本分割成句子
这个方法使用规则和启发式方法来识别句子边界。
对于中文文本,主要使用中文标点符号作为分隔符。
句子边界的正确识别对于后续的总结质量很重要。
参数:
text: 文本内容
返回:
句子列表
"""
if not text:
return []
# 中文和英文的句子分隔符
# 使用贪心匹配来确保不会在分隔符中间分割
sentence_separators = r'[。!?;:,,\n]'
# 首先按照中文标点符号分割
sentences = re.split(sentence_separators, text)
# 过滤空句子并清理
sentences = [s.strip() for s in sentences if s.strip()]
logger.debug(f"文本分割成 {len(sentences)} 个句子")
return sentences
@staticmethod
def split_into_paragraphs(text: str) -> List[str]:
"""
将文本分割成段落
段落由空行分隔。这个方法保留了文本的自然段落结构。
段落是文本的自然逻辑单位,通常由若干相关的句子组成。
参数:
text: 文本内容
返回:
段落列表
"""
if not text:
return []
# 按空行分割段落
paragraphs = text.split('\n\n')
# 过滤空段落并清理
paragraphs = [p.strip() for p in paragraphs if p.strip()]
logger.debug(f"文本分割成 {len(paragraphs)} 个段落")
return paragraphs
@staticmethod
def segment_words(text: str) -> List[str]:
"""
使用jieba库进行中文分词
jieba库提供了多种分词模式:
- 精确模式:分出的词汇最少
- 全模式:分出所有可能的词汇
- 搜索引擎模式:在精确模式基础上,对长词再次分割
我们使用精确模式以获得最准确的分词结果。
参数:
text: 文本内容
返回:
词汇列表
"""
# 使用jieba的精确模式进行分词
words = jieba.cut(text, cut_all=False)
# 过滤停词,只保留有意义的词汇
filtered_words = [w for w in words if w not in TextProcessor.STOPWORDS]
return filtered_words
@staticmethod
def chunk_text(text: str, chunk_size: int = 2000) -> List[str]:
"""
将文本分割成指定大小的块
这个方法用于处理超过一定长度的文本。使用段落和句子的组合方法
来确保不会在单词或句子的中间进行分割,保持语义的完整性。
参数:
text: 文本内容
chunk_size: 每个块的字符数目标
返回:
文本块列表
"""
if not text:
return []
chunks = []
text_length = len(text)
# 如果文本小于chunk_size,直接返回
if text_length <= chunk_size:
return [text]
# 先按段落分割,然后如果段落太长再按句子分割
paragraphs = TextProcessor.split_into_paragraphs(text)
current_chunk = ""
for paragraph in paragraphs:
# 如果加入这个段落会超过chunk_size,开始新的块
if len(current_chunk) + len(paragraph) > chunk_size and current_chunk:
chunks.append(current_chunk.strip())
current_chunk = paragraph
else:
if current_chunk:
current_chunk += '\n\n' + paragraph
else:
current_chunk = paragraph
# 如果单个段落仍然太长,需要进一步按句子分割
if len(current_chunk) > chunk_size * 1.5:
# 对当前块进行句子级别的分割
sentences = TextProcessor.split_into_sentences(current_chunk)
temp_chunk = ""
for sentence in sentences:
if len(temp_chunk) + len(sentence) > chunk_size and temp_chunk:
chunks.append(temp_chunk.strip())
temp_chunk = sentence
else:
if temp_chunk:
temp_chunk += sentence
else:
temp_chunk = sentence
current_chunk = temp_chunk
# 添加最后的块
if current_chunk.strip():
chunks.append(current_chunk.strip())
logger.debug(f"文本分割成 {len(chunks)} 个块")
return chunks
# ==================== 文本总结算法模块 ====================
class SummarizationAlgorithm:
"""
文本总结算法的基类
这个类定义了总结算法的通用接口,具体的算法通过继承这个类来实现。
"""
def summarize(self, text: str, ratio: float = 0.3) -> str:
"""
对文本进行总结
参数:
text: 要总结的文本
ratio: 摘要的目标长度与原文长度的比例(0-1)
返回:
总结文本
"""
raise NotImplementedError("子类必须实现summarize方法")
class TFIDFSummarizer(SummarizationAlgorithm):
"""
基于TF-IDF算法的文本总结器
这个算法的原理是:
1. 计算文本中所有词的IDF值
2. 对每个句子,计算其中所有词的TF-IDF值
3. 按句子的TF-IDF分数排序
4. 选择得分最高的句子组成摘要
TF-IDF方法简单快速,对于大多数文本都能给出合理的结果。
"""
def __init__(self):
"""初始化TF-IDF总结器"""
self.vocab = set()
self.idf = {}
def _compute_idf(self, sentences: List[List[str]]) -> None:
"""
计算所有词的IDF值
IDF值反映了一个词在文本集合中的稀有程度。
如果一个词在很多句子中出现,它的IDF值就会很小,说明它缺乏区分能力。
相反,如果一个词只在少数句子中出现,它的IDF值就会很大。
参数:
sentences: 句子列表,每个句子是一个词列表
"""
# 计算包含每个词的句子数
word_doc_freq = defaultdict(int)
for sentence in sentences:
words_in_sentence = set(sentence)
for word in words_in_sentence:
word_doc_freq[word] += 1
# 计算IDF值
num_sentences = len(sentences)
for word, freq in word_doc_freq.items():
# 使用对数来避免数值太大
self.idf[word] = math.log(num_sentences / (1 + freq))
self.vocab.add(word)
def _compute_sentence_score(self, sentence_words: List[str]) -> float:
"""
计算单个句子的TF-IDF分数
参数:
sentence_words: 句子的词列表
返回:
句子的TF-IDF分数
"""
if not sentence_words:
return 0
score = 0
for word in sentence_words:
if word in self.idf:
# TF是词在句子中的频率
tf = sentence_words.count(word) / len(sentence_words)
# TF-IDF是TF和IDF的乘积
score += tf * self.idf[word]
# 返回平均分数,以避免长句子偏差
return score / len(sentence_words) if sentence_words else 0
def summarize(self, text: str, ratio: float = 0.3) -> str:
"""
使用TF-IDF方法对文本进行总结
参数:
text: 要总结的文本
ratio: 摘要的目标长度与原文长度的比例
返回:
总结文本
"""
# 分割成句子
sentences = TextProcessor.split_into_sentences(text)
if len(sentences) <= 1:
return text
# 对每个句子进行分词
sentence_words = [TextProcessor.segment_words(s) for s in sentences]
# 计算IDF值
self._compute_idf(sentence_words)
# 计算每个句子的分数
sentence_scores = [self._compute_sentence_score(sw) for sw in sentence_words]
# 选择得分最高的句子
num_sentences = max(1, int(len(sentences) * ratio))
top_indices = sorted(range(len(sentence_scores)),
key=lambda i: sentence_scores[i],
reverse=True)[:num_sentences]
# 保持原始顺序
summary_indices = sorted(top_indices)
summary = ''.join([sentences[i] for i in summary_indices])
logger.info(f"TF-IDF总结完成:原文长度={len(text)},摘要长度={len(summary)}")
return summary
class TextRankSummarizer(SummarizationAlgorithm):
"""
基于TextRank算法的文本总结器
TextRank是一个图排序算法,它的原理是:
1. 将每个句子表示为图中的一个节点
2. 如果两个句子共享足够多的词汇,就在它们之间建立一条边
3. 使用PageRank算法计算每个节点的重要性
4. 选择重要性最高的句子组成摘要
TextRank不需要训练过程,可以直接应用于任何文本。
"""
def __init__(self, window_size: int = 3):
"""
初始化TextRank总结器
参数:
window_size: 用于计算相似度的词汇窗口大小
"""
self.window_size = window_size
def _sentence_similarity(self, s1_words: List[str], s2_words: List[str]) -> float:
"""
计算两个句子的相似度
使用词汇重叠的方法来计算相似度。两个句子共享的词越多,相似度就越高。
为了避免短句子的偏差,使用对数来规范化。
参数:
s1_words: 第一个句子的词列表
s2_words: 第二个句子的词列表
返回:
相似度(0到1之间)
"""
words1 = set(s1_words)
words2 = set(s2_words)
# 计算交集的大小
intersection = len(words1 & words2)
if not intersection:
return 0
# 使用对数来避免长句子的过度影响
return intersection / (math.log(len(words1)) + math.log(len(words2)))
def _build_graph(self, sentences: List[List[str]]) -> Tuple[Dict, np.ndarray]:
"""
构建句子相似度图
参数:
sentences: 句子列表,每个句子是一个词列表
返回:
邻接关系字典和相似度矩阵
"""
num_sentences = len(sentences)
# 创建相似度矩阵
similarity_matrix = np.zeros((num_sentences, num_sentences))
for i in range(num_sentences):
for j in range(i + 1, num_sentences):
sim = self._sentence_similarity(sentences[i], sentences[j])
similarity_matrix[i][j] = sim
similarity_matrix[j][i] = sim
return similarity_matrix
def _pagerank(self, similarity_matrix: np.ndarray, iterations: int = 10,
damping_factor: float = 0.85) -> np.ndarray:
"""
计算PageRank分数
PageRank算法的思想是,一个节点的重要性由指向它的其他节点的重要性决定。
迭代地更新每个节点的分数,直到收敛。
参数:
similarity_matrix: 相似度矩阵
iterations: 迭代次数
damping_factor: 阻尼因子(通常为0.85)
返回:
PageRank分数
"""
num_nodes = len(similarity_matrix)
# 初始化分数为均匀分布
scores = np.ones(num_nodes) / num_nodes
# 规范化相似度矩阵,每列求和
col_sums = similarity_matrix.sum(axis=0)
col_sums[col_sums == 0] = 1 # 避免除以零
normalized_matrix = similarity_matrix / col_sums
# 迭代计算PageRank
for _ in range(iterations):
new_scores = (1 - damping_factor) / num_nodes + damping_factor * normalized_matrix.dot(scores)
scores = new_scores
return scores
def summarize(self, text: str, ratio: float = 0.3) -> str:
"""
使用TextRank方法对文本进行总结
参数:
text: 要总结的文本
ratio: 摘要的目标长度与原文长度的比例
返回:
总结文本
"""
# 分割成句子
sentences = TextProcessor.split_into_sentences(text)
if len(sentences) <= 1:
return text
# 对每个句子进行分词
sentence_words = [TextProcessor.segment_words(s) for s in sentences]
# 构建图
similarity_matrix = self._build_graph(sentence_words)
# 计算PageRank分数
scores = self._pagerank(similarity_matrix)
# 选择得分最高的句子
num_sentences = max(1, int(len(sentences) * ratio))
top_indices = sorted(range(len(scores)),
key=lambda i: scores[i],
reverse=True)[:num_sentences]
# 保持原始顺序
summary_indices = sorted(top_indices)
summary = ''.join([sentences[i] for i in summary_indices])
logger.info(f"TextRank总结完成:原文长度={len(text)},摘要长度={len(summary)}")
return summary
# ==================== 总结协调器 ====================
class SummarizerOrchestrator:
"""
总结系统的协调器,负责组织各个模块的协作
这是系统的主要入口点,负责协调文件读取、
文本处理、总结算法选择和结果合并。
"""
def __init__(self, algorithm: str = "textrank"):
"""
初始化协调器
参数:
algorithm: 总结算法的选择,可以是"textrank"或"tfidf"
"""
# 根据选择初始化相应的总结算法
if algorithm.lower() == "textrank":
self.summarizer = TextRankSummarizer()
self.algorithm_name = "TextRank"
elif algorithm.lower() == "tfidf":
self.summarizer = TFIDFSummarizer()
self.algorithm_name = "TF-IDF"
else:
logger.warning(f"未知的算法: {algorithm},使用TextRank作为默认")
self.summarizer = TextRankSummarizer()
self.algorithm_name = "TextRank"
self.file_handler = FileHandler()
self.text_processor = TextProcessor()
logger.info(f"总结系统已初始化,使用算法: {self.algorithm_name}")
def summarize_file(self, file_path: str, output_file: Optional[str] = None,
ratio: float = 0.3, min_length: int = 50) -> Optional[str]:
"""
对文件进行总结
这是系统的主要公共接口。它处理完整的总结工作流:
1. 读取文件
2. 预处理文本
3. 分割文本(如果需要)
4. 生成总结
5. 保存结果
参数:
file_path: 输入文件路径
output_file: 输出文件路径,如果为None则不保存到文件
ratio: 摘要长度与原文长度的比例(0-1)
min_length: 摘要的最小长度
返回:
总结文本
"""
try:
# 步骤1:读取文件
logger.info(f"处理文件: {file_path}")
raw_text = self.file_handler.read_file(file_path)
logger.info(f"文件读取成功,原文长度: {len(raw_text)} 字")
# 步骤2:清洗文本
cleaned_text = self.text_processor.clean_text(raw_text)
logger.info(f"文本清洗完成,清洗后长度: {len(cleaned_text)} 字")
# 步骤3:分割文本(如果需要)
chunks = self.text_processor.chunk_text(cleaned_text, chunk_size=2000)
logger.info(f"文本分割成 {len(chunks)} 个块")
# 步骤4:对每个块进行总结
if len(chunks) == 1:
# 如果只有一个块,直接总结
summary = self.summarizer.summarize(chunks[0], ratio)
if not summary or len(summary) < min_length:
logger.warning(f"摘要过短({len(summary)}字),调整比例重新总结")
# 如果摘要太短,增加比例重新总结
summary = self.summarizer.summarize(chunks[0], ratio + 0.1)
else:
# 如果有多个块,先分别总结,再合并总结
logger.info("使用多阶段总结方法")
chunk_summaries = []
for i, chunk in enumerate(chunks, 1):
logger.info(f"总结第 {i}/{len(chunks)} 个块...")
chunk_summary = self.summarizer.summarize(chunk, ratio)
if chunk_summary:
chunk_summaries.append(chunk_summary)
else:
logger.warning(f"第 {i} 个块的总结为空,跳过")
if not chunk_summaries:
logger.error("所有块的总结都失败")
return None
# 合并所有块的摘要
combined_summary = '\n\n'.join(chunk_summaries)
logger.info(f"块摘要合并完成,合并后长度: {len(combined_summary)} 字")
# 对合并的摘要再进行一次总结以提高质量
logger.info("进行二阶段总结...")
summary = self.summarizer.summarize(combined_summary, ratio)
if not summary:
logger.warning("二阶段总结失败,使用合并摘要")
summary = combined_summary
# 步骤5:保存结果
if output_file:
compression_ratio = len(summary) / len(cleaned_text) * 100 if cleaned_text else 0
output_content = f"""原文件: {file_path}
生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
总结算法: {self.algorithm_name}
原文长度: {len(cleaned_text)} 字
摘要长度: {len(summary)} 字
压缩率: {compression_ratio:.1f}%
========== 文本摘要 ==========
{summary}
========== 原文前500字(用于参考)==========
{cleaned_text[:500]}{'...' if len(cleaned_text) > 500 else ''}
"""
self.file_handler.write_file(output_file, output_content)
logger.info(f"总结结果已保存到: {output_file}")
return summary
except FileNotFoundError as e:
logger.error(f"文件处理失败: {e}")
return None
except Exception as e:
logger.error(f"处理过程中发生错误: {e}")
import traceback
logger.debug(traceback.format_exc())
return None
# ==================== 交互式用户界面 ====================
def print_welcome():
"""打印欢迎信息和使用说明"""
print("\n" + "=" * 70)
print("欢迎使用 AI 文本自动总结工具(基于传统NLP方法)".center(70))
print("=" * 70)
print("\n这个工具可以帮助您快速总结长文章,完全离线运行,无需网络连接。\n")
def select_input_file_dialog() -> Optional[str]:
"""
使用tkinter的文件对话框来选择输入文件
该方法提供了一个图形化的文件选择窗口,用户可以浏览计算机中的文件
并选择要总结的txt文件。这种方式对于不熟悉命令行的用户特别友好。
返回:
选择的文件路径,如果用户取消选择则返回None
"""
try:
# 导入tkinter的文件对话框模块
from tkinter import Tk, filedialog
# 创建一个隐藏的根窗口,用于文件对话框
root = Tk()
# 隐藏根窗口,只显示文件对话框
root.withdraw()
# 打开文件选择对话框
file_path = filedialog.askopenfilename(
title="请选择要总结的文本文件",
filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")],
initialdir=os.path.expanduser("~") # 初始目录为用户主目录
)
# 关闭根窗口
root.destroy()
return file_path if file_path else None
except Exception as e:
logger.error(f"打开文件对话框失败: {e}")
return None
def select_output_file_dialog() -> Optional[str]:
"""
使用tkinter的文件保存对话框来选择输出文件
该方法提供了一个图形化的文件保存对话框,用户可以选择保存摘要的位置和文件名。
如果用户没有选择任何位置,则返回None表示不保存。
返回:
选择的文件保存路径,如果用户取消选择则返回None
"""
try:
from tkinter import Tk, filedialog
# 创建一个隐藏的根窗口,用于文件对话框
root = Tk()
root.withdraw()
# 默认文件名为当前时间戳
default_filename = f"摘要_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt"
# 打开文件保存对话框
file_path = filedialog.asksaveasfilename(
title="请选择保存摘要的位置",
filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")],
initialfile=default_filename,
initialdir=os.path.expanduser("~")
)
# 关闭根窗口
root.destroy()
return file_path if file_path else None
except Exception as e:
logger.error(f"打开保存对话框失败: {e}")
return None
def get_user_input() -> Tuple[str, Optional[str], str, float]:
"""
交互式获取用户输入,使用图形化的文件选择对话框
该函数将引导用户通过图形化窗口选择输入文件和输出文件,
然后在控制台中输入其他参数如算法选择和摘要比例。
这种混合方式结合了图形界面的友好性和命令行的灵活性。
返回:
(输入文件路径, 输出文件路径, 算法选择, 摘要比例)
"""
print_welcome()
# 使用文件对话框获取输入文件路径
print("请在即将打开的窗口中选择要总结的txt文件...\n")
input_file = select_input_file_dialog()
# 如果用户取消了文件选择,则退出
if not input_file:
print("✗ 您没有选择文件,程序退出。\n")
sys.exit(0)
print(f"✓ 文件已选择: {input_file}\n")
# 获取输出文件路径(可选)
output_file = None
save_output = input("是否保存摘要到文件?(y/n,默认为y): ").strip().lower()
if save_output != 'n':
print("请在即将打开的窗口中选择保存摘要的位置...\n")
output_file = select_output_file_dialog()
if output_file:
print(f"✓ 输出文件已选择: {output_file}\n")
else:
# 如果用户在保存对话框中取消,则使用默认文件名
output_file = f"摘要_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt"
print(f"✓ 将使用默认文件名: {output_file}\n")
# 获取算法选择
print("请选择总结算法:")
print(" 1. TextRank (推荐,质量更好)")
print(" 2. TF-IDF (更快)")
algorithm_choice = input("请选择 (1 或 2,默认为 1): ").strip()
if algorithm_choice == '2':
algorithm = 'tfidf'
print("✓ 已选择 TF-IDF 算法\n")
else:
algorithm = 'textrank'
print("✓ 已选择 TextRank 算法\n")
# 获取摘要比例
while True:
ratio_input = input("请输入摘要比例 (0.05-0.95,默认为 0.3): ").strip()
if not ratio_input:
ratio = 0.3
print("✓ 使用默认摘要比例: 0.3\n")
break
try:
ratio = float(ratio_input)
if 0.05 <= ratio <= 0.95:
print(f"✓ 摘要比例已设置为: {ratio}\n")
break
else:
print("比例必须在 0.05 到 0.95 之间,请重新输入。\n")
except ValueError:
print("请输入有效的数字。\n")
print("=" * 70)
print(f"配置已确定:")
print(f" 输入文件: {input_file}")
print(f" 输出文件: {output_file if output_file else '不保存'}")
print(f" 算法: {algorithm.upper()}")
print(f" 摘要比例: {ratio}")
print("=" * 70 + "\n")
return input_file, output_file, algorithm, ratio
def main():
"""
主函数,提供交互式和命令行两种使用方式
优先使用命令行参数,如果没有提供则进入交互式模式。
"""
import argparse
parser = argparse.ArgumentParser(
description='AI文本自动总结工具(基于传统NLP方法)',
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog="""
示例:
python main.py "文章.txt"
python main.py "文章.txt" -o "摘要.txt"
python main.py "文章.txt" -a "tfidf" -r 0.2
python main.py "文章.txt" -a "textrank" -r 0.3
如果不提供参数,程序将进入交互式模式。
"""
)
parser.add_argument('input_file', nargs='?', help='输入文件路径(支持中文路径)')
parser.add_argument('-o', '--output', help='输出文件路径', default=None)
parser.add_argument('-a', '--algorithm', help='总结算法: textrank 或 tfidf',
default='textrank', choices=['textrank', 'tfidf'])
parser.add_argument('-r', '--ratio', type=float, help='摘要比例(0-1)',
default=0.3)
parser.add_argument('--min-length', type=int, help='摘要最小长度',
default=50)
args = parser.parse_args()
# 如果没有提供输入文件,进入交互式模式
if not args.input_file:
input_file, output_file, algorithm, ratio = get_user_input()
else:
# 验证命令行参数
input_path = Path(args.input_file)
if not input_path.exists():
print(f"错误: 输入文件不存在: {args.input_file}")
sys.exit(1)
input_file = args.input_file
output_file = args.output
algorithm = args.algorithm
ratio = args.ratio
if not 0 < ratio < 1:
print("错误: 摘要比例必须在0-1之间")
sys.exit(1)
# 初始化总结系统
try:
orchestrator = SummarizerOrchestrator(algorithm)
except Exception as e:
print(f"初始化失败: {e}")
sys.exit(1)
# 执行总结
print(f"\n开始处理文件: {input_file}")
print(f"使用算法: {algorithm.upper()}")
print(f"摘要比例: {ratio}")
print("-" * 70)
summary = orchestrator.summarize_file(
input_file,
output_file,
ratio,
args.min_length
)
if summary:
print("\n" + "=" * 70)
print("生成的摘要")
print("=" * 70)
print(summary)
print("\n" + "=" * 70)
print(f"总结完成!摘要长度: {len(summary)} 字")
if output_file:
print(f"详细结果已保存到: {output_file}")
print("=" * 70 + "\n")
else:
print("\n✗ 总结失败,请检查错误信息")
sys.exit(1)
if __name__ == '__main__':
main()参考文献
Brin, S., & Page, L. (1998). The anatomy of a large-scale hypertextual web search engine. Computer Networks and ISDN Systems, 30(1-7), 107-117. [可从Google Scholar获取PDF]
Jurafsky, D., & Martin, J. H. (2019). Speech and Language Processing (3rd ed. draft). [在线免费版本:https://web.stanford.edu/~jurafsky/slp3/]
Mihalcea, R., & Tarau, P. (2004). TextRank: Bringing order into texts. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing (pp. 404-411). [可从ACL Anthology获取PDF]
Nenkova, A., & McKeown, K. (2012). A survey of text summarization techniques. In Mining text data (pp. 43-76). Springer US. [可从Springer平台获取PDF]
Spärck Jones, K. (1972). A statistical interpretation of term specificity and its application in retrieval. Journal of Documentation, 28(1), 11-21. [经典论文,可从多个学术数据库获取]
Sun, M., & Huang, C. N. (2016). Chinese word segmentation: A decade review. Journal of Chinese Information Processing, 30(3), 8-20. [中文NLP经典论文]


















 1528
1528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











