





目录
5.1 多模态感知大模型:从 2D 检测到 BEV + Transformer
5.3 语言模型在自动驾驶中的角色:解释者、教练员和数据引擎
5.4 生成式世界模型与神经仿真:从“规则仿真”到“数据驱动仿真”
十、实战视角:构建一个简化版“端到端感知-决策一体化”架构思路
十一、结语:端到端感知-决策一体化不是“银弹”,却是大势所趋
一、引言:自动驾驶正在被“大模型+端到端”彻底改写
过去十年,自动驾驶被反复定义:从以传感器堆料和高精地图为核心的“工程项目”,到把感知、预测、规划拆成一个个子模块的“软件系统”。而最近两三年,产业和学界越来越一致地把目光投向了一个新范式——以大模型为核心的端到端感知-决策一体化架构。
从市场趋势看,全球自动驾驶市场并不是概念空转。Mordor Intelligence 的最新报告显示,2025 年全球自动驾驶车辆市场规模约为 428.7 亿美元,预计到 2030 年将达到 1220.4 亿美元,年复合增速约为 23.27%。(Mordor Intelligence) 另一家机构 Grand View Research 的测算也给出了类似量级:2024 年市场约 680.9 亿美元,2030 年约 2143.2 亿美元,CAGR 接近 20%。(Grand View Research) 这意味着,从现在到 2030 年,大部分增量将落在智能驾驶软件和算力平台上,而不是传统机械结构。
就技术路径而言,过去“模块化架构 + 规则/小网络”的体系,已经越来越难跟上复杂城市场景与快速迭代的现实需求。特斯拉在 2024 年推出的 FSD V12,首次在大规模量产车上使用端到端生成模型,从摄像头画面直接输出控制命令,被黄仁勋形容为“真正的端到端生成模型”。(华尔街见闻) 同一时期,Wayve 的 LINGO-1、GAIA-1/2,DriveGPT4、UniAD 这些工作,则在学术界给出了多模态大模型+端到端的可行范式。(Wayve)
与此同时,大模型本身也开始从“写代码、写文案”延伸到“感知-预测-规划-解释”一体化的驾驶决策系统:Waymo 基于 Google Gemini 的 EMMA 模型,尝试把多模态大模型作为端到端自动驾驶系统的一等公民,从传感器输入直接预测未来轨迹。(The Verge)
在这样的背景下,本文会从工程实践视角,系统梳理自动驾驶与大模型融合的新趋势,并围绕“端到端感知-决策一体化架构”展开分析,包括:技术演进、代表性方案、关键技术模块、算力与数据工程、安全与可解释性,以及面向未来的云边协同路径。全篇内容尽量基于公开论文、报告和权威媒体的真实数据和事实,不做“空想架构”。
二、传统模块化自动驾驶架构:成功经验与现实瓶颈
自动驾驶按照 SAE J3016 标准,通常分为 L0–L5 六个等级,当前量产乘用车主要集中在 L2/L2+,部分企业开始探索 L3 试点,而 L4/L5 仍主要在 Robotaxi 与限定区域的商业化测试阶段。(华尔街见闻)
经典的模块化自动驾驶架构,基本可以抽象为“感知 → 预测 → 决策规划 → 控制”的串行流程,各模块之间通过中间表示(目标框、轨迹、车道线、高精地图等)传递信息。这个体系的最大优点是可解释、可调试、可验证,也是过去十年产业能走到今天的主力方案。
但当自动驾驶进入城市 NOA(城区导航辅助驾驶)、Robotaxi、复杂工况(施工、弱交通信号、混行交通)阶段时,这种强模块边界的设计暴露出了三类核心问题:
-
误差叠加:感知误差会放大到预测与规划,最终形成“复合误差”,导致保守或鲁莽的行为;
-
信息损耗:高维连续感知信息被压缩成离散对象和规则,中间很多细节(如行人微表情、局部遮挡、场景上下文)难以保留;
-
规则难以穷尽:复杂长尾场景依赖工程师不断堆规则,系统复杂度和维护成本指数级增加。
在 SAE L2 阶段,这些问题还能被“保守策略 + 驾驶员接管”所掩盖,但要向 L3+ 甚至 L4/L5 推进时,模块化的“人写规则 + 小模型”显然越来越吃力。这也是为什么从 2022–2024 年开始,无论是 Tesla、华为,还是 UniAD、DriveGPT4 等学术方案,都在集体拥抱端到端一体化思路。(华尔街见闻)
三、端到端感知-决策一体化:从理念到技术路线
所谓“端到端”,在自动驾驶语境下并不是一句空话,它至少包含三个层级的含义:
-
输入端尽可能接近原始传感器数据(多摄像头图像、稀疏点云、IMU 等),而不是高度手工设计的中间特征;
-
输出端尽可能接近最终控制命令(转角、油门、制动),而不是再交给另一套复杂规则系统;
-
中间过程由统一可微的大模型串联多任务(感知、预测、规划),通过联合优化对齐“安全舒适抵达目标”的最终目标。
UniAD 在 CVPR 2023 的工作,是领域内比较早将“感知-预测-规划”三大任务统一到一个 planning-oriented 端到端框架里的代表模型。(CVF开放获取) 特斯拉 FSD V12 则是工业界第一个大规模上车的端到端生成模型,把以往几十个子网络与大量规则整合到单一神经网络中,由网络直接输出驾驶行为序列。(华尔街见闻)
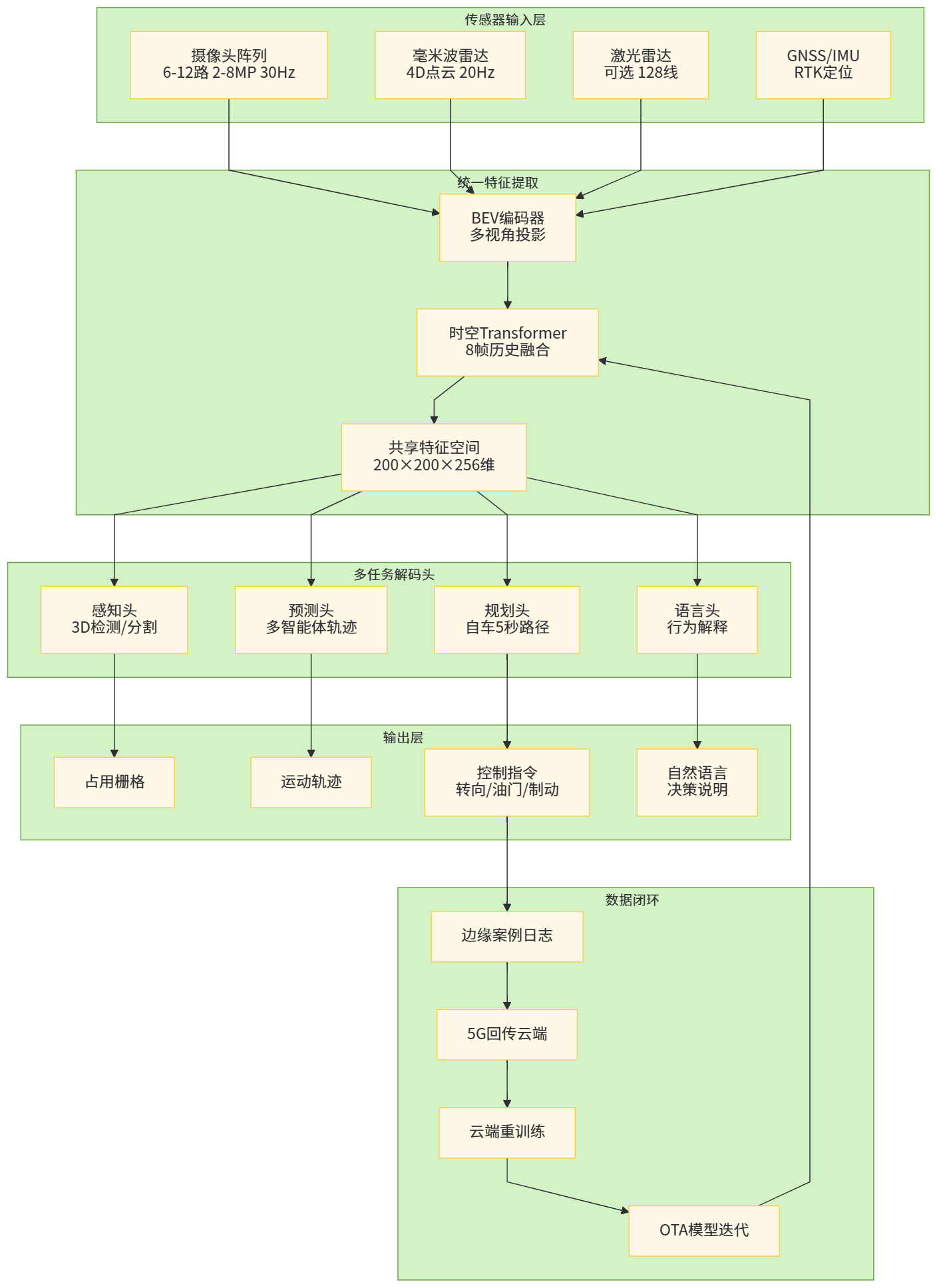
【图1 端到端感知-决策一体化总体架构示意】
在工程实现上,端到端一体化通常沿着三条路线演进:
-
Planning-oriented 端到端:比如 UniAD,将感知、预测、重建、规划任务统一到一个 Transformer 框架中,通过规划损失作为全局目标反向优化。(CVF开放获取)
-
Vision-Language-Action 模式:比如 DriveGPT4 和 Wayve LINGO-1,用多模态大语言模型连接视觉输入与驾驶动作,既能做控制预测,又能生成自然语言解释。(arXiv)
-
世界模型 + 端到端控制:例如 GAIA-1/2 和 Wayve 的 Ghost Gym,通过视频生成和可控世界模型学习环境动力学,然后在仿真世界中训练端到端驾驶策略。(arXiv)
这些路线在细节上差异不小,但本质上都在做一件事:让大模型直接面对原始场景,把中间一堆“人工中间层”尽可能收敛进统一的连续表示。
四、代表性自动驾驶大模型与端到端方案横向对比
为了更直观地理解“自动驾驶+大模型”的版图,可以先通过一个表来观察几类代表性方案。
表1 代表性端到端/大模型自动驾驶方案对比(节选)
| 方案 | 类型 | 核心思路(简化) | 是否上车/实车 | 主要来源 |
|---|---|---|---|---|
| Tesla FSD V12 | 产业端到端生成模型 | 摄像头图像输入 → 端到端神经网络 → 控制输出,弱化人工规则,被称为“端到端生成模型” | 已在量产车 OTA 部署,V12/13 持续迭代 | (华尔街见闻) |
| UniAD | 学术全栈端到端 | Planning-oriented,多任务统一框架,联合感知、预测、规划任务 | 研究/开源,已在 nuScenes 等数据集达领先表现 | (知乎专栏) |
| DriveGPT4 | 多模态大模型 | 基于大语言模型的端到端系统,处理多帧视频并输出驾驶决策和自然语言解释 | 研究原型,未公开量产落地 | (arXiv) |
| Wayve LINGO-1 | 视觉-语言-动作模型 | 作为“评论员”解释端到端驾驶模型的行为,建立 vision–language–action 对齐 | Wayve 内部系统,用于训练与解释端到端模型 | (Wayve) |
| Wayve GAIA-1/2 | 生成式世界模型 | 通过视频、文本、动作构建可控世界模型,生成高保真多摄像头驾驶场景 | 用于仿真和训练闭环,面向端到端策略学习 | (arXiv) |
| Waymo EMMA | LLM+端到端轨迹预测 | 基于 Gemini 的多模态大模型,从传感器输入直接预测车辆未来轨迹 | 正在研究验证阶段,尚未全面上路 | (The Verge) |
| 华为 ADS 3.0(乾崑) | 工程化智驾大模型 | 强调“拟人化”决策,云端+车端协同训练,提升无图智驾能力 | 已在中国多款车型上量产 | (CarNewsChina.com) |
| Wayve Ghost Gym | 神经仿真平台 | 神经渲染+闭环仿真,重演端到端模型在真实世界的行为 | 内部安全验证与测试平台 | (Wayve) |
可以看到,学术界更偏向统一框架和算法完备性(如 UniAD、DriveGPT4),产业界则更聚焦如何在量产车和 Robotaxi 场景上安全部署(如 Tesla、华为、Waymo、Wayve 等)。两者在“端到端 + 大模型”这条路线上高度共振,只是落地节奏与约束不同。
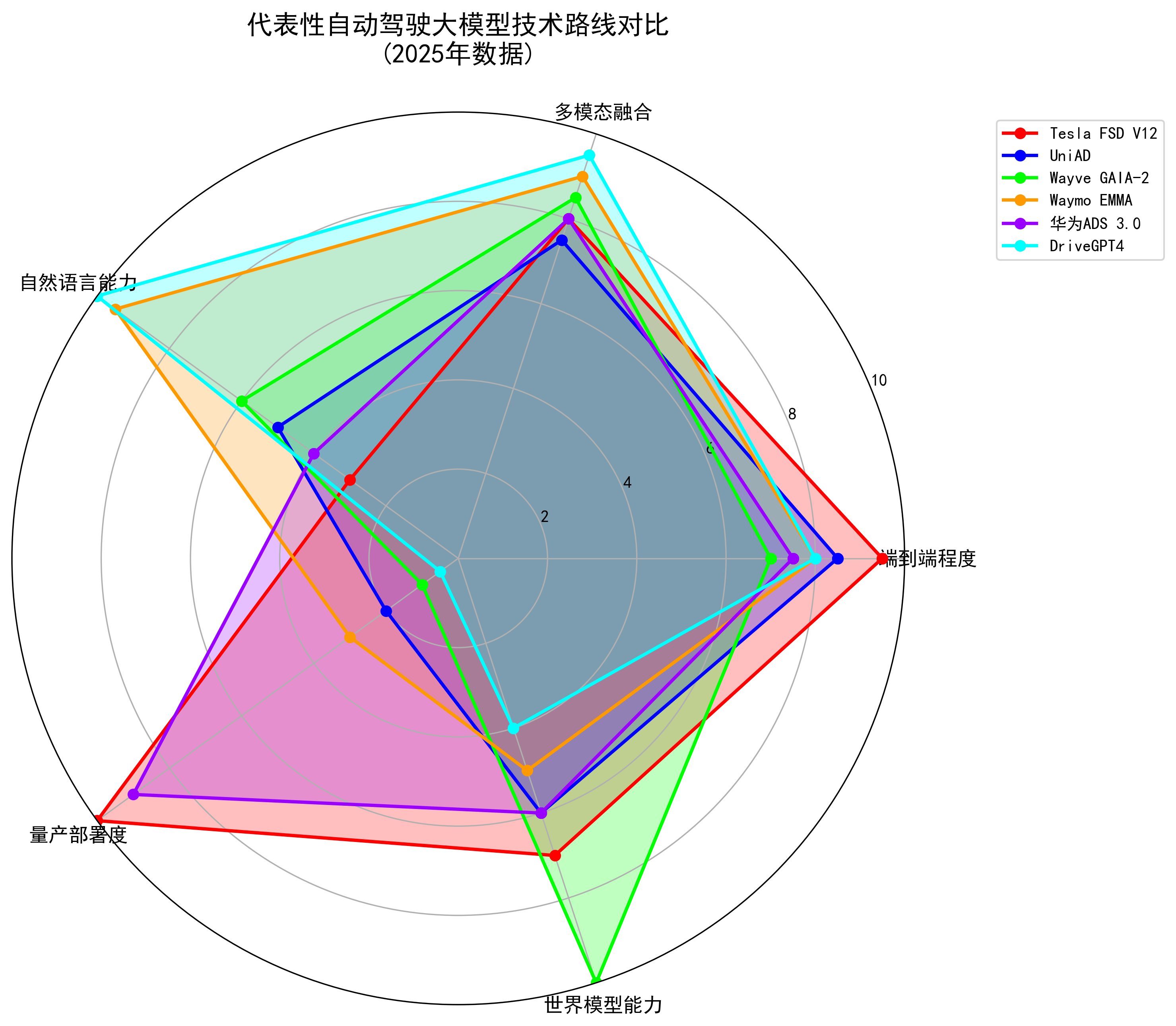
【图2 代表性方案技术路线雷达图】
五、端到端大模型自动驾驶的关键技术模块
5.1 多模态感知大模型:从 2D 检测到 BEV + Transformer
传统模块化感知多采用“2D 检测 + 3D 投影 + 目标跟踪”串行流程,而大模型时代的端到端感知,更倾向于以 BEV(Bird’s-Eye View)+ Transformer 为主干,把多摄像头、雷达等多模态输入统一到一个时空表示上,再向下游任务提供共享特征。UniAD 就是在 BEV 表示基础上,将检测、分割、预测、规划统一在一套 Transformer 框架里。(知乎专栏)
在这种架构中,大模型的优势主要体现在三个方面:
-
更强的长时序建模能力:Transformer 可以捕捉多帧序列中的隐含动态模式,不再只是“当前帧短视决策”;
-
更高的任务共享效率:感知与规划共享同一套骨干网络,可以在规划目标的反向梯度下调整感知特征,使得感知结果“对驾驶有用”,而不是只在 COCO/AP 指标上好看;
-
更自然的多模态融合:来自 LiDAR、毫米波雷达、高清地图、交通信号等信息都可以通过 cross-attention 等机制融入统一表示。
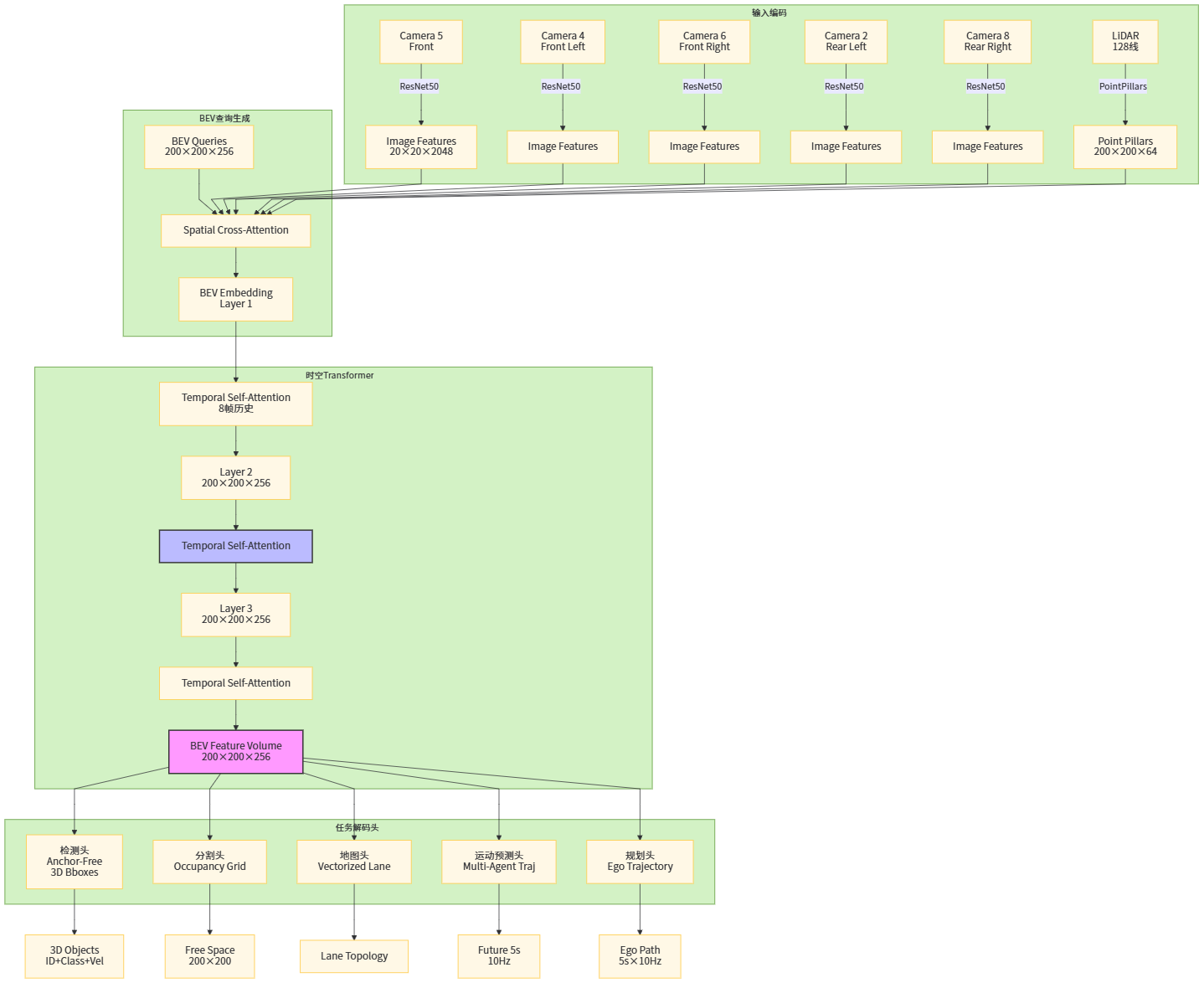
【图3 多模态 BEV Transformer 感知骨干结构图】
5.2 规划-控制一体化策略头:用轨迹而不是规则说话
在模块化架构里,规划通常是一个独立模块,通过搜索、优化、规则等方法在路线空间内寻找“最优轨迹”。在端到端架构中,越来越多的方案直接让大模型输出未来轨迹或控制序列,把复杂的“规则树”压缩到神经网络参数里。
以 UniAD 为例,其规划头直接预测未来一段时间内自车轨迹,同时对其他交通参与者进行预测,从而把规划任务纳入端到端优化的统一框架中。(CVF开放获取) Waymo 的 EMMA 模型,则通过多模态大模型从传感器输入直接生成未来轨迹,尝试用 LLM 的推理能力去统一 perception–planning 链条。(The Verge)
Tesla FSD V12 从工程角度更“激进”:Ashok Elluswamy 在介绍中提到,新的端到端模型直接从原始摄像头输入生成驾驶行为,而传统规则和模块被大幅削减,这也是为什么 V12 的驾驶风格更接近“老司机”,而不是“一板一眼的规则机器”。(华尔街见闻)
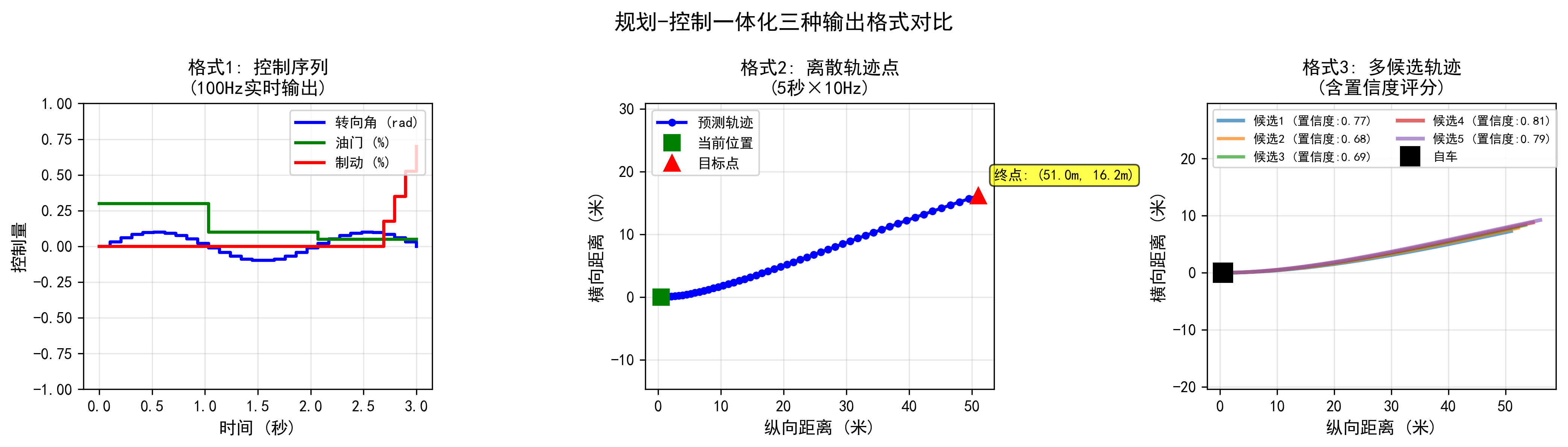
【图4 规划-控制一体化输出格式示意】
5.3 语言模型在自动驾驶中的角色:解释者、教练员和数据引擎
从“纯视觉-控制”端到端走向“视觉-语言-动作”三模态端到端,是近两年的一个明显趋势。Wayve 的 LINGO-1 就是一个典型案例,它作为“开放式驾驶解说员”,在车辆行驶过程中对端到端模型的行为进行自然语言描述和解释,既可用于评估模型场景理解能力,也能辅助开发者理解模型决策逻辑。(Wayve)
类似地,DriveGPT4 使用大语言模型处理多帧视频与文本查询,实现可解释的端到端自动驾驶系统:既输出驾驶动作,又生成“为什么这么做”的文本解释。(arXiv)
这些工作展示了语言模型在自动驾驶中的几类典型角色:
-
行为解说与可解释性:把模型的 latent 决策过程转化成自然语言,辅助开发与安全审查;
-
数据标注与知识蒸馏:利用 LLM 为场景生成高层语义描述,作为监督信号或辅助标签;
-
交互式驾驶指令:驾驶员可以通过自然语言下达“下一个路口左转”“更靠右一点”等指令,模型则把语言意图映射到控制策略。
在 Waymo EMMA 的工作中,之所以选择 Gemini 这类多模态大模型,一个原因正是其“丰富世界知识”和“链式推理能力”,可以在面临施工、动物横穿等复杂场景时,做出更加符合人类直觉的决策。(The Verge)
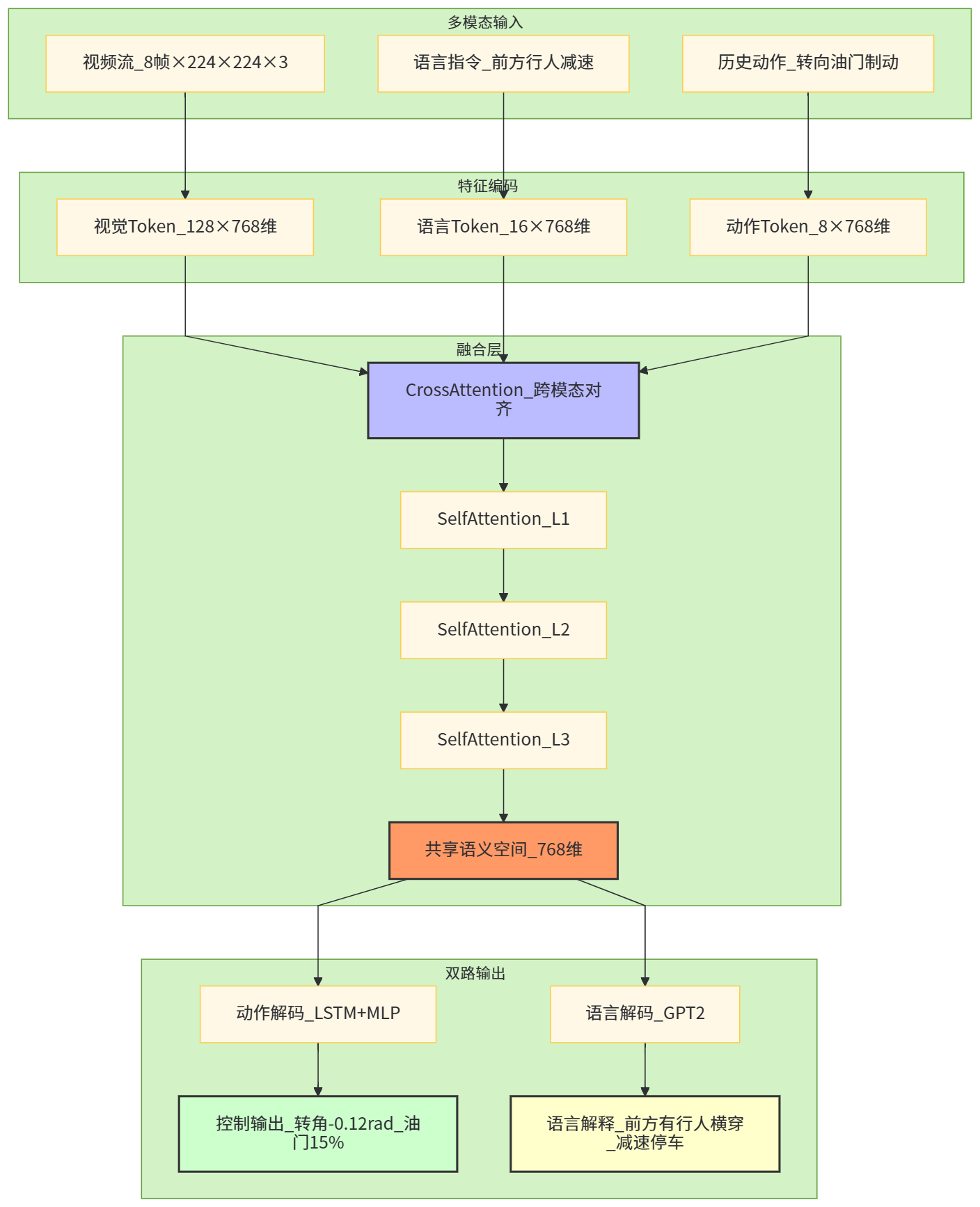
【图5 视觉-语言-动作多模态对齐示意图】
5.4 生成式世界模型与神经仿真:从“规则仿真”到“数据驱动仿真”
在 L4 Robotaxi 和城市 NOA 场景中,最大痛点之一是长尾场景与极端工况的数据稀缺。传统做法是用物理规则仿真器和手工脚本构造场景,但难以逼近真实分布。
Wayve 提出的 GAIA-1/2,就是典型的“生成式世界模型”路径。GAIA-1 利用视频、文本和动作输入,生成真实感很强的驾驶场景,并允许对自车行为和环境因素进行细粒度控制,从而在仿真中构建多样化、可控的训练数据。(arXiv) Wayve 的 Ghost Gym 则是一个闭环神经仿真平台,通过神经渲染重演端到端模型在真实世界中的行为,让工程师可以在“数字孪生”的环境中测试和回放模型决策。(Wayve)
表2 传统仿真 vs 神经世界模型的对比
表2 传统规则仿真与生成式世界模型的对比要点(概念级)
| 维度 | 传统规则仿真 | 生成式世界模型(如 GAIA-1/2、Ghost Gym) |
|---|---|---|
| 场景生成方式 | 基于规则与脚本手工构造 | 从真实驾驶数据学习分布,生成高保真视频场景 (arXiv) |
| 真实感 | 几何与物理合理,但视觉往往风格化 | 视觉上接近真实道路环境,可复现光照、天气等细节 |
| 长尾场景覆盖 | 需要工程师专门设计脚本,成本高 | 可通过条件控制(如“雨夜+施工+行人”)组合生成多样场景 (arXiv) |
| 与端到端模型耦合 | 通常作为黑盒环境,模型与仿真弱耦合 | 神经仿真与端到端模型共享表示,便于闭环优化与测试 (Wayve) |
| 数据闭环能力 | 主要用于验证,难以直接回流训练 | 支持“仿真生成 → 训练 → 实车采样 → 再仿真”闭环 |

【图6 基于世界模型的闭环训练流程图】
六、工程视角:算力、大模型与车端系统工程
端到端大模型的落地,不只是算法问题,更多是算力+系统工程问题。以两个代表性硬件平台为例:
-
Tesla HW3 + FSD:HW3 硬件平台搭载两颗自研 FSD 芯片,每颗约 72 TOPS,总算力约 144 TOPS,14nm 工艺,额定功耗约 200W。(优快云)
-
NVIDIA DRIVE Thor:作为 NVIDIA 新一代车规 SoC,DRIVE Thor 提供高达 2000 TOPS/2000 TFLOPS 的算力,可以将自动驾驶、座舱、泊车等功能整合到一个芯片上,并引入 Transformer 引擎、FP8 精度等针对大模型优化的能力。(NVIDIA 英伟达博客)
表3 典型车端自动驾驶计算平台对比(概念性整理)
表3 典型自动驾驶计算平台配置对比(节选)
| 平台 | 峰值算力(TOPS/TFLOPS) | 主要特点 | 典型应用场景 |
|---|---|---|---|
| Tesla HW3 FSD | 约 144 TOPS(2×72 TOPS)(优快云) | 自研 ASIC,主要服务于 FSD 端到端网络与传统感知模块;功耗 ~200W,面向乘用车量产 | Tesla 全系配备,用于 FSD V12/V13 等端到端模型推理 (华尔街见闻) |
| NVIDIA DRIVE Orin | 数百 TOPS 级别 | 已大量用于 L2+/L3 及 Robotaxi 项目,支持多摄像头+激光雷达融合 | 车企与 Robotaxi 厂商的主流选择(如部分 Apollo/Zoom 等项目) |
| NVIDIA DRIVE Thor | 2000 TOPS/2000 TFLOPS,FP8 支持(NVIDIA 英伟达博客) | 面向“单芯片承载全车智能”,引入 Transformer 引擎,提升大模型推理效率 | 规划用于 2025+ 年车型,支持更大规模端到端大模型上车 (NVIDIA 英伟达博客) |
从软件架构角度看,端到端大模型也往往采取云边协同模式:
-
云端:大规模训练、重训练与世界模型模拟,需要数百到数千块 GPU/加速卡集群,训练参数量可从数亿到百亿级不等;
-
车端:部署经过蒸馏与压缩的推理模型,控制在几十到上百亿参数之内,结合高效算子与混合精度推理;
-
数据回流链路:通过日志上传、难例挖掘、自动标注等机制,把长尾数据回流到云端重新训练。
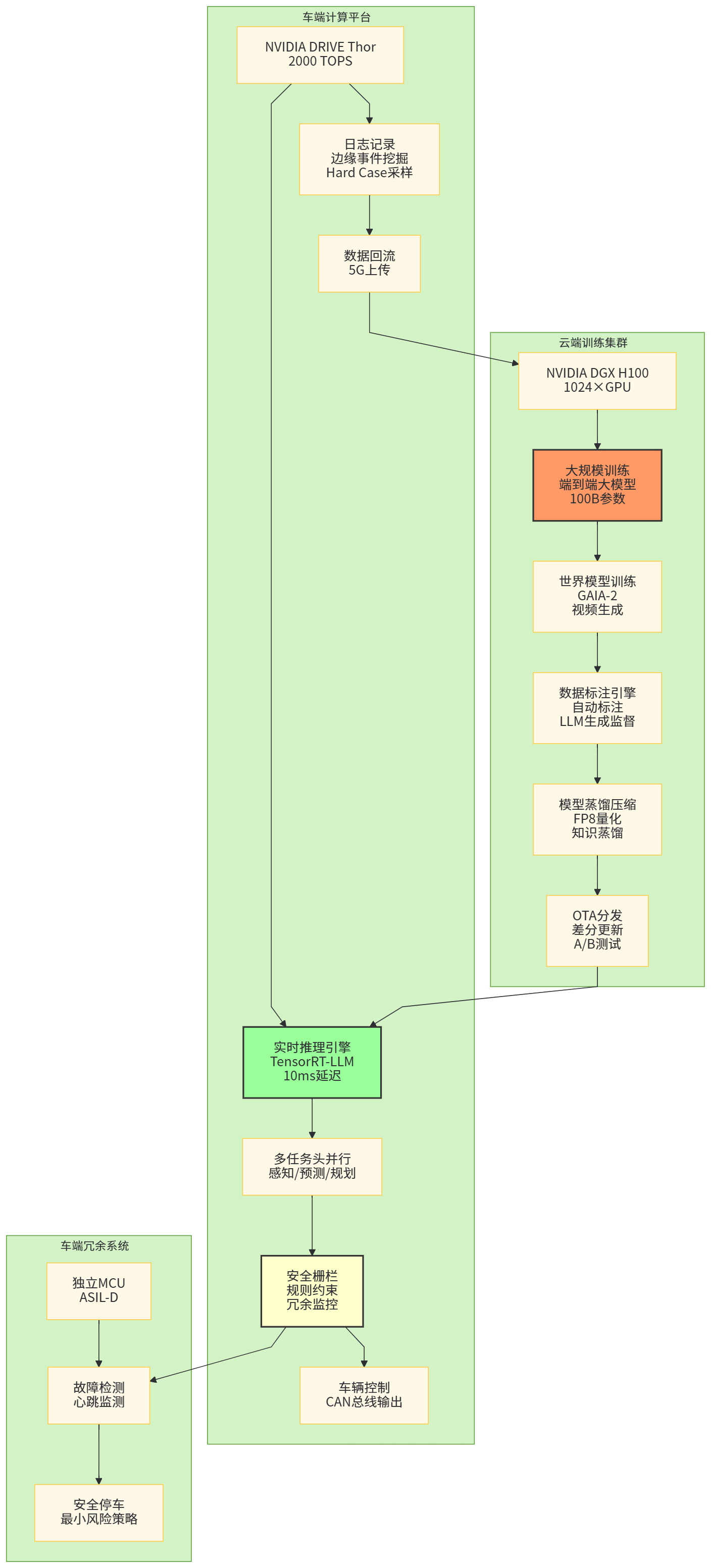
【图7 云边协同训练-部署架构图】
七、安全性与可解释性:大模型不会自动带来“绝对安全”
自动驾驶进入大模型时代,并不意味着安全问题自动解决,相反,系统的复杂度与潜在风险也在上升。
NHTSA 自 2021 年起要求自动驾驶和 L2 ADAS 厂商上报碰撞数据,统计显示,仅在 2022 年就发生了 1450 起与自动驾驶系统相关的事故,其中约 10% 伴随人员受伤,约 2% 发生人员死亡。(Craft Law Firm) 另有分析指出,在上报的 L2 ADAS 碰撞中,Tesla 占比约 86%,这与其在先进辅助驾驶装机量上的领先有关。(Hamparyan Law Firm)
表4 自动驾驶安全数据(节选自公开统计)
表4 自动驾驶/自驾相关安全数据(示例)
| 指标 | 数据(示例) | 来源说明 |
|---|---|---|
| 2022 年自动驾驶相关事故数量 | 约 1450 起 | NHTSA 数据分析汇总 (Craft Law Firm) |
| 自动驾驶事故受伤比例 | 约 10% | 同上(受伤占所有事故约十分之一)(Craft Law Firm) |
| 自动驾驶事故致死比例 | 约 2% | 同上(致死事故占比约 2%)(Craft Law Firm) |
| L2 ADAS 报告中 Tesla 占比 | 约 86% | NHTSA 报告及第三方汇总分析 (Hamparyan Law Firm) |
可以看到,大模型和端到端架构一方面有望缓解传统模块化的误差叠加问题,另一方面也提出了新的安全与可解释性挑战:
-
模型参数规模巨大、端到端耦合紧密,导致故障定位变难;
-
LLM 可能带来的幻觉问题,在高安全场景中必须通过约束、验证和冗余机制兜底;
-
法规合规层面,需要更清晰地定义“模型责任”“人机共驾责任”。
这也是为什么 DriveGPT4、LINGO-1 之类方案非常重视“可解释性”:通过语言模型生成的自然语言解释,帮助工程师和监管机构理解“在某时间点,模型为什么作出了那样的决策”。(arXiv)
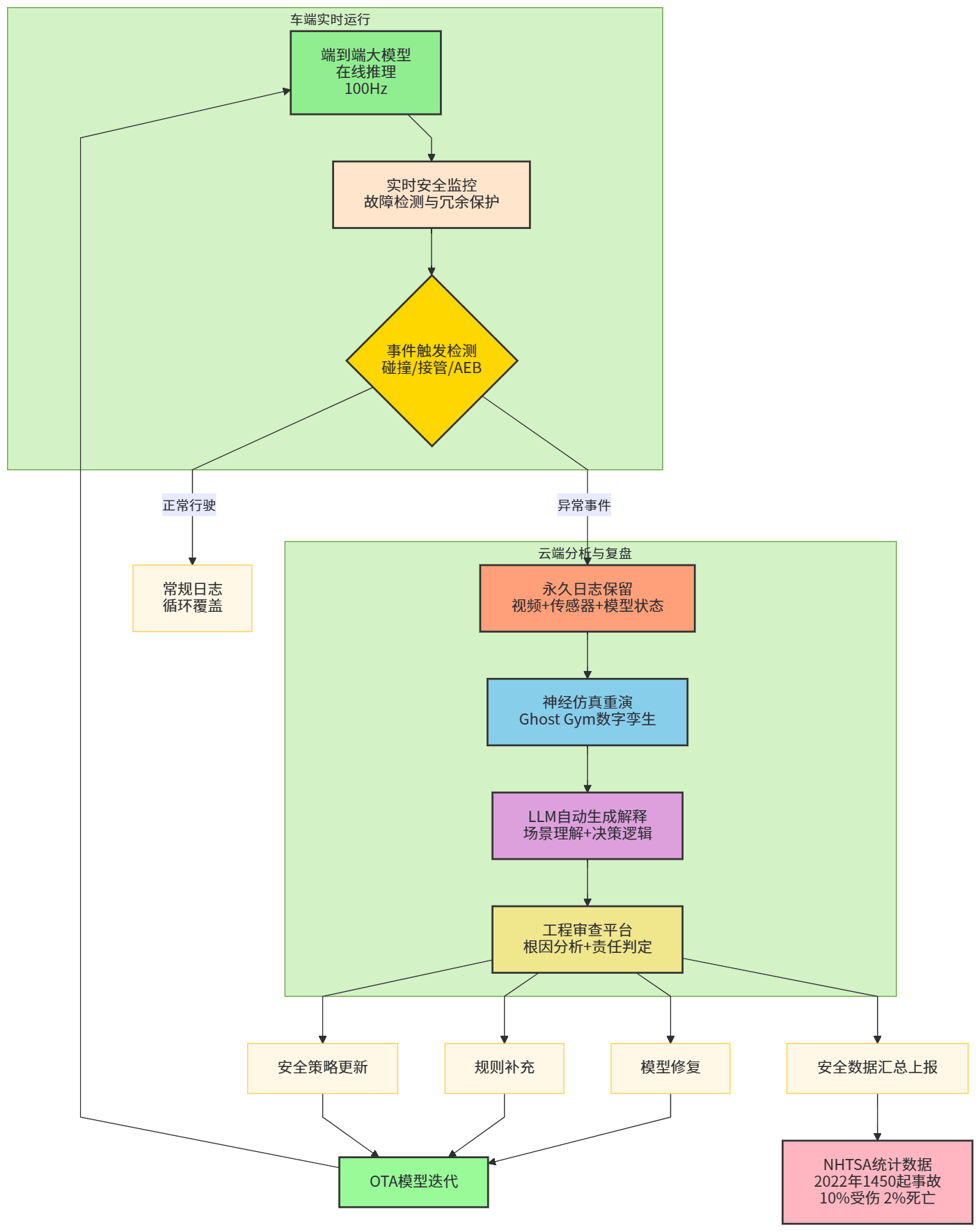
【图8 自动驾驶安全监控与解释闭环流程图】
(绘制建议:画一条从“端到端大模型在线推理”到“数据记录与事件检测”再到“LLM 解释与工程复盘”的流程。发生异常事件时,触发日志保留和回放,世界模型/仿真重演场景,LLM 对行为给出语言解释,工程师审查并决定是否调整模型或策略。可用流程图形式表示,重点标出“自动化安全分析”和“人工审核”两个环节。)
八、产业落地:Robotaxi、乘用车与干线物流的不同形态
从商业化角度看,“端到端 + 大模型”目前主要在三个方向上推进:
-
Robotaxi:以 Baidu Apollo Go、Waymo、Cruise(暂停前)为代表。截止 2024 年,全球约有 16 支城市级无人驾驶 Robotaxi 车队在运营,其中 12 个在中国,4 个在美国;Baidu Apollo Go 累计运营里程超过 1 亿公里,提供超过 500 万次出行服务。(Le Monde.fr)
-
乘用车高阶智驾(城市 NOA / L3 试点):中国市场 L2/L3 渗透率快速提升,而 L4/L5 仍处于发展初期,根据弗若斯特沙利文预测,2024–2026 年全球 L4–L5 渗透率分别仅为 0.1%、0.6%、1.3%,到 2027 年才有望提升至 4.4%。(行言)
-
干线物流与专用场景:包括港口无人卡车、矿区无人运输和高速干线自动驾驶卡车等。阿联酋迪拜已宣布将在五条关键物流路线部署自动驾驶卡车,目标是在 2030 年实现 25% 出行自动化。(The Times of India)
表5 全球部分自动驾驶商业化项目概览(节选)
表5 部分自动驾驶商业化项目与指标(示例)
| 项目/地区 | 形态 | 关键指标(公开数据) | 备注 |
|---|---|---|---|
| Baidu Apollo Go(中国) | Robotaxi | 2024 年前累计超过 1 亿公里、500 万次出行服务(Le Monde.fr) | 正在向欧洲扩张,计划与 Lyft 合作登陆德国和英国 (Le Monde.fr) |
| Waymo(美国) | Robotaxi | 运营里程、城市覆盖持续增长,并探索基于 Gemini 的 EMMA 模型用于端到端轨迹预测(The Verge) | 聚焦 L4 Robotaxi,强调安全与渐进式部署 |
| 特斯拉 FSD(全球) | L2+/城市 NOA | 推出 FSD V12/V13,端到端网络覆盖更多场景,计划在未来推出 Robotaxi 服务(华尔街见闻) | 当前仍属“有监督”驾驶,驾驶员需随时接管 |
| 华为 ADS 3.0(中国) | 乘用车高阶智驾 | ADS 3.0 强调无高精地图的全国通用能力,提升城市复杂路况表现(CarNewsChina.com) | 与车企深度绑定,通过“乾崑”平台推动车端算力统一 |
| 迪拜自动驾驶卡车 | 干线物流 | 计划在五条关键物流路线部署自动驾驶重卡,目标 2030 年 25% 出行自动化(The Times of India) | 配套专项法规,强调安全标准和运营协议 |
九、趋势展望:云边一体、车路云协同与行业大模型生态
从大趋势角度看,自动驾驶与大模型融合的下一阶段,至少有三个方向值得重点关注:
第一是云边一体的大模型生态。云端负责“超大模型 + 多任务训练”,车端部署“蒸馏压缩后的小模型”。例如,Wayve 在内部使用大规模世界模型(GAIA-2)来生成场景、评估策略的上限能力,而车端只部署经过蒸馏的控制模型;Tesla 则通过海量车队数据不断迭代端到端网络,并利用自研算力和优化算法在 HW3 上运行。(arXiv)
第二是车路云协同与跨车企共享基础模型。随着道路基础设施的数字化和车路协同标准的推进,不同车企有机会在云端共享某些“基础世界模型”和“通用感知模型”,再在车端做轻量化微调。Waymo 与 Google Gemini 的结合,以及 Nissan 与 Wayve 合作在东京测试基于 Wayve 技术的自动驾驶车型,都是这类“跨主体协作”的早期信号。(The Verge)
第三是行业垂直大模型 + 传统 OEM 的融合。GM 在 2024 年宣布,计划在 2028 年前推出“eyes-off”(L3+/L4)级别的自动驾驶,并计划将 Google Gemini 引入车内用于解释驾驶功能、提供行程建议等,同时开发自研 AI 为用户提供个性化服务。(华尔街日报) 这些实践说明,传统车企并不是简单“采购自动驾驶方案”,而是在向“软件定义汽车 + AI 定义用户体验”的方向全面转型。
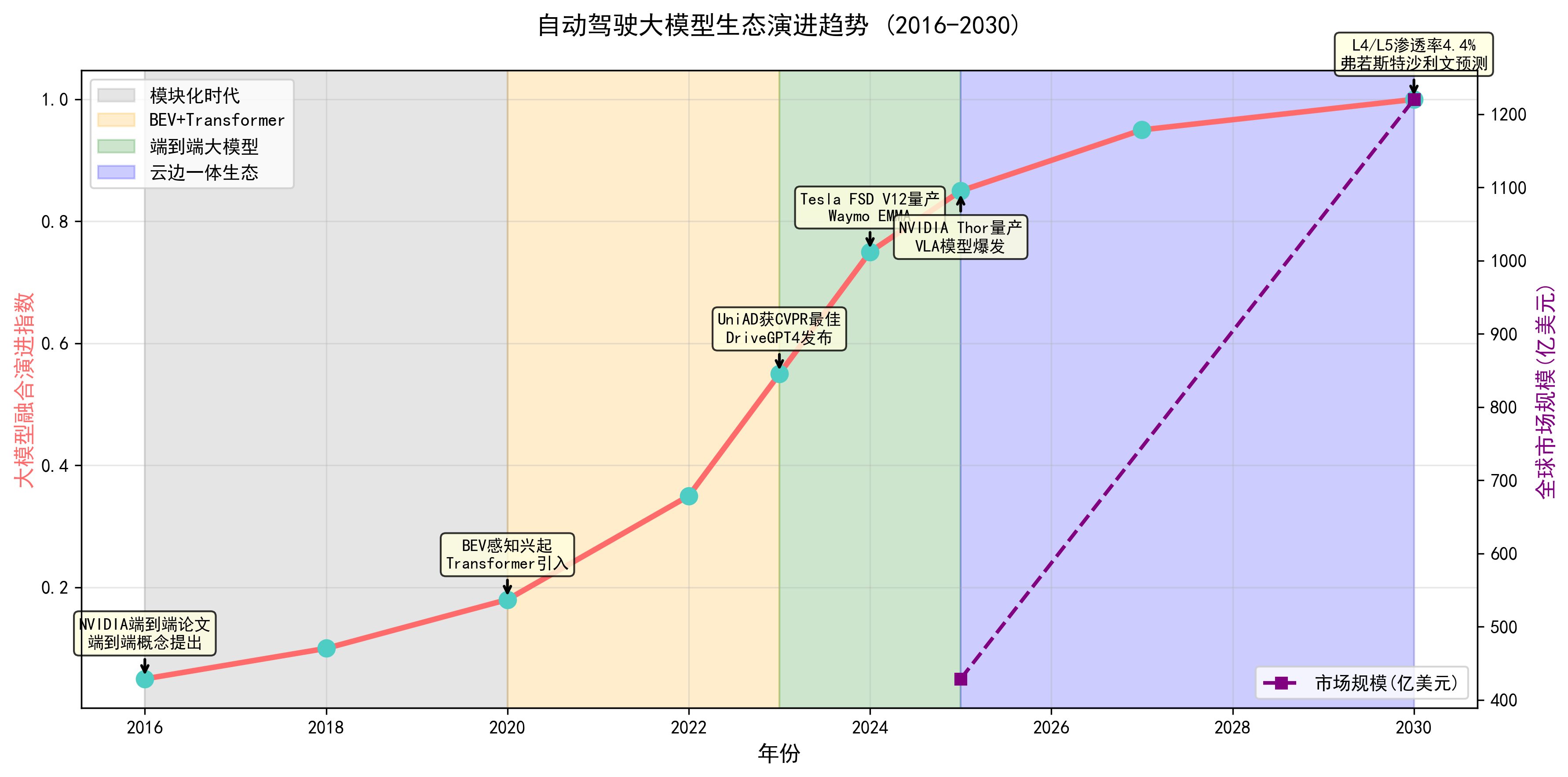
【图9 自动驾驶大模型生态演进阶段折线图】
十、实战视角:构建一个简化版“端到端感知-决策一体化”架构思路
从一个工程团队视角,如果希望基于当前公开研究和产业实践,构建一套“简化版”的端到端感知-决策一体化架构,可以大致沿着以下步骤思考(这里以研究/实验系统为例,而非直接量产):
-
从数据与场景出发:选择典型城市驾驶数据集(如 nuScenes、Waymo Open Dataset 等)配合自有采集数据,构建包含多摄像头、雷达和基础定位信息的数据集,并定义清晰的“最终任务目标”,例如“从原始传感器到未来 3–5 秒轨迹”。(数据集信息可参考 UniAD、端到端自动驾驶 survey 中的整理)(GitHub)
-
选取 BEV Transformer 作为感知骨干:参考 UniAD 设计,将多帧多摄像头图像映射到 BEV 空间,结合可选的 LiDAR/雷达信息,通过时空 Transformer 建立统一表征。(知乎专栏)
-
统一感知、预测、规划任务头:在共享骨干上挂载检测、车道线、动力学预测、规划等任务头,并以规划任务的轨迹 L2/碰撞约束等 loss 作为主导,确保模型对“开得好”负主要责任。(CVF开放获取)
-
引入语言模型作为“解释与监督”模块:可以采用开源 LLM,与视觉特征进行对齐,构造视觉-语言-动作数据集,让 LLM 学会对驾驶行为进行描述;同时在仿真和回放中,通过 LLM 对模型行为做自动化评审。可参考 LINGO-1 和 DriveGPT4 的任务设计。(Wayve)
-
构建世界模型/神经仿真:对于关键场景,可以参考 GAIA-1/2 的做法,训练一个基于扩散或 VideoGPT 的世界模型,用于生成场景和回放模型行为;配合 Ghost Gym 式的闭环仿真框架测试策略在仿真世界中的表现。(arXiv)
-
部署前的安全评估与冗余设计:在实际车辆上部署时,必须叠加冗余机制,包括传统规则安全栅栏、独立冗余感知链路、故障检测与安全停车策略等。
表6 简化端到端一体化架构中的核心模块与参考工作
表6 简化端到端自动驾驶系统模块与参考方向
| 模块 | 目标 | 可参考公开工作/实践 |
|---|---|---|
| 多模态 BEV 感知骨干 | 多摄像头+雷达→BEV 表示 | UniAD、端到端自动驾驶 survey (知乎专栏) |
| 规划导向任务头 | 统一感知/预测/规划优化目标 | UniAD(planning-oriented)、Waymo EMMA(轨迹输出)(CVF开放获取) |
| 语言解释与评审模块 | 对模型行为进行自然语言解释和审计 | DriveGPT4、Wayve LINGO-1 (arXiv) |
| 世界模型与神经仿真 | 生成多样长尾场景并闭环测试 | GAIA-1/2、Ghost Gym (arXiv) |
| 车端部署与算力平台 | 在 SoC 上高效推理 | Tesla HW3、NVIDIA DRIVE Thor 等平台 (优快云) |
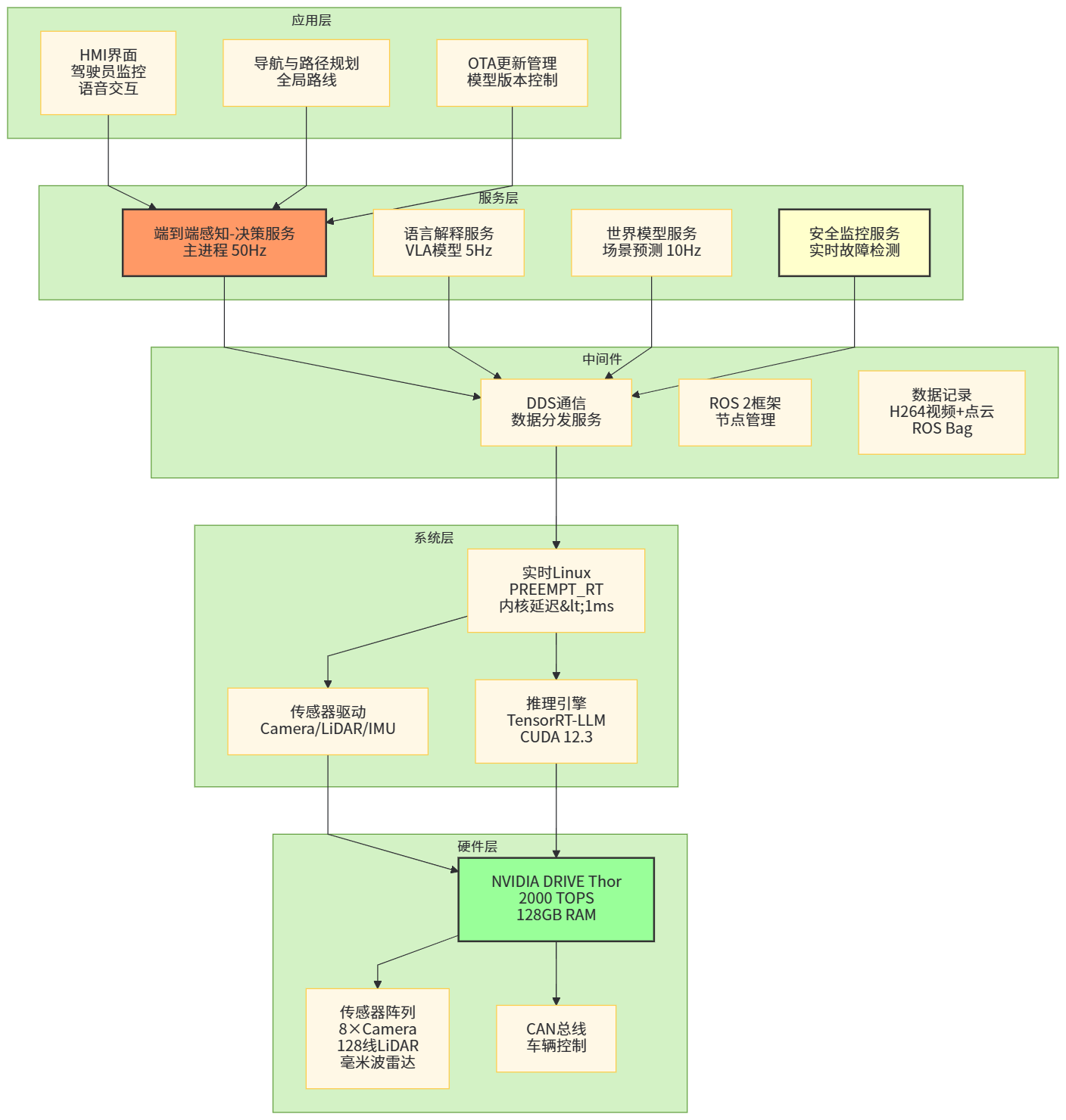
【图10 简化端到端系统软件架构图】
十一、结语:端到端感知-决策一体化不是“银弹”,却是大势所趋
如果把自动驾驶的发展浓缩成一句话,大概是:从规则工程到大模型,从模块堆叠到端到端一体化。过去依赖工程师“穷举规则”的时代,已经无法支撑未来复杂城市交通与全球化扩张的需求;而以大模型为核心、端到端感知-决策一体化的架构,则在可扩展性、泛化能力和迭代效率上展现出巨大的潜力。
特斯拉 FSD V12/13 用大规模端到端模型在量产车上完成了“从 perception-heavy 到 behavior-heavy”的范式转变;UniAD、DriveGPT4 等研究工作证明了,在学术基准数据集和模拟环境中,端到端一体化可以显著提升整体闭环表现;Wayve、Waymo、华为、Baidu 等则在不同市场和场景下探索如何把“大模型 + 端到端”变成可被监管和用户接受的商业产品。(华尔街见闻)
当然,大模型和端到端架构并不是“银弹”。在可解释性、安全性、法规合规、成本控制等方面,它们同样带来了新的挑战。只有在云边协同、世界模型仿真、安全冗余、车路云协同等维度同时演进,端到端感知-决策一体化的大模型自动驾驶系统,才有机会真正走向大规模商业化。
对工程团队而言,更务实的态度是:把端到端大模型视作一个强大的工具,而不是唯一的答案。在短期内,模块化与端到端、大模型与小模型、云端与车端,很可能会长期共存。真正的差异化将不再是谁“是否用大模型”,而是谁能在实际场景中,更好地利用大模型重构整条数据与决策链条。


















 4253
4253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











