








 超级会员免费看
超级会员免费看

1. 引言与背景
视频动作识别是计算机视觉领域的重要任务,其目标是从视频中识别和分类人类动作。传统数据集(如UCF-101和HMDB-51)因规模较小,限制了深度学习模型的性能提升。为此,本文提出了一个大规模数据集——Kinetics,以及一种新型的双流膨胀3D卷积网络(I3D),以更好地捕捉视频的时空特征。
2. 核心方法:双流膨胀3D卷积网络(I3D)
2.1 模型概述
I3D(Inflated 3D ConvNet)是本文提出的核心模型,通过将传统的2D卷积网络扩展为3D卷积网络,能够同时捕捉视频的空间和时间特征。I3D的设计基于以下关键思想:
- 膨胀(Inflation):将2D卷积核扩展为3D卷积核,同时保留预训练的权重。
- 双流架构:结合RGB帧和光流帧,分别捕捉视频的静态信息和运动信息。
- 大规模预训练:在Kinetics数据集上进行预训练,以提升模型在小规模数据集上的性能。
2.2 膨胀3D卷积
2D卷积与3D卷积的关系
传统的2D卷积网络(如ResNet)只能处理静态图像,无法捕捉视频中的时间动态。3D卷积网络通过在时间维度上引入卷积操作,能够同时提取空间和时间特征。
2D卷积公式:
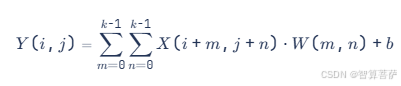
3D卷积公式:
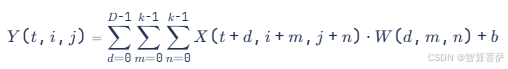
其中:

膨胀操作(Inflation)
膨胀操作的核心是将2D卷积核扩展为3D卷积核,同时初始化3D卷积核的权重为2D卷积核的权重。这种方法能够利用在ImageNet上预训练的2D卷积网络权重,从而加速训练并提升性能。
膨胀公式:
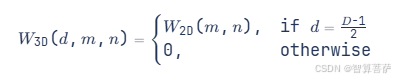
其中:

通过膨胀操作,I3D能够在时间维度上捕捉动态信息,同时保留2D卷积网络的空间特征提取能力。
2.3 双流架构
双流架构是视频动作识别中的经典设计,包含两个独立的分支:
- RGB流:输入视频的RGB帧,提取静态的空间特征。
- 光流流:输入视频的光流帧,提取运动特征。
双流网络的融合方式:
![]()
其中:

双流架构的优势在于能够同时捕捉视频的静态信息(如背景、物体)和动态信息(如动作、运动)。
2.4 模型架构
I3D的整体架构基于Inception-V1网络,通过膨胀操作将其扩展为3D卷积网络。以下是I3D的主要模块:
-
输入层:
- RGB流:输入尺寸为 T×H×W×3 。
- 光流流:输入尺寸为 T×H×W×2 。
- T :时间帧数, H 和 W :帧的高度和宽度。
-
膨胀卷积层:
- 将Inception-V1的所有2D卷积层替换为3D卷积层。
- 卷积核大小为 D×k×k ,其中 D 为时间维度。
-
池化层:
- 使用3D池化操作降低特征图的时间和空间分辨率。
-
分类层:
- 全连接层输出动作类别的概率分布。
I3D架构示意图:
| 层次 | 输入尺寸 | 卷积核大小 | 输出尺寸 |
|---|---|---|---|
| 输入层 | T×H×W×C | - | T×H×W×C |
| 膨胀卷积层 | T×H×W×C | D×k×k | T′×H′×W′×C′ |
| 池化层 | T′×H′×W′×C′ | Dp×kp×kp | T′′×H′′×W′′×C′′ |
| 分类层 | T′′×H′′×W′′×C′′ | - | 动作类别概率分布 |
2.5 预训练与迁移学习
I3D模型在Kinetics数据集上进行预训练,然后迁移到小规模数据集(如UCF-101和HMDB-51)进行微调。实验表明,大规模预训练能够显著提升模型在小规模数据集上的性能。
迁移学习公式:
![]()
其中:

3. 实验与结果分析
3.1 数据集
-
Kinetics:
- 包含400个动作类别,超过400,000个视频片段。
- 每个视频片段长度为10秒,分辨率为 256×256 。
-
UCF-101:
- 包含101个动作类别,13,320个视频。
-
HMDB-51:
- 包含51个动作类别,6,766个视频。
3.2 实验结果
| 模型 | 数据集 | 准确率 (%) |
|---|---|---|
| I3D(RGB流) | UCF-101 | 95.6 |
| I3D(光流流) | UCF-101 | 96.8 |
| I3D(双流) | UCF-101 | 97.9 |
| I3D(RGB流) | HMDB-51 | 74.3 |
| I3D(光流流) | HMDB-51 | 76.4 |
| I3D(双流) | HMDB-51 | 80.2 |
分析:
- 双流架构显著优于单流架构,表明RGB帧和光流帧的互补性。
- 在Kinetics数据集上预训练的I3D模型在小规模数据集上表现出色。
4. 未来研究方向
- 改进双流架构:探索更高效的RGB和光流融合方法。
- 扩展数据集:进一步扩展Kinetics数据集的规模和多样性。
- 结合其他特征:如深度信息、音频特征等,提升模型的多模态能力。
5. 总结
本文提出的I3D模型通过膨胀操作将2D卷积网络扩展为3D卷积网络,结合双流架构和大规模预训练,显著提升了视频动作识别的性能。实验结果表明,I3D在多个数据集上均取得了最优表现,验证了其在捕捉时空特征方面的优势。
关键贡献:
- 提出了膨胀3D卷积的概念,结合2D卷积的预训练权重。
- 构建了大规模Kinetics数据集,为视频动作识别提供了新的基准。
- 验证了双流架构在视频动作识别中的有效性。


















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











