







更好的效果,更低的价格,听起来是不是像梦呓?

限制
首先,让我们来介绍一个词:RAG。
简单来说,RAG(Retrieval-Augmented Generation,检索增强生成) 的工作原理是将大型文档分割成多个小段落或片段。主要原因是,大语言模型的上下文窗口长度有限,无法一次处理超过上下文窗口长度的信息。
当我提出一个问题时,RAG 技术可以先从这些片段中检索相关信息,根据我提问的内容与这些片段的相似度,找出若干个与问题相关的片段,组合成一个上下文,然后将这些信息,连同我的提问一起输入到大语言模型中,然后期待大语言模型「更为精准」的回答。
然而,我们需要考虑一些潜在的局限性。对于一个足够长的文档和一个非常复杂的问题,单靠这几个(仅仅是疑似相关的)片段可能是不够的。真正的答案,也许根本就不在里面。
我们之前讨论了很多关于私有知识库。例如 Quivr, Elephas, GPTs, Obsidian Copilot …… 用久了你会发现,私有知识库提供的回答结果与通过数据微调模型获得的结果可能差异很大 —— 微调后的模型往往能够依据私有数据回答非常复杂的问题,而 RAG 这种简单粗暴的拼接方式,很多时候得到的答案并不理想。
图谱
这些问题就催生了 GraphRAG。GraphRAG 是一种创新的技术,它结合了知识图谱结构和 RAG 方法,旨在解决传统 RAG 方法的局限性。
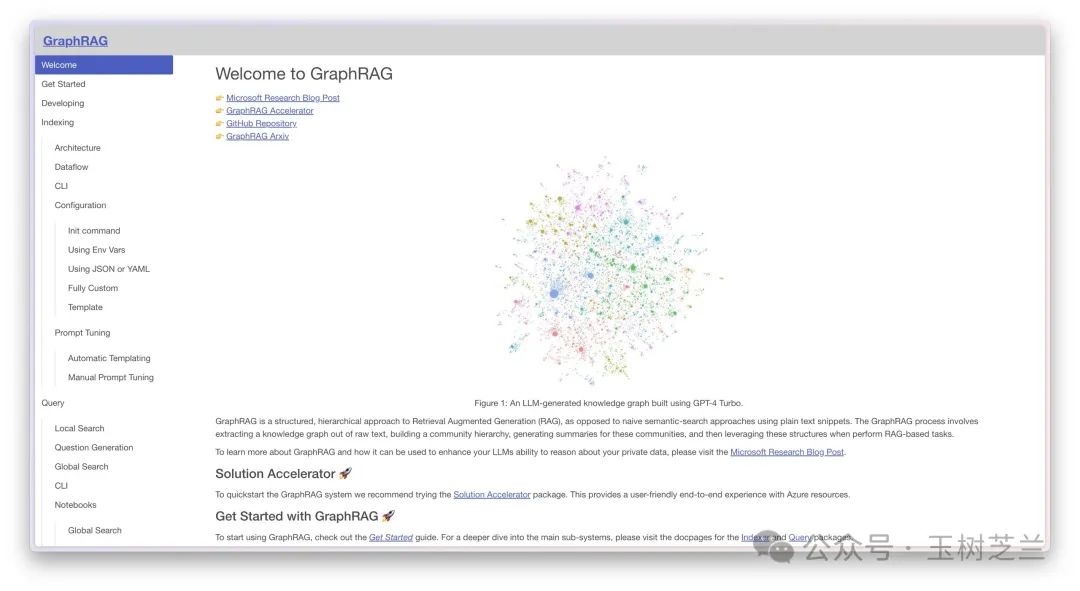
这是微软研发的一个创新产品,它代表了 RAG 技术的最新进展。微软还发布了相关的学术论文,详细阐述了 GraphRAG 的理论基础和技术实现。

那么,这里的 "Graph(图)" 究竟是什么意思呢?在 GraphRAG 的主页上,你会看到一个复杂的图谱。这个图谱不仅仅是一个简单的示意图,它代表了知识的结构化表示。在这个图谱中,每个节点可能代表一个概念或实体,而连接这些节点的边则表示它们之间的关系。
假设图谱中有一个节点是「老虎」,另一个是「兔子」,老虎与兔子之间连一条线,上面写着「吃」,代表二者的关联是「老虎吃兔子」。当然,这只是一个不够严谨的比喻。
有了这样的图谱,为什么要将其与刚才提到的 RAG 结合呢?因为之前提到的「满地找碎片」的传统 RAG 方式实际上效果不佳,所以我们希望将这些概念之间的复杂关系展现出来。在查询时,不再是大海捞针去找「可能相关」的信息碎片,而是根据图谱中已经掌握的关联,提取一整串相连的信息,让大语言模型来一并处理。
这里是 GraphRAG 的 GitHub 网址。它在 GitHub 上的受欢迎程度如何?已经获得超过一万一千颗星。
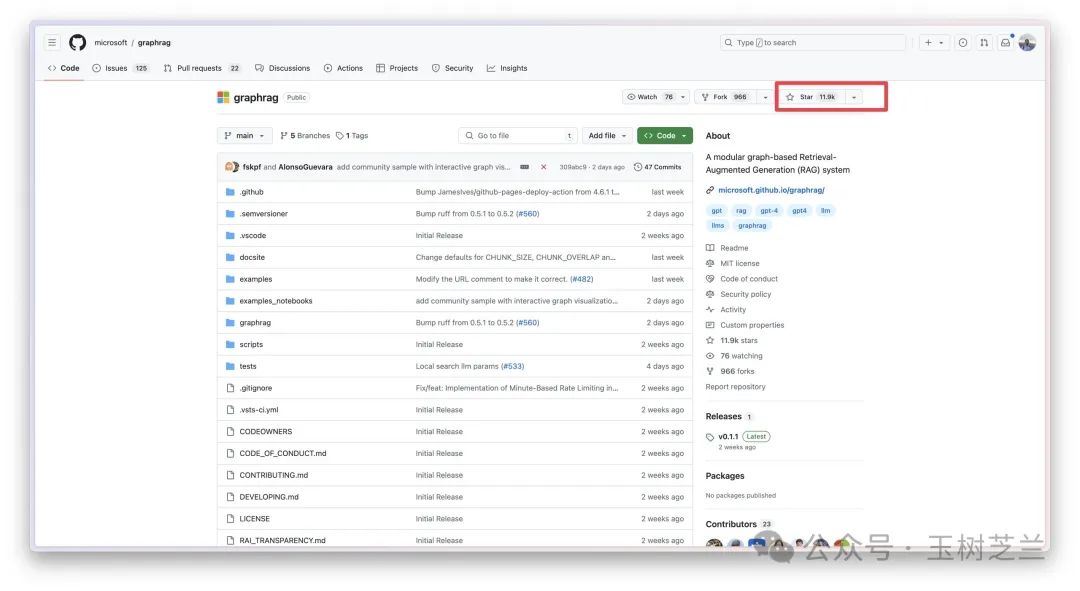
对于一个项目来说,这是一个非常好的成绩,我做梦都希望自己的项目能达到这样的水平。看来还得继续努力。
特点
我们来看看 GraphRAG 的特点。它融合了人工智能的两大流派,一个是深度学习,另一个是知识图谱。
曾经这两个流派是对立的。后来发现对立干啥啊?
你现在用深度学习直接回答效果不好,但如果结合图谱,效果就会强很多。
另一方面,构建知识图谱原来得人工根据规则去抽取其中的实体和关联,那是一个砸钱堆人力的活计。后来发现用上深度学习可以有效提升实体抽取效率。特别是有了大语言模型,人们发现抽取实体和关联变得更加准确、简单且低成本。所以,二者的融合,是大势所趋。
那么融合之后的 GraphRAG 擅长什么呢?它能够把实体之间的复杂关系和上下文串联起来。
正如刚才我们提到的这个过程,它可以连接多个信息点进行复杂查询。这种查询不是简单地提取一部分信息就能完成的。原先根据相似度找出来的这些信息碎片,可能根本不足以支撑问题解答。但现在,根据实际关联获取相关信息,效果要好很多。
另外 GraphRAG 由于对数据集有了整体的刻画,因此概念语义信息得到了充分的表达。
两个特点相夹持,使得 Grap
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3297
3297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









