




 本文探讨了正则化在解决模型过拟合问题中的作用,特别是在特征维度远大于样本数量时的情况。通过引入正则化,可以避免模型过度依赖特定特征,从而提高泛化能力。
本文探讨了正则化在解决模型过拟合问题中的作用,特别是在特征维度远大于样本数量时的情况。通过引入正则化,可以避免模型过度依赖特定特征,从而提高泛化能力。
这个问题是在看正则化的问题引出的,正则化(regularization)是为了解决模型过拟合的问题引出的,为什么会发生过拟合的问题呢,Sparsity and Some Basics of L1 Regularization这篇文章中有提到。
该文章中以线性回归为例,![]() 是数据矩阵,
是数据矩阵,![]() 是由标签组成的列向量。该问题具有解析解
是由标签组成的列向量。该问题具有解析解
![]()
其中p表示的是特征的维度,n表示的是样本数据的数量,当p远大于n的时候,![]() 将会不是满秩的,而这个解也没法算出来。或者更确切地说,将会有无穷多个解。也就是说,我们的数据不足以确定一个解,如果我们从所有可行解里随机选一个的话,很可能并不是真正好的解,总而言之,我们过拟合了。因此我们引入了正则化。
将会不是满秩的,而这个解也没法算出来。或者更确切地说,将会有无穷多个解。也就是说,我们的数据不足以确定一个解,如果我们从所有可行解里随机选一个的话,很可能并不是真正好的解,总而言之,我们过拟合了。因此我们引入了正则化。
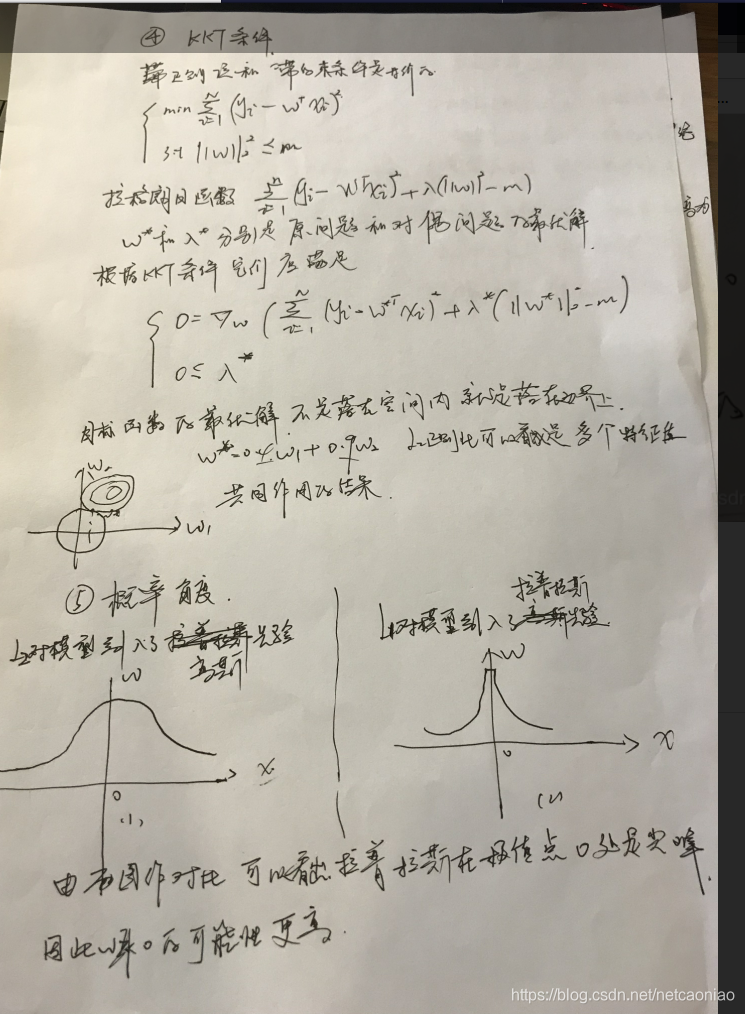
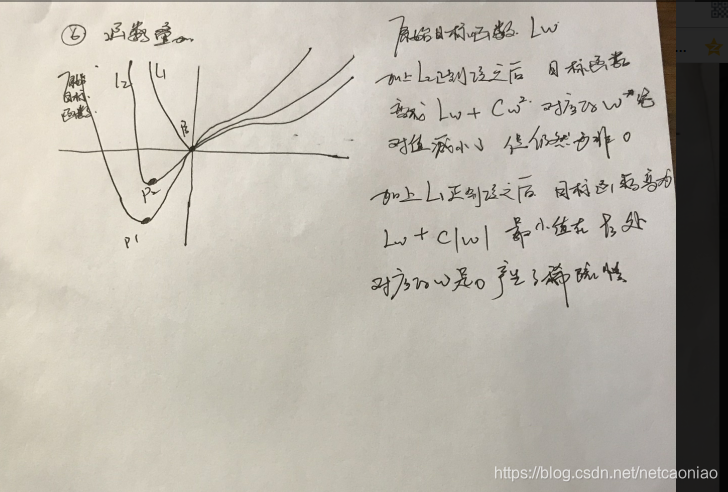
下面从不同的角度来解释l1为什么使模型具有稀疏性:



















 1452
1452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









