



1.数据结构概念
1.概念:
程序 == 数据结构 + 算法
描述数据存储和操作的结构
操作数据对象的方法
2.衡量代码的质量和效率:
1.时间复杂度:数据量的增长与程序运行时间的增长所呈现的比例函数关系,称为时间渐近复杂度函数,也简称时间复杂度
常见的时间复杂度:(低 -> 高)
O(1):程序运行时间维持恒定
O(logn):程序刚开始运行时间可能增长较快,但经过一定数据量后,程序运行时间趋于恒定
O(n):程序运行时间随数据量增长呈现固定的比例关系
O(nlogn)
O(n^2)
O(n^3)
O(2^n)
2.空间复杂度:数据量的增长与程序占据空间的增长所呈现的比例函数关系,称为空间复杂度
3.数据结构:
1.逻辑结构:
线性结构:表(一对一)
非线性结构:树(一对多)、图(多对多)
2.存储结构
顺序存储
链式存储
散列存储
索引存储
3.常见的数据结构:
顺序表
链式表(*)
顺序栈(*)
链式栈(*)
顺序队列(*)
链式队列(*)
二叉树(*)
邻接表
邻接矩阵
2.链表
1.链表:
顺序表(数组)特点:
存储空间连续
访问元素方便
无法利用小的空间,必须连续的大空间
顺序表元素必须为有限的(不存在无限连续的空间)
插入和删除效率低
链表特点:
存储空间不需要连续
可以利用一些小的存储空间
访问元素不方便
链表元素可以没有上限
插入和删除效率高
2.链表分类:
1.单向链表
只能通过链表节点找到后一个节点,访问链表元素的方向是单向的
2.双向链表
能够通过链表节点找到前一个节点和后一个节点
3.循环链表
能够通过第一节点快速找到最后一个节点,能够通过最后一个节点快速找到第一个节点
4.内核链表
linux内核所采用的一种通用的链表结构
3.单向列表
1.定义链表节点类型
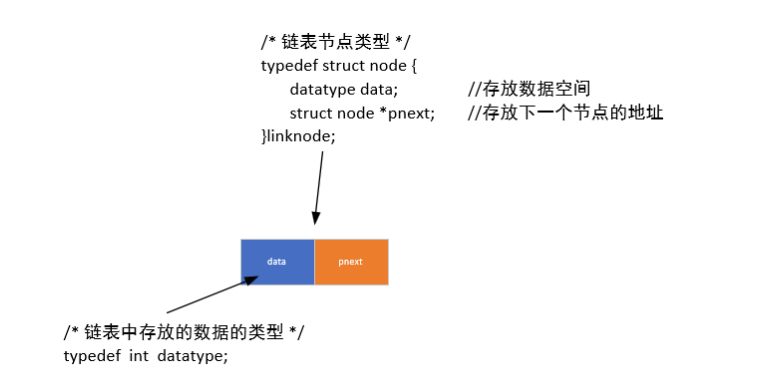

2.空链表的创建:
创建一个空的链表节点
data不需要赋值(最好赋值),空白节点不存放数据,主要为了保证链表操作的便利性
pnext必须赋值为NULL,表示该节点为最后一个节点
将节点地址返回

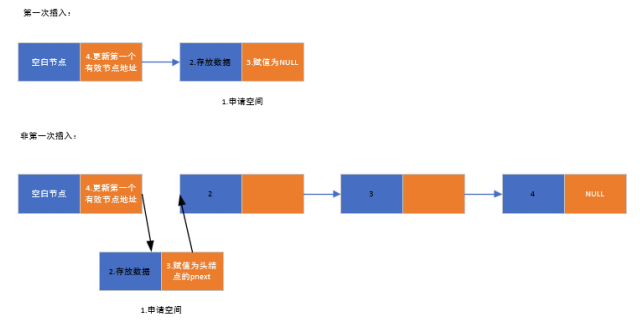
3.链表的头插法:在链表开头插入一个元素
申请新的节点空间
将存放的数据放入新申请的数据空间中
将申请节点的pnext赋值为空白节点的pnext

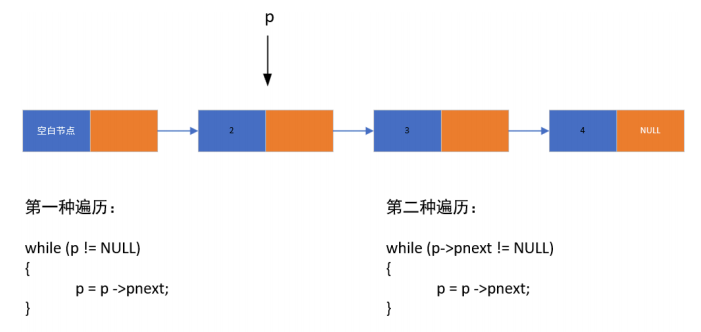
4.链表的遍历:访问链表中的每个节点元素
方法一:用于遍历链表中所有节点元素
方法二:多用于找到链表的最后一个节点

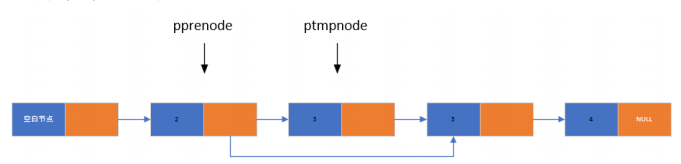
5.链表的删除:
从链表中删除指定的元素
定义两个指针,ptmpnode用来遍历链表查找要删除的节点元素,pprenode永远指向ptmpnode的前一个节点
当ptmpno找到要删除的节点元素,让pprenode->pnext赋值为ptmpnode->pnext
将要删除的节点元素释放
让ptmpnode判断下一个节点元素是否要删除,直到该指针指向NULL为止

3.Makefile
1.Makefile:
工程管理工具,主要用于管理代码的编译
Makefile可以根据文件中的规则来选择符合条件的代码完成编译
Makefile能够根据依赖关系和文件修改的时间戳来决定哪些代码需要编译,哪些代码不需要重新编译
2.Makefile使用规则:
1.在工程目录下,新建一个Makefile或者makefile的文件
2.在Makefile中编写对应的文件编译规则
3.在工程目录下使用make来调用Makefile中的规则完成代码编译
4.编译代码成功后,即可运行可执行程序
3.Makefile语法规则

















 255
255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









