



2025年7月7日学习笔记
一. 模式识别(包含AI问答)
资源:百度网盘通过网盘分享的文件:807资料汇总
链接: https://pan.baidu.com/s/1I6krbu8yPfNgbQK4aVkgHQ?pwd=q9bw 提取码: q9bw
–来自百度网盘超级会员v6的分享
1.在n倍交叉验证中,是否要重置上一轮训练产生的参数,重新从头训练?
(1)交叉验证
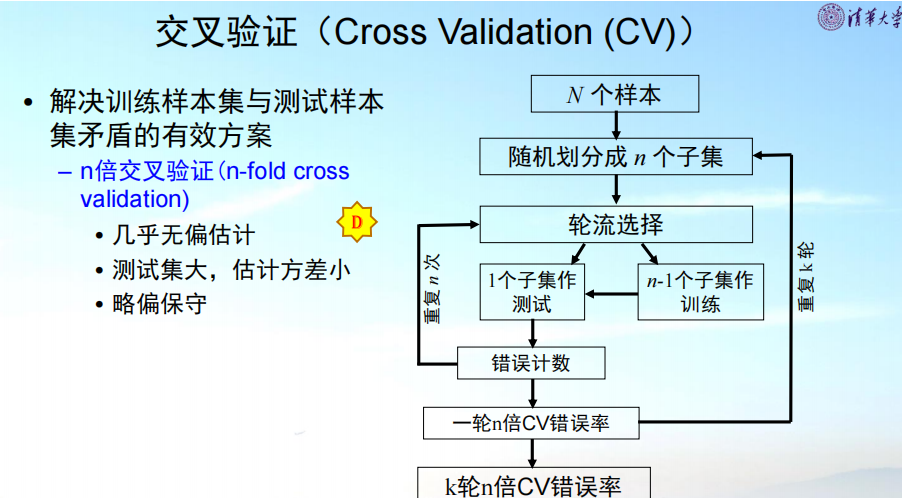
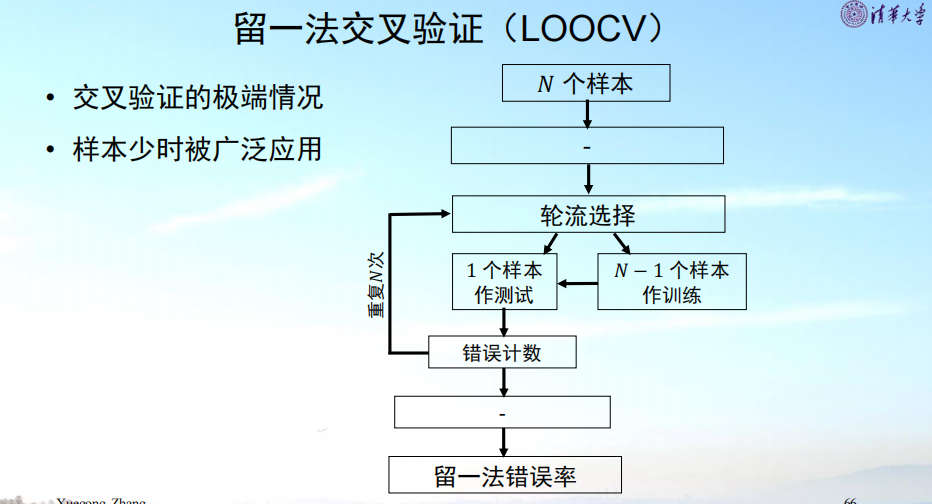
(2)在n倍交叉验证中,是否要重置上一轮训练产生的参数,重新从头训练?
是的,在 n 倍交叉验证中,每一轮(fold)都必须完全重置模型参数,从头开始训练新模型。这是交叉验证正确实施的核心要求,原因如下:
为什么必须重置参数?
-
独立性原则:
- 交叉验证的核心思想是独立评估模型在不同数据子集上的表现
- 如果保留上一轮的参数,相当于模型已经"见过"部分验证数据(通过先前训练)
- 这会破坏验证集的独立性,导致性能评估过于乐观(数据泄露)
-
公平比较:
- 每轮训练都应从相同的初始状态开始
- 否则不同 fold 的模型处于不同的训练阶段,结果不可比
-
准确估计泛化能力:
- 交叉验证的目标是评估算法(而非特定模型)的泛化能力
- 只有每次从头训练,才能反映算法在"全新"数据上的真实表现
正确实施流程(以 5 折交叉验证为例):
代码示例(Python 实现):
from sklearn.model_selection import KFold
from sklearn.linear_model import LogisticRegression
import numpy as np
# 示例数据
X = np.array([[1,2], [3,4], [5,6], [7,8], [9,10]])
y = np.array([0, 0, 1, 1, 1])
# 5折交叉验证
kf = KFold(n_splits=5, shuffle=True)
scores = []
for train_index, test_index in kf.split(X):
# 关键步骤:每轮创建全新模型实例
model = LogisticRegression() # 参数自动重置
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
scores.append(score)
print(f"平均准确率: {np.mean(scores):.2f}")
特殊注意事项:
-
随机种子管理:
- 如果需要可重复性,应在每轮重置模型前设置随机种子
for i, (train_idx, test_idx) in enumerate(kf.split(X)): model = LogisticRegression(random_state=42+i) # 不同fold不同种子 -
超参数优化:
- 当交叉验证用于调参时,每轮应使用相同超参数
- 但模型参数仍需重置
-
预训练模型:
- 如果使用迁移学习(如BERT),每轮应从相同的预训练权重开始
- 而非继承上一轮微调后的权重
错误做法示例:
# 错误:在循环外初始化模型
model = LogisticRegression() # 只创建一次模型
for train_index, test_index in kf.split(X):
model.fit(X_train, y_train) # 错误!参数会累积
score = model.score(X_test, y_test)
# 导致后续fold的数据泄露
💡 黄金法则:
每个 fold = 全新模型实例 + 全新训练过程
这是保证交叉验证结果无偏、可重复的关键!
(3)如何判断选定的特征和类别是否真实存在关系?(利用假设检验思想)

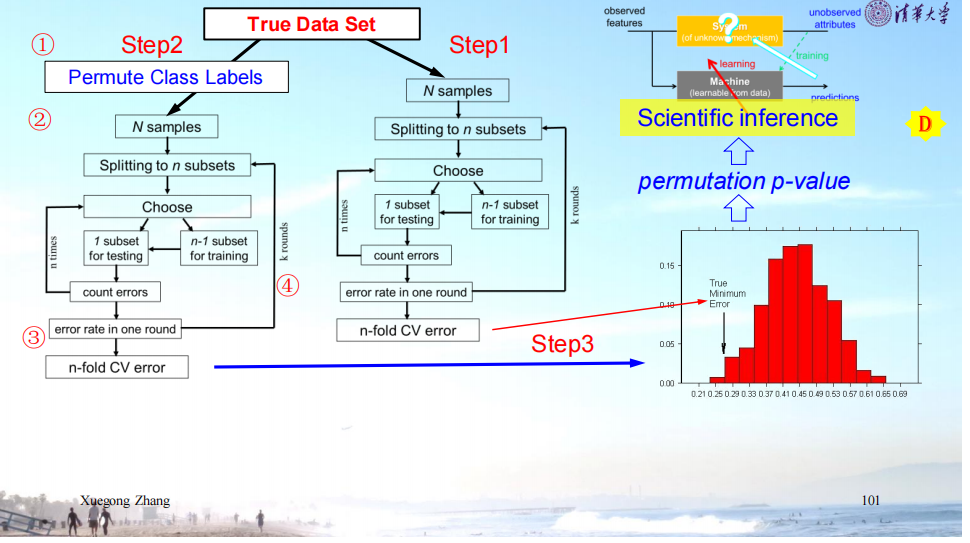
置换检验(Permutation Test)在机器学习性能评估中的步骤:
1.原始数据测试
在未修改的原始数据集上运行机器学习模型
2.置换数据测试
① 数据置换:随机打乱目标变量标签(破坏特征与标签的关联性)
② 模型训练:使用置换后数据完整训练模型(保持训练流程不变)
③ 性能记录:评估模型在置换数据上的性能指标
④ 重复实验:循环执行①-③过程 N 次(例:N=1000)
3.假设检验
对比原始数据性能与置换数据性能分布 → 计算统计显著性(p值)
对每一轮训练后的错误率进行统计,观察原始数据错误率所占概率是否在拒绝域内。
二.python基础——pandas教程
直接上链接: pandas教程(快速入门,纯干货无废话)
三.学习资料
估计明天要停止更新了因为还有两章的书上推理没有学习,今日纸质学习资料:模式识别1-2章,PPT:https://download.youkuaiyun.com/download/mstcoder/91298045

















 1226
1226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









