




深度学习知识点整理 —— batch normalization (批归一化) 与 l2正则化
batch normalization
1. 为什么要有batch normalization?
为什么要做归一化,正常深度学习的学习过程,就是通过学习训练数据的分布,来对测试数据进行预测,所以如果训练数据的分布和预测数据不一致,则学习的速度和泛化能力都会变差。
而深度神经网络中,每一层的输入都是前一层的输出,而前一层的参数是在不断变化的,所以其学习到的数据分布也是不断变化的,所以随着层数加深,后面数据学习到的数据分布就会被影响。
所以batch normalization就是要解决在训练过程中,中间层数据分布发生改变的情况.
2. 它处在网络中的什么位置?
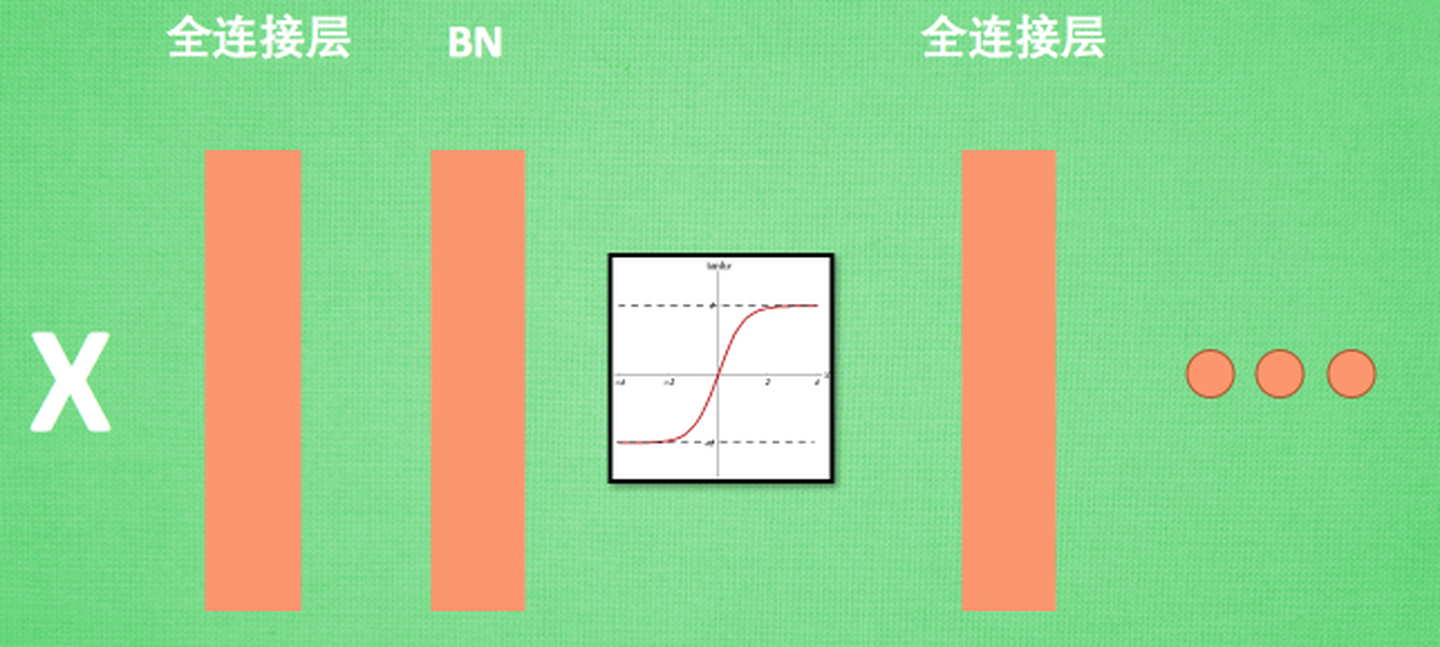
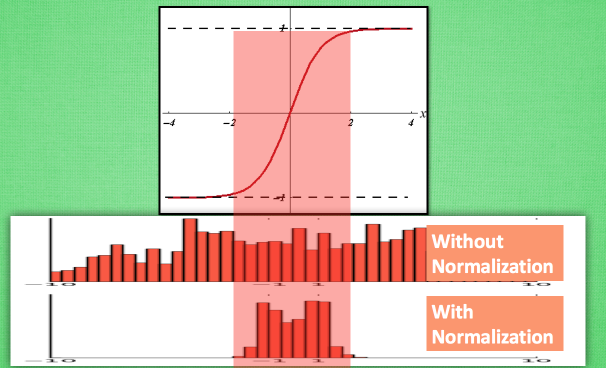
如上图,bn层一般处在全连接层与激活函数之间,为什么要这么做呢,一般的激活函数只有在某个区间内才会比较敏感,超过这个区间的数值则不再敏感,所以数据的分布很重要。BN层可以将数据归一化为均值为0,标准差为1的数据分布,此时对于激活函数则比较敏感。
看到这里可能会有个疑问,本来前面一层我学到了数据的分布,而BN层如果强行把分布变成均值为0,标准差为1的分布的话,不就破坏了特征分布了吗?所以这里还有很关键的一步,叫做:变换重构。其作用就是可以恢复出原始学到的特征分布。

其中:

每一个神经元xk都会有一对这样的参数γ、β。这样其实当:
 、
、 ,就可以恢复出原始的数据分布,这两个参数都是可学习的。
,就可以恢复出原始的数据分布,这两个参数都是可学习的。
BN的本质就是利用优化变一下方差大小和均值位置,使得新的分布更切合数据的真实分布,保证模型的非线性表达能力。
3. BN的过程公式以及源码实现

其中的m就是mini-batch size
源码实现如下:
m = K.mean(X, axis=-1, keepdims=True)#计算均值
std = K.std(X, axis=-1, keepdims=True)#计算标准差
X_normed = (X - m) / (std + self.epsilon)#归一化
out = self.gamma * X_normed + self.beta#重构变换
l2正则化
l2正则化一般加入在损失函数的部分,用来约束模型复杂度。L2约束通常对稀疏的有尖峰的权重向量施加大的惩罚,而偏好于均匀的参数,这就使得网络倾向于学习比较小的权重。所以l2正则也被叫做:权重衰减
我们通过一个例子形象理解一下L2正则化的作用,考虑一个只有两个参数w1w1和w2w2的模型,其损失函数曲面如下图所示。从a可以看出,最小值所在是一条线,整个曲面看起来就像是一个山脊。那么这样的山脊曲面就会对应无数个参数组合,单纯使用梯度下降法难以得到确定解。但是这样的目标函数若加上一项0.1×(w21+w22)0.1×(w12+w22),则曲面就会变成b图的曲面,最小值所在的位置就会从一条山岭变成一个山谷了,此时我们搜索该目标函数的最小值就比先前容易了,所以L2正则化在机器学习中也叫做“岭回归”(ridge regression)。


















 2393
2393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









