



蚁狮优化无缓冲路由在低功耗专用片上网络设计中的应用
1 引言
片上网络(NoC)利用总线结构实现片上系统(SoC)内的互连 [5]。然而,由于集成度不断提高,现代技术的每一项需求都无法通过总线结构得到满足 [24]。因此,用网络结构取代总线结构是最佳解决方案,可实现设备各部分之间的便捷通信 [2]。网络接口(NI)、路由器和链路是NoC的基本组成元素 [15]。网络接口(NI)将IP核连接到网络,以支持包含NoC的数据包传播 [21]。
路由器负责执行数据包路由任务,并通过网络链路与网络接口(NI)相连 [25]。在网络芯片设计中,网络拓扑和路由算法是关键因素,因为数据包路由仅依赖于所选的算法 [16]。
输入/输出端口、缓冲区和交换部分是网络芯片路由器的主要组成部分,具有特定策略以处理数据包冲突和路由过程。数据通过网络以分组形式传输,并由路由器进行处理[12]。因此,路由器的结构设计应实现较低的延迟和高效的吞吐量[22]。缓冲区是一个关键组件,对网络芯片路由器设计的带宽具有重要影响。传统研究中的路由器设计采用有缓冲结构,导致较高的面积和功耗 [9], ,特别是在读/写操作和静态操作期间的动态和静态能耗。缓冲区配置的逻辑设计增加了芯片面积的构建复杂性[20]。
即使每个节点有十六个缓冲区,在需要64 KB存储空间的网络中也只能存储64个数据字节。例如,TRIPS原型的芯片面积中有75%被缓冲器占用[7]。硬件成本和功耗已成为未来缓存式多核芯片的主要限制因素。这成为许多研究人员设计采用无缓冲结构的网络芯片路由器的主要动力。在无缓冲设计中,传输的数据根据路由算法被转发到不同的输出端口[10]。无缓冲路由的数据包传输不考虑目标距离[19]。在网络理论中,无缓冲传输被称为“热土豆路由”,因为数据包(土豆)必须立即传送到其他路由器,信息太“热”而无法保留 (缓冲存储)[3]。
无缓冲路由应满足两个条件:(1)路由器的输入/输出端口必须相同,且 (2)路由器可达并协同工作 [23]。环面、网格、树形和超立方体拓扑结构可用于无缓冲路由 [18]。然而,并非所有网络都适合包含直连链路,因为偏转数据在距离较长时无法到达目标位置 [14]。因此,ALO无缓冲网络拓扑应能容忍此类距离问题,这是一个主要目标。本研究工作的重点是低功耗的ASNoC无缓冲路由设计。因此,采用蚁狮优化(ALO)拓扑来优化功耗。总体而言, ALO拓扑在热土豆路由中,在NoC设计的功耗、面积和延迟方面表现更优。
本文进一步介绍了相关研究的综述,例如ALO‐无缓冲网络拓扑、结果评估和结论,分别对应第2、3、4和5节。
2 相关工作
延迟和功耗是网络芯片互连链路中的重要考虑因素。弹性缓冲器(EB)结构成为解决此类问题的替代方案。因此,Adl 等人 [1]利用EB结构实现芯片设计中的流水线,并结合握手协议进行同步。SELF握手协议具有更高的效率、更低的延迟和功耗,但在七种不同结构中存在工艺偏差问题。双向数据流控制是使用弹性结构的优势之一,使其适用于网络芯片。所考虑的EB在 [1]提供的性能比传统EB结构高出5%。然而,缓冲区的存在占用了芯片设计中更多的面积;因此,我们的研究工作旨在开发无缓冲路由器,同时不降低芯片性能。
Ho 等人 [11]提出了用于数据编码的灵敏放大器半缓冲器(SAHB),以增强四轨的性能特性。高能效ASNOC的异步路由器设计具有三个特点:第一,通过使用导线连接四个路由器,减少了面积开销和晶体管数量;第二,四轨开关减少了不必要的晶体管切换和功耗;最后,所提出的设计在工艺‐电压‐温度 (PVT)变化下具有高工作频率和准确结果。该设计采用65纳米CMOS技术实现准延迟无关(QDI)‐SAHB。此设计所需面积减少32%,能效提高50%,并具有高操作鲁棒性。因此,与本工作相比,无缓冲路由器在面积和功耗方面可实现更优的性能。
Fang 等人 [8]基于能耗和通信偏差评估了各种路由器容量。异构片上网络包含GPU核心、CPU以及存储器和缓存控制器。本研究在不降低性能行为的情况下,实现了44.6%的能耗折衷。还讨论了多种缓冲区分配策略下的不同流量负载模式及其能耗延迟。CPU‐GPU应用的基准行为已按每千周期进行表征和分类。缓冲区分配策略被作为主要目标进行分析,并与现有方法进行了比较。此外,本研究工作中还可实现无缓冲区路由的进一步性能提升和改进。
基于彩票仲裁机制的网络芯片路由器3D架构已由Karthikeyan 和 Kumar 开发[13]。为不同端口实现独特优先级适用于多种应用。该模型引入了3D彩票路由器及其相关仲裁器功能,并合理利用了轮询机制。辅助网络资源获得基于高优先级的数据包传输。本研究与另一种3D路由器设计的比较表明,性能更优,主要体现在功耗降低9%。基于GALS的彩票算法是[13]传统彩票算法的扩展版本,旨在实现优于传统彩票算法的性能。
巴布等人引入了改进的基于网络接口的空间分复用NoC [4]以研究功耗和计算复杂性。由于芯片面积的优化,该接口在降低功耗方面的整体性能得到提升。在本分析中,现场可编程门阵列资源利用率为仅4%,且实现了约一半的面积优化。同样,功耗比其他对比方法低2%,并且本文还建议改进无缓冲片上网络路由器的灵活性。因此,这项关于热土豆路由的综述成为我们研究中设计和实现基于ALO的无缓冲路由的关键动机。
3 基于ALO的无缓冲路由方法
缓冲是网络传输的主要功能,其尺寸优化已成为众多研究人员的研究目标。带缓冲区的路由器占用更多的芯片面积,导致功耗较高。因此,简化路由器架构并去除缓冲区组件成为研究工作的主要焦点。流水线寄存器、仲裁逻辑和交叉开关是无缓冲路由器中的主要组成部分。在竞争期间将分组传输到其他可用端口,这就是无缓冲路由的概念。然而,分组的常规偏转或重传会严重影响网络性能。对于所有网络应用而言,低延迟、高服务质量(QOS)以及更高的吞吐量是必需的。为了满足这些要求,采用ALO对无缓冲NoC进行优化。利用 ALO方法对分组优先级排序、交换机制和路由器端口分配进行优化。基于 ALO的无缓冲路由工作的主要贡献如下:
提出基于热土豆路由的ALO拓扑用于ASNOC的路由器设计。
•在Xilinx平台上实现基于ALO的无缓冲路由工作。
•通过实现来分析使用基于ALO的无缓冲路由方法的ASNOC的功耗、延迟和面积消耗。
•通过与现有技术进行比较,评估基于ALO的无缓冲路由工作。
无缓冲路由器的架构如图1所示,包含注入/引出端口、路由计算单元和仲裁模块。输入分组通过路由计算单元进入路由器,相关结果保存在相应的端口。通常情况下,数据包路由遵循ALO算法,该算法为传输选择确切的输出端口,并将计算结果存储在特定端口中。剩余的一组可能的跳转路径将保存在可用 (所有其他可能)端口中。
3.1 ALO路由拓扑
输入分组的优先级取决于其跳数,即从源到目的节点传递信息所需的路由器数量。优先级处理过程是在路由器中执行数据对齐,将数据按从高到低的优先级进行传输。当目标路径繁忙时,可将分组偏转至其他端口。输入和输出端口相似,因此链路的故障发生是双向的。基于ALO的路由算法利用故障向量诊断故障链路,并帮助通过无故障链路传输数据。

图 2 所示的输入分组包含 V、A、B、HC 和有效载荷端口,分别表示分组有效性、源地址和目的地址、跳数和消息。考虑从节点 X 到 Z 经由 Y 的数据包传输,其消耗的传输时间较少 (q X(Z,Y)) 。从 X 到 Y 的数据包传输的最小预计送达时间为 minz q Y t−1(Z,z)。
在(1)中,表示在特定学习速率下,缓冲存储达到某一信息状态所需的时间;例如,0和1分别代表旧数据和最新数据。这是带缓冲路由器中常用路由过程的基础。ALO拓扑采用无缓冲传输,因此无需考虑交付时间。本工作使用表达式 (2)的改进版本来更新路由表1。
(1) q X t(Z, Y)=(1−)q X t−1(Z, Y)+(+ min z q Y t−1(Z, z))
(2) q X t (Z, Y)= 1+ min z q Y t−1 (Z, z)
ALO拓扑的无缓冲路由以一个包含 m1× m2 项的路由表为例,该路由表初始时是固定的。m1&m2 分别表示网络中的可用路由器以及每个路由器的相邻交换机。基于ALO的无缓冲路由不使用缓冲区进行存储;因此,变为零,学习周期()也趋于1。路由过程采用经过路由器数量较少的距离进行数据传输。当所有方向的跳数相同时,选择流量较小的路径,并且无需为无故障链路更新路由表。更新表1的步骤如下所述:
Step 1 通过查找目的地地址进行基于优先级的路由决策,并检查数据是否已到达目的地。
Step 2 如果数据未到达目的地,路由器选择跳数最小且流量较少的其他路径。
Step 3 路由器向目的地及其邻居提供最小距离信息以更新路由表。
对于路径 ∈{东, 西, 北, 南},如果特定路径是故障的,则对于 i = 1 到 N 且 i ≠ 路由器地址 表_ 条目(i)(路径) ← ∞
对于j ∈{东、西、北、南},如果邻居故障(j)=1,则对于n ∈{沿j通过邻居(路径的每个路由器)}表_项(N)(路径)=表_项(N)(路径)+2
对于i= 1到 N& (i ≠路由器地址 & 邻居地址(路径)则 表_条目(i)(路径)← ∞
表1 无缓冲区ALO拓扑的 路由表
| 到路由器的跳数 | 路由器 | East | West | 北 | 南 |
|---|---|---|---|---|---|
| 路由器 1 | 4 | 2 | 2 | 4 | |
| 路由器 2 | 3 | 3 | 1 | 3 | |
| 路由器 3 | 2 | 4 | 2 | 4 | |
| 路由器 4 | 3 | 1 | 3 | 3 | |
| 路由器 5 | 0 | 0 | 0 | 0 | |
| 路由器 6 | 1 | 3 | 3 | 3 | |
| 路由器 7 | 4 | 2 | 4 | 2 | |
| 路由器 8 | 3 | 3 | 3 | 3 | |
| 路由器 9 | 2 | 4 | 4 | 4 |
无死锁分组传输是无缓冲路由的优势之一,因为无需分组存储。路由表和分组优先级是数据传输过程中决策的主要因素。路由表收敛和分组优先级可限制分组错路和实现无死锁传输。ALO优化的无缓冲路由的伪代码描述如下
最初,输入分组根据其优先级在网络中进行传输。无缓冲拓扑的路由过程通过蚁狮优化算法进行优化,其中蚂蚁和蚁狮分别被视为分组和路由器路径。北、西、东和南是考虑路由器及其状态(跳数和流量水平),这些参数最初被测量。基于路径估计,将首先通过该路径发送第一个分组。此时,其余分组通过更新每个分组的路由表,经由路由器的其他路径发送,如步骤1、2和3所述。因此,基于 ALO的无缓冲路由的分组路由得到优化,并且比现有方法提供更好的性能。
预期研究的性能评估在下一节中进行了充分讨论和比较。
4 结果与讨论
基于ALO的无缓冲路由设计在结构级寄存器传输级(RTL)上使用Verilog实现,并借助Xilinx ISE设计套件14.5进行综合与仿真。该无缓冲路由器设计在 Virtex7XC7VX330T上完成。
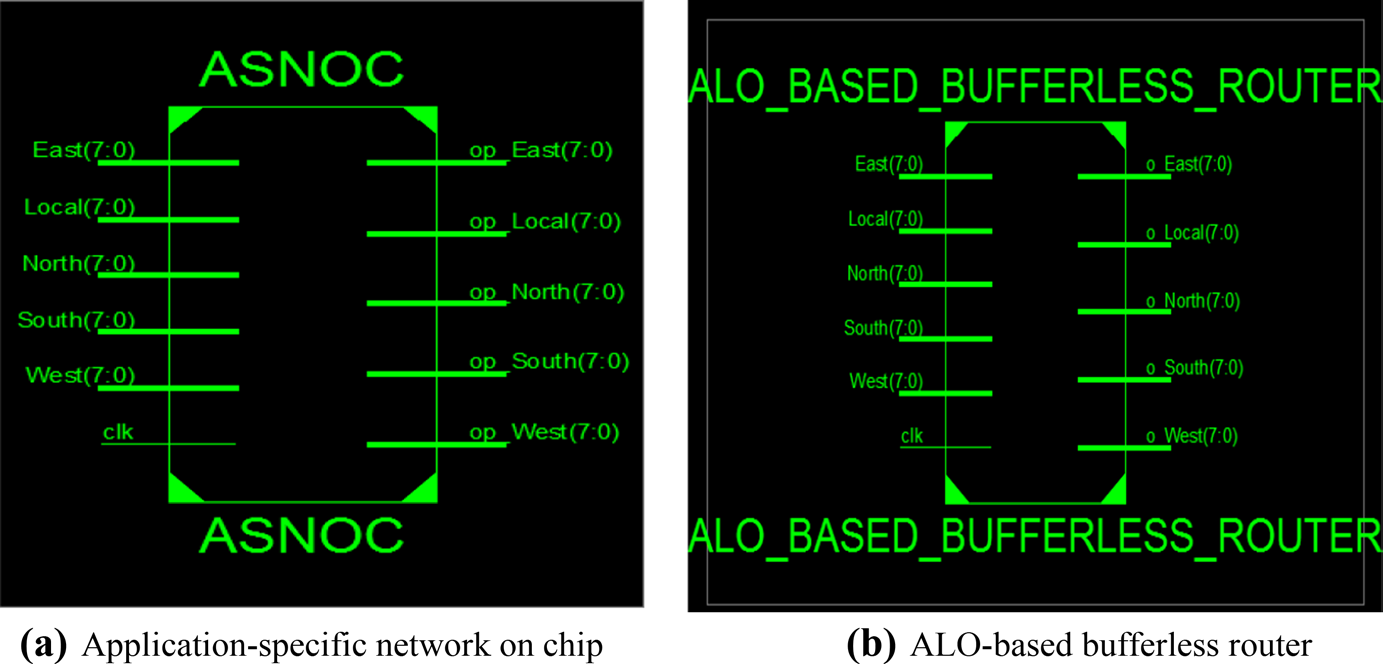
专用片上网络和基于ALO的无缓冲区路由器的RTL视图如图3a, b所示。为ALO‐无缓冲区网络提供了八位输入信息,因此在RTL结构的输入和输出端口中分别表示为[7,0]。

基于蚁狮优化的无缓冲路由器设计及其原理结构如图 4 所示。四个输入端口(北、东、西和南)直接连接到一个交叉开关。最初,分组根据其优先级进行排序,路径选择依赖于路由表。路由表通过蚁狮优化算法不断更新。如果有多个分组请求同一条路径,则通过检查它们的跳数和流量水平将其路由到其他可用端口。ASNoC 和路由器设计的仿真结果分别显示在图 5 和 6 中。
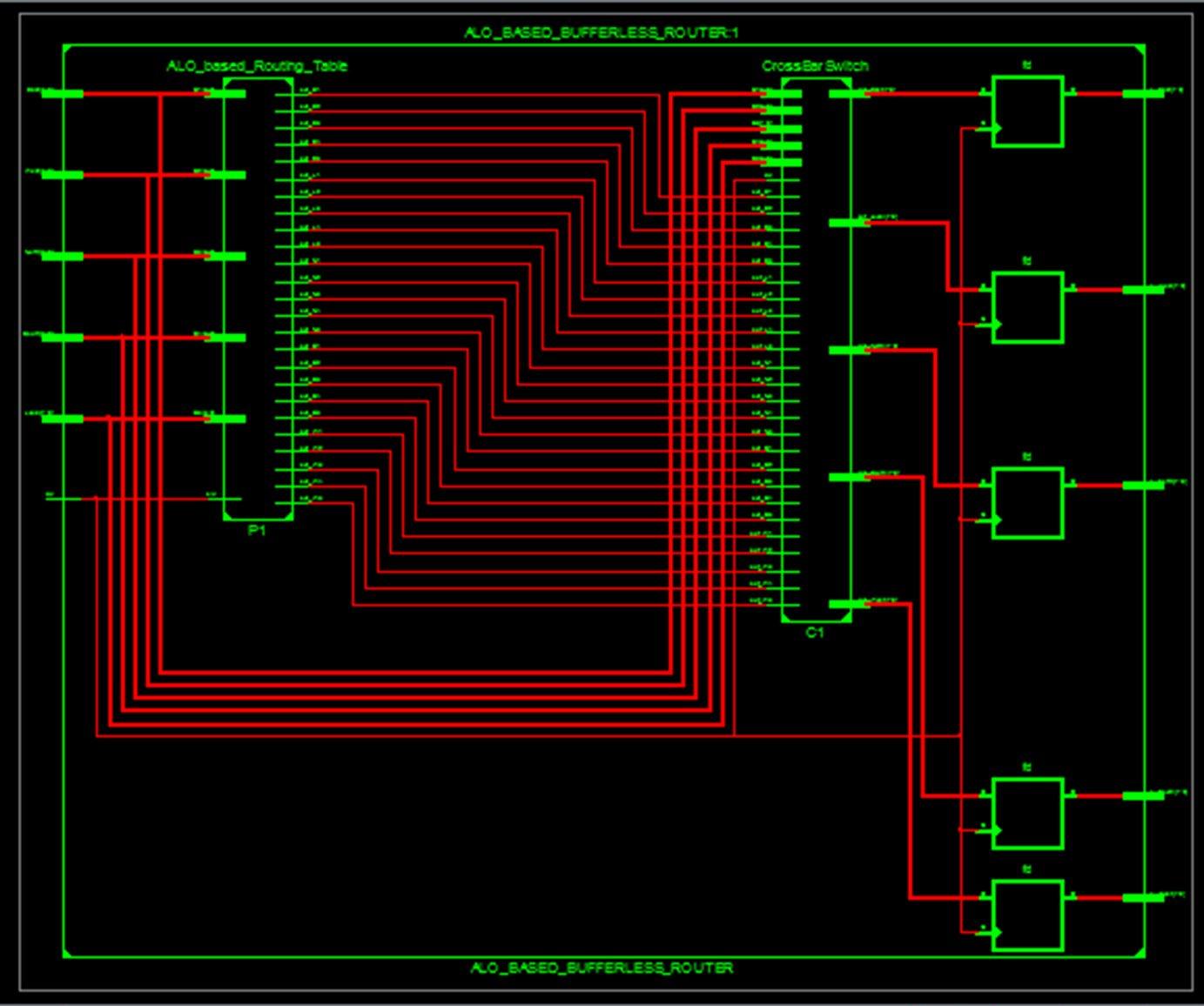
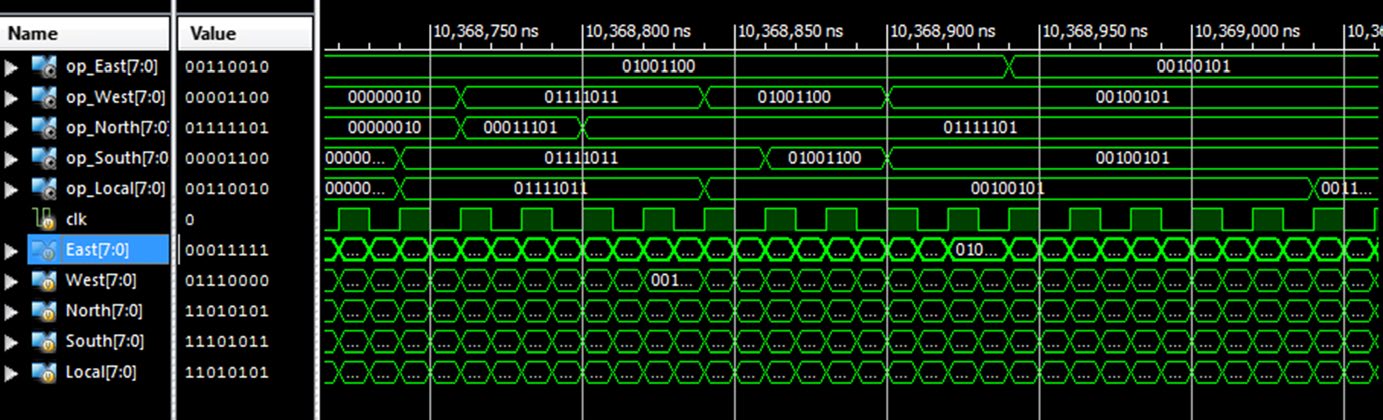
表 2 基于ALO的无缓冲路由器与现有技术的比较
| 资源 | Karthikeyan et al.[13] | Babu et al.[14] | ALO-based buffered routing | ALO-based bufferless routing |
|---|---|---|---|---|
| 目标设备 | Spartan 3E | Spartan6 SP605 | Virtex4 XC4VLX80 | Virtex7 XC7VX330T |
| 触发器 | 1017 | 2457 | 86 | 85 |
| 查找表(LUTs) | 2777 | 5257 | 185 | 115 |
| 切片 | 1644 | 6062 | 141 | 49 |
| 输入/输出块(IOB’s) | 92 | 288 | 83 | 81 |
| 工作频率(MHz) | 103.602 | 102.7 | 426.995 | 780.153 |
| 功耗(mW) | 0.539 | 0.5 | 0.752 | 0.143 |
基于ALO的无缓冲路由与一种随机极化的偏转路由进行了比较[22],基于空间分复用(SDM)的路由器设计[4]以及基于ALO的有缓冲路由,如图7所示。组件利用率(触发器、输入输出块、查找表和切片)用于计算面积利用率,在上图中清晰显示。
我们的研究与参考文献[22]和[4]中的另一项研究进行了比较,结果显示工作频率分别在103.602兆赫兹、102.7兆赫兹、426.995兆赫和780.153兆赫范围内,ALO缓冲和基于ALO的无缓冲路由方法的功耗分别为0.539毫瓦、0.5毫瓦、0.752毫瓦和0.143毫瓦,如图9所示。
网络的4 × 4面积占用与其他路由算法进行了比较,如图10所示。面积利用率分别为FTDR约50,010 μm²,FTRD‐H约50,005 μm²,ALO无缓冲工作约48,000 μm²。
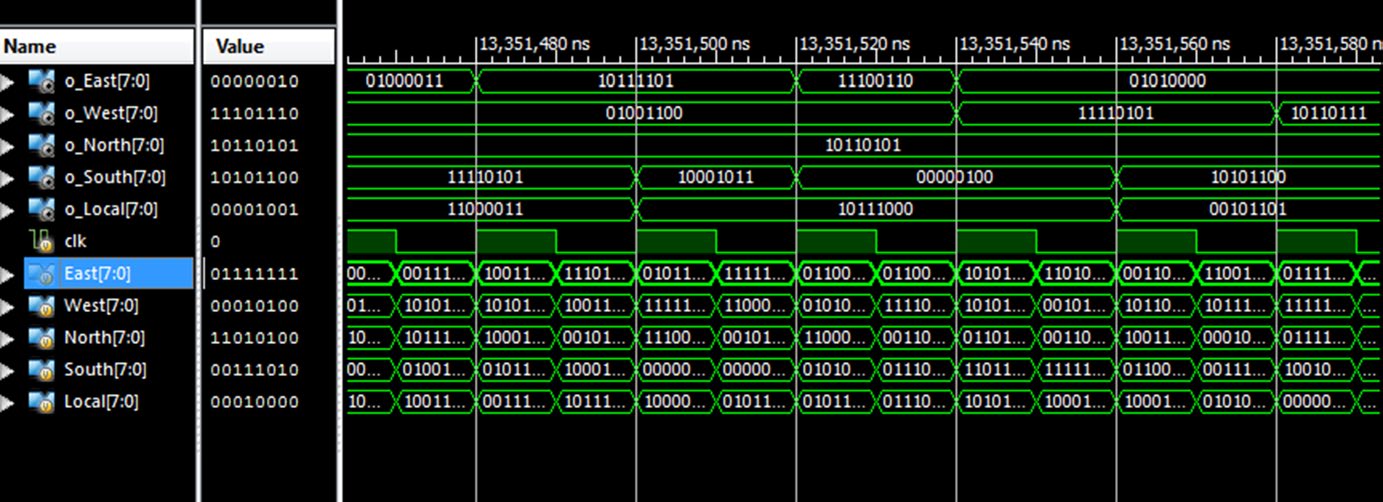
图 11 显示了链路故障从0到30%时网络的吞吐量。这些结果由三种路由算法实现。在无故障情况下,由于避免了不必要的偏转,吞吐量略高于拥塞网络。在存在链路故障的情况下,FTDR实现较低的吞吐量,而FTDR‐H则实现较高的吞吐量。然而,基于ALO的无缓冲路由方案在故障率基础上的吞吐量性能优于现有技术。
平均跳数表示每个分组到达目的地的距离。图12展示了基于故障率的跳数变化的图形表示。故障链路的数量是衡量故障率的指标,在本研究中该指标逐渐被忽略。同样,由于故障率较低,每链路的数据传输量较高。从上图可以看出,与现有方法相比,基于ALO的无缓冲路由方法由于优化过程,在到达目的地时考虑了更少的跳数。
详细的功耗分析有助于设计人员通过不同技术优化功耗。图13展示了四种不同拓扑结构在16到1024个IP核范围内的整体功耗行为[6]。SPIN架构消耗最大功耗高达85.2 W。在交换机中,CLICHÉ架构的功耗仅次于八边形架构。而整体上,基于ALO的无缓冲路由方法的功耗低于其他任何拓扑结构,如图13所示。
5 结论
本文描述了一种在无缓冲路由器中基于蚁狮优化的路由算法。通过蚁狮算法优化路由表更新过程,以降低功耗水平和面积利用率。通常情况下,存在逐步减少的在从路由器中移除缓冲区的同时,该方法以功耗和面积为代价显著提高了运行速度。然而,ALO‐无缓冲架构相较于现有的无缓冲技术提供了更好的性能。
通过ALO‐无缓冲设计的Verilog实现,对蚁狮优化在有缓冲路由和无缓冲路由中的应用进行了比较,如表2所示。规划方法的面积利用率为48,000 μm²,而FTDR和FTRD‐H分别为50,010 μm²和50,005 μm²;此外,本研究实现了780.153兆赫的工作频率,功耗为0.413毫瓦。此外,ASNoC设计中基于 ALO的偏转路由在不久的将来可扩展应用于某些应用。

















 626
626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









