





与
是针对一个训练样本来说的,有圆括号的上标可以区分是哪个样本,方便引用说明,比如你的第i个训练样本
对应的预测值是
loss(error) function 损失函数:
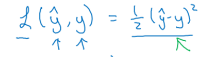
损失函数通常不定义为这个形式,因为当你学习这些参数的时候,你会发现之后讨论的优化问题,会变成非凸的,最后会得到很多个局部最优解,梯度下降法可能找不到全局最优值【课程后面会讲】
用这个损失函数:

含义解释
y只可能为0或1

如果y等于1,函数变为如上形式
为了让损失函数足够小,那么就要尽可能大,但是
在0-1之间,所以
要接近于1,也就接近
![]()
如果y等于0
-log(1-)尽可能小,(1-
)尽可能大,
尽可能接近0
loss function定义在单个训练样本中,衡量在单个训练样本的表现
cost function 衡量全体样本上的表现
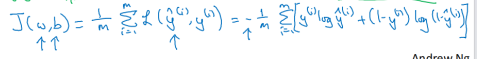
根据之前得到的参数w和b,对损失函数求和取平均

















 37万+
37万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









