






《人工智能AI之计算机视觉:从像素到智能》专栏 · 模块一:视觉之门——从经典特征到CNN革命 · 第 3 篇
在上一篇,我们拆解了数字图像的本质——它充满了采样、量化和压缩带来的“妥协”。我们知道,AI拿到手的,往往是一份“残缺的”情报。
那么,在2012年深度学习(CNN)大爆发之前,在那个没有海量数据、没有强悍GPU的年代,早期的计算机科学家们是如何让机器从这些“残缺的情报”中,识别出目标、看懂世界的?
那是一个属于“工匠”的时代,我愿称之为计算机视觉的“古典主义时期”。
作为一名在IT行业摸爬滚打了30多年的老兵,我经历过那个时代。那时,我们没有“端到端”的大模型,遇到一个识别难题(比如银行票据上的印章比对),不能指望“喂数据”就自动解决。我们必须像最耐心的钟表匠一样,拿着放大镜,去图像的像素海洋里,一点一点地“手动”打磨、设计出能让机器理解的“特征”。
今天,我想带你回到那个“蛮荒”但充满智慧的时代,去看看两座至今仍让人仰望的丰碑——SIFT 和 HOG。
理解它们,你才能真正听懂深度学习时代的“轰鸣声”究竟意味着什么。
一、 机器视觉的“史前难题”:如何从混乱中找到“不变”?
想象一下,你是个刚到地球的外星人(就像早期的计算机),你试图记住“什么是可乐瓶”。
你拍了一张标准照。但第二天,你发现世界变了:
- 可乐瓶离你远了(尺度变化,Scale)。
- 它倒在了桌上(旋转变化,Rotation)。
- 屋里没开灯,它看起来黑乎乎的(光照变化,Illumination)。
在计算机看来,这三个变化,导致摄像头采集到的像素矩阵完全不同。如果仅仅依靠像素匹配,它会认为这是三个完全不同的东西。
这就是“古典时期”最大的挑战:如何设计一种“特征”,它能无视距离、角度、光线的干扰,永远稳定地指向同一个物体?
这被称为“不变性” (Invariance)——它是计算机视觉皇冠上的明珠。

同一物体的“千变万化”
二、 SIFT:给世界打上“永不磨灭”的锚点
1999年,加拿大科学家 David Lowe 带来了一项划时代的发明——SIFT (尺度不变特征变换, Scale-Invariant Feature Transform)。
如果把一张图像比作茫茫大海,SIFT就是在大海中打下了几百颗“永不移动”的锚点。无论海浪(噪点)怎么翻滚,船只(相机)怎么晃动,这些锚点都稳如泰山。
2.1 SIFT是如何做到的?(通俗版解密)
SIFT极其复杂,但其核心思想充满了哲学意味:要想看清世界,你得先学会“眯着眼”看。
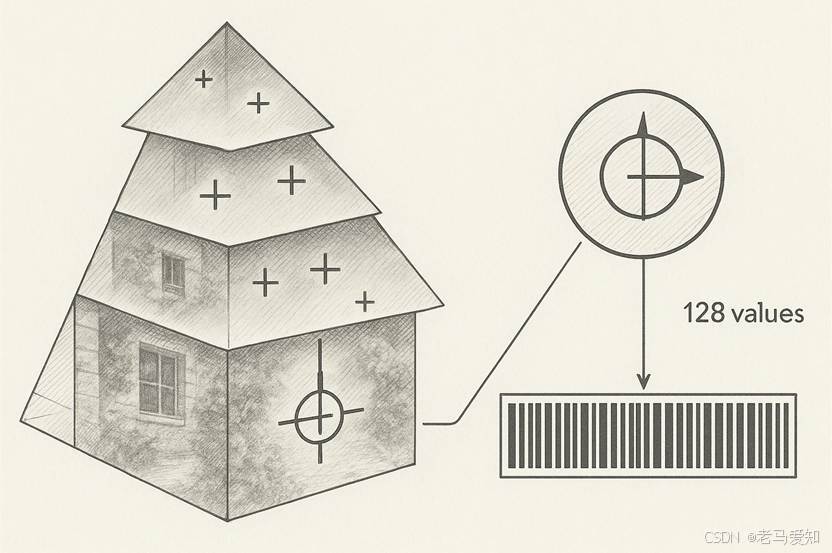
- 第一步:模拟“远近”——高斯金字塔 (Gaussian Pyramid)
- 机器怎么知道一个物体“变小”了?Lowe的想法是:如果我们把一张清晰的大图不断地模糊(高斯模糊),是不是就模拟了它“离我们越来越远”的效果?
- SIFT构建了一座“金字塔”,底部是最清晰的原图,越往上越模糊、越小。
- 然后,它在这些不同模糊程度的图之间“找茬”,寻找那些在所有层级里都显得“与众不同”的点(极值点)。这些点,就是最“抗造”、最稳定的“关键点” (Keypoints)。
- (熟悉元素):这就好比你在人群中找朋友,你不仅要能在面对面时认出他,还要能在他走到100米外(变得模糊渺小)时依然认出他。能做到这一点的特征(比如他独特的走路姿势),才是“真特征”。
- 第二步:确定“方向”——主方向分配
- 找到点后,怎么应对“旋转”呢?
- SIFT会在这个点周围看一圈,看看像素值往哪个方向变化最大(梯度)。它就像给每个关键点装了一个“指南针”,无论照片怎么转,这个“指南针”始终指向物体本身固有的某个方向(比如杯子的把手方向)。
- 第三步:生成“身份证”——描述子 (Descriptor)
- 最后,它把这个点周围区域的信息,编码成了一个由128个数字组成的向量。这就是这个关键点的“数字身份证”。
- 凭着这张身份证,无论这只猫是倒立还是侧躺,只要找到这个点,我们就能认出:“嘿,这是那只猫的左耳尖!”
2.2 SIFT的伟大与局限
SIFT是极其伟大的。在那个年代,它是第一个真正好用的、工业级的通用视觉算法。
- 伟大之处:它几乎凭借一己之力,解决了全景拼接(手机全景模式的老祖宗)、早期的图像搜索、甚至火星车视觉导航的核心难题。
- 局限:2010年左右,我们在一个移动端安防项目上试图用SIFT做实时物体跟踪。结果惨败。为什么?太慢了! 在当年的嵌入式芯片上,计算一张图的SIFT特征可能需要几秒钟。它太精密,精密到难以实时。
SIFT的“高斯金字塔”与特征点
三、 HOG:抓住物体“灵魂”的轮廓
如果说SIFT是精密的瑞士军刀,适合找具体的“点”;那么2005年诞生的HOG (方向梯度直方图, Histogram of Oriented Gradients),就是一把厚重的大刀,专门用来“砍”出物体的大致轮廓。
它的诞生只为了解决一个当时极其棘手的问题:如何在街头的监控画面中,把“人”给框出来?
人是很难识别的:穿的衣服五颜六色(颜色不可靠),高矮胖瘦各不相同(尺度不可靠),还会摆各种姿势(形状不可靠)。
3.1 HOG的洞察:不看细节,看“趋势”
HOG的发明者意识到:不管人穿什么衣服,有一个东西是不太变的,那就是边缘和轮廓的“走势”。
- 头顶的轮廓通常是圆弧形的。
- 肩膀的轮廓通常是“八”字形的。
- 腿部的轮廓通常是两条平行的竖线。
HOG放弃了去寻找一个个精准的“关键点”,而是把整张图切成密密麻麻的小方块(Cell)。在每个小方块里,它都在统计:“这里面的线条,大部分是往哪个方向走的?”
- 意外创新(认知):它不关心“像素值”是多少(是黑还是白),它只关心“像素变化的方向”(梯度)。
- 最后,它把这些小方块里的“方向统计结果”拼起来,就形成了一幅“由趋势组成的抽象画”。在这幅画里,人的样子非常独特,一眼就能被分类器(当时常用SVM)认出来。
3.2 HOG的工业传奇
HOG是工业界的老朋友了。在深度学习普及之前,绝大多数高级轿车的“行人碰撞预警系统”(ADAS),核心技术栈往往就是HOG + SVM。它计算量适中,对人的轮廓捕捉极其鲁棒。即使在今天,一些低功耗的边缘摄像头芯片里,可能还硬化了HOG算子。
思考小札
回头看,HOG其实非常“聪明”。它放弃了对细节的纠缠,抓住了“梯度方向”这个更本质的“结构信息”。
这给了我们一个极其重要的启示:有时候,“模糊”一点(统计信息),反而比“精确”一点(像素值)更接近事物的本质。 这一点,后来的深度学习可谓将其发扬光大。

人眼看到的行人 vs. HOG看到的行人
四、 “古典时代”的落幕与遗产
SIFT和HOG,代表了那个“手工特征”时代的巅峰。
那时的算法工程师,更像是“视觉人类学家”。他们观察世界,然后用数学公式去试图“描述”他们观察到的规律(边缘、角点、纹理趋势)。
但是,人类手工设计的特征,终究有极限。我们能想到的特征可能只有几十种、几百种。而真实世界的复杂性是无穷的。
2012年,AlexNet一声炮响,深度学习时代来了。
很多人说,CNN“淘汰”了SIFT和HOG。但我更愿意说,这是“传承与升华”。
- 传承:你以为CNN完全是新东西吗?如果你去看看CNN模型的第一层卷积核“学”到了什么,你会惊讶地发现:它们学出来的东西,长得和HOG里的边缘检测器、Gabor滤波器几乎一模一样!
- 升华:CNN不再需要人类“告诉”它该看边缘还是看角点。它自己从海量数据中,“痛悟”出了看世界的方式。它学到的特征成千上万,远超人类手工设计的想象力。
五、 结语:致敬那些“手动”点亮火把的人
在进入下一篇激动人心的CNN革命之前,请允许我向SIFT、HOG以及背后的David Lowe、Navneet Dalal等先驱致敬。
在算力贫瘠的荒原上,他们用深邃的数学洞察,第一次让冰冷的机器拥有了某种程度的“视觉恒常性”。他们证明了:机器不必像人眼那样去“感光”,它可以通过精巧的数学变换,去“感知结构”。
这也是我们每个人在学习新知时应有的态度:不要只盯着最新的大模型热点,去看看它“小时候”的样子。理解了它从哪里来,你才能更深刻地知道它将要去向何方。
下一篇,我们将正式推开新时代的大门。看看2012年那场“创世爆炸”——《CNN如何开启深度视觉革命?》。看看那个模仿人类大脑视觉皮层设计的精妙结构,是如何把我们今天讲的这些“手工经验”,全部自动化、规模化的。

视觉特征的进化之路



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











