




 文章介绍了基于非anchor机制的检测网络ExtremeNet,它将目标检测问题转换为关键点检测,去掉分类回归或隐式特征学习。该网络使用标准关键点预估网络预测极值点与中心点,通过几何关联性组成检测框。文中还阐述了方法设计,包括极值点表示、损失函数等,最后给出实验结果。
文章介绍了基于非anchor机制的检测网络ExtremeNet,它将目标检测问题转换为关键点检测,去掉分类回归或隐式特征学习。该网络使用标准关键点预估网络预测极值点与中心点,通过几何关联性组成检测框。文中还阐述了方法设计,包括极值点表示、损失函数等,最后给出实验结果。
代码地址:ExtremeNet
1. 概述
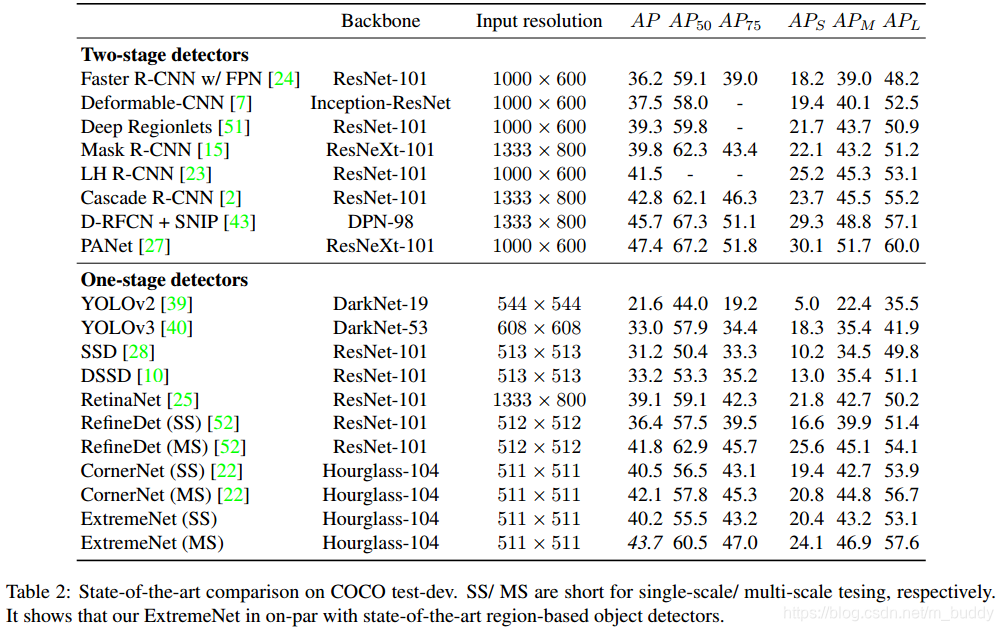
导读:现有的一些检测算法使用近乎枚举的方式列出目标的位置,并判别其中的每一个是否为目标。这篇文章中提出了一个新的基于非anchor机制的检测网络ExtremeNet,这个网络使用一个标准的关键点预估网络预测4个极值点(左右边界极值点以及上下边界极值点)与一个目标中心点。要是这5个点符合几何关联性那么这几个点就组成一个检测框。因而目标检测问题就转换为了关键点检测,从而去掉了分类回归或是隐式特征学习。文章提出的网络结构达到了与目前最佳检测网络比肩的性能表现,在COCO test-dev上达到了 43.7% AP,速度3.1FPS。此外直接通过检测出的极值点扩展得到8边形(极值点扩展 1 8 \frac{1}{8} 81得到)分割掩膜在COCO上达到了18.9%的AP,进而基于极值点的分割可以将分割性能进一步提升到34.6%。
下图是文章算法的检测结果示例:

这篇文章提出一个bottom-up的目标检测框架ExtremeNet,提取目标的左右上下极值点与一个中心点。使用state-of-art的特征点检测架构去提取极值点,对于每个分类的类别生成5个heatmap(四个极值点和一个中心点)。使用纯几何方法组合同一目标的极值点:四个极值点的几何中心与预测的中心点heatmap匹配且高于阈值(暴力枚举,时间复杂度
O
(
n
4
)
O(n^4)
O(n4),不过n一般非常小,在COCO中
n
≤
40
n\le 40
n≤40,而且是在GPU上实现)。图2展示了文章算法的大致流程。
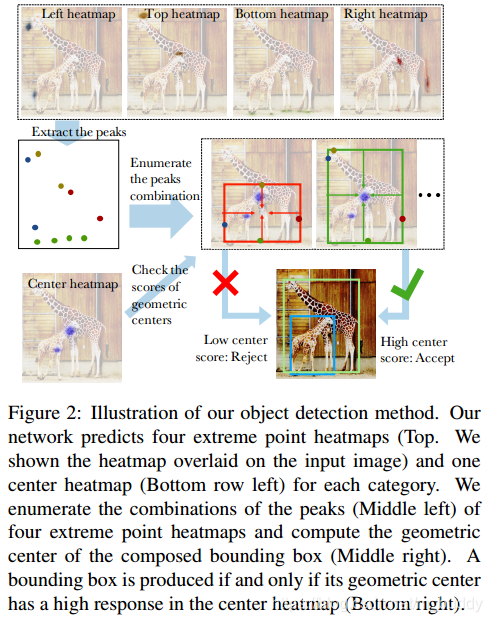
图2 展示了算法的大致流程。首先产生四个预测极值点的heatmap(图2顶部)和一个预测中心点的heatmap(图2左下),提取极值点heatmap的峰值(图2中左),暴力枚举所有组合,计算几何中心(图2中右),如果几何中心与中心heatmap高度匹配,则接受该组合,否则拒绝(图2右下)。
在这篇论文之前有人提出了CornerNet的目标检测算法,该算法使用一对角点来进行目标定位。这篇文章的算法在关键点定义与组合上有所不同。在CornerNet中角点经常是在目标的外部,并没有很强的表面特征。而文章中提出的极值点是在目标上的,是视觉可分并且具有局部视觉特征。文章提出的方法完全是基于图片表面信息的,并没有任何隐式特征学习,且经过实验证明基于表面特征的检测工作更佳。
该算法与CornerNet的区别在于关键点定义和组合:
- 1)CornerNet采用左上和右下角点,角点往往不在目标上,没有较强的外观特征;而ExtremeNet采用极值点,极值点在目标上,容易区分且具有一致的局部外观特征;
- 2)CornerNet点对组合是根据embedding vector的距离,而ExtremeNet则是根据几何中心点。ExtremeNet完全基于外观,没有任何的隐特征学习;
2. 方法设计
2.1 基础部分
极值点的表示
在传统的检测标注中使用
(
x
(
t
l
)
,
y
(
t
l
)
,
x
(
b
r
)
,
y
(
b
r
)
)
)
(x^{(tl)},y^{(tl)},x^{(br)},y^{(br)}))
(x(tl),y(tl),x(br),y(br))),分别表示目标框的左上角和右下角的点。而在这篇文章中使用的是不同的标注方式,使用
(
(
x
(
t
)
,
y
(
t
)
)
,
(
x
(
l
)
,
y
(
l
)
)
,
(
x
(
b
)
,
y
(
b
)
)
,
(
x
(
r
)
,
y
(
r
)
)
)
((x^{(t)},y^{(t)}), (x^{(l)},y^{(l)}), (x^{(b)},y^{(b)}), (x^{(r)},y^{(r)}))
((x(t),y(t)),(x(l),y(l)),(x(b),y(b)),(x(r),y(r)))来表示目标在上下左右边界上的极值,因而一个检测框就可以使用4个值:
(
x
(
l
)
,
y
(
t
)
,
x
(
r
)
,
y
(
b
)
)
(x^{(l)}, y^{(t)}, x^{(r)}, y^{(b)})
(x(l),y(t),x(r),y(b))来确定了,对于中心点其定义为:
(
x
(
l
)
+
x
(
r
)
2
,
y
(
t
)
+
y
(
b
)
2
)
(\frac{x^{(l)}+x^{(r)}}{2}, \frac{y^{(t)}+y^{(b)}}{2})
(2x(l)+x(r),2y(t)+y(b))。
损失函数
这篇文章中借鉴了CornerNet中关键点定位的损失函数,它是使用修改的focal loss来平衡定位的正负样本比例,其形式如下:
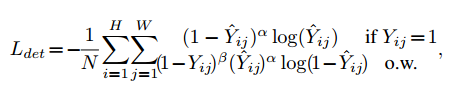
其中,
α
,
β
\alpha,\beta
α,β是超参数,实验中将其固定为
α
=
2
,
β
=
4
\alpha=2,\beta=4
α=2,β=4。
N
N
N是图像中目标的个数。
由于网络在下采样过程中会引入偏移
Δ
(
a
)
\Delta^{(a)}
Δ(a),文章也是借鉴CornerNet引入了对位置的修正,这里使用的回归损失函数是:
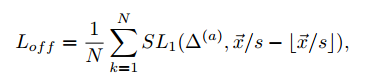
其中,
s
s
s是下采样的系数(对于Hourglass其值为4),
x
⃗
\vec{x}
x也就是关键点的坐标了。
2.2 网络结构
文章提出的ExtremeNet的大致网络结构见图3所示:

输入的图像经过Hourglass之后会生成
5
∗
C
+
4
∗
2
5*C+4*2
5∗C+4∗2的特征图(
C
C
C为分类的数量),前面的一部分代表4个极值点和一个中心点,后面的部分就是代表每个极值点的偏移系数了。
2.3 Center Grouping
特征点检测网络输出关键点包含了中心点的heatmap:
Y
^
∈
(
0
,
1
)
H
∗
W
\hat{Y}\in (0,1)^{H*W}
Y^∈(0,1)H∗W,4个极值点heatmap:
Y
^
(
t
)
,
Y
^
(
l
)
,
Y
^
(
b
)
,
Y
^
(
r
)
\hat{Y}^{(t)}, \hat{Y}^{(l)}, \hat{Y}^{(b)}, \hat{Y}^{(r)}
Y^(t),Y^(l),Y^(b),Y^(r),这这些特征图中使用一个
3
∗
3
3*3
3∗3的滑窗去寻找极值点(窗口中取最大值),并且该极值需要大于
τ
p
=
0.1
\tau_p=0.1
τp=0.1。对于中心点其对应位置处的值应该是大于
τ
c
=
0.1
\tau_c=0.1
τc=0.1的,满足了这些条件才能算得上的一个合适的检测框。对于检测框的阈值是通过对确定检测框的5个要素取均值计算实现的。其具体的计算过程见下面的算法所示:

2.4 Ghost box suppression
使用Center grouping会产生一些假阳性的检测结果(文章中将其称之为gost boxes,文章对其定义为包含众多小检测框的检测框),文章对此给出了一些去除的后处理过程,既是通过Soft NMS对这些检测结果进行抑制,要是被包含框的置信度和大于了所在大框的3倍,那么就会将大框的置信度除以2。
2.5 Edge aggregation
此外,极值点并非总是唯一的,比如一个汽车的极值点可能是水平或竖直的线段,文中极值点的响应是对边缘多个点的弱响应而不是一个点的强响应。这有可能产生几个问题:弱响应可能会被忽略;目标如果发生轻微旋转即便检测到关键点,得分也有很大差异。
作者采用边缘聚集的方法来解决:对于每个极值点(局部最大值点),分别沿水平和垂直两个方向进行聚集,也就是在每个方向上找极值点最近的左右两个局部最小值,在区间内做加权和作为极值点的得分。公式如下所示:
Y
m
^
=
Y
^
m
+
λ
a
g
g
r
∑
i
=
i
0
i
1
N
i
(
m
)
\widehat{Y_m}=\hat{Y}_m+\lambda_{aggr}\sum_{i=i_0}^{i_1}N_i^{(m)}
Ym
=Y^m+λaggri=i0∑i1Ni(m)
其中,m为极值点位置,
i
0
,
i
1
i_0,i_1
i0,i1分别为距离m最近的两个局部最小值。如下图所示,使用边缘聚集策略后,边缘中心的像素点的置信度明显提升:

3. 实验结果

















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









