






 YOLACT++是YOLACT的改进版,提高了实例分割性能,但牺牲了一些速度。主要改进包括:1) 引入Deformable Convolution增强网络表达;2) 设计Fast Mask Re-Scoring Network评估mask质量;3) 优化预测头以调整anchor设置。在COCO数据集上,YOLACT++达到34.1mAP,帧率为33.5 FPS。
YOLACT++是YOLACT的改进版,提高了实例分割性能,但牺牲了一些速度。主要改进包括:1) 引入Deformable Convolution增强网络表达;2) 设计Fast Mask Re-Scoring Network评估mask质量;3) 优化预测头以调整anchor设置。在COCO数据集上,YOLACT++达到34.1mAP,帧率为33.5 FPS。
代码地址:yolact
1. 概述
导读:这篇文章的方法YOLACT++是在YOLACT的基础上进行改进得到的(之前关于YOLACT的文章可以参考之前的博文:链接),这篇文章给出的算法相比之前的版本其在instance分割性能上有了很大进步,作为取舍的另外一方面,在速度上略微有所下降。其具体的改进体现在以下3点:1)为网络引入Deformable Convolution,增强网络表达能力,带来更好的检测器与mask prototypes;2)针对目标设置更好的anchor尺寸和长宽比例;3)在网络中引入了快速mask re-scoring分支,这里的方法借鉴Mask Scoring RCNN,为mask引入质量评价;最后,其在COCO数据集上实例分割性能达到34.1mAP,帧率为33.5 FPS。
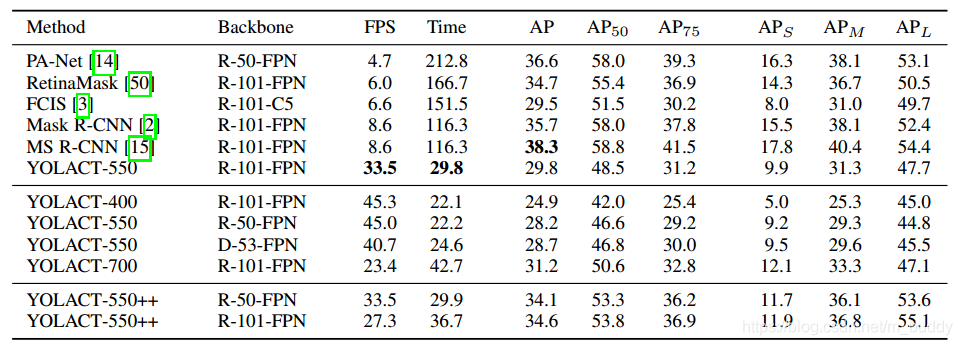
将文章的算法与之前的一些算法进行比较见下图所示:

PS: 这里将不再阐述YOLACT的具体实现,主要阐述与YOLACT++不一样的地方,也就是文章提出的改进的地方。
2. 方法设计
2.1 Fast Mask Re-Scoring Network
这里从Mask Scoring RCNN受到启发,采用更加适合mask性能评估的方式去度量分割mask的质量,而不是采用分类的置信度,文章中使用与GT mask之间计算得到的mask IoU作为mask性能的评估指标,其对应的网络结构(卷积+池化)见下图所示:

上面部分网络分支的输入是剪裁之后(在阈值化之前)的mask预测结果,输出是对于每个类别的mask IoU。最后的mask性能评估是使用分类置信度与mask IoU进行乘积得到的。
对比Mask Scoring RCNN文章在以下方面有所不同:
- 1)对于mask评分的输入不同:这篇文章的方法只使用了整图分割截图剪裁结果作为输入,而在Mask Scoring RCNN中是使用了pooling之后的特征与mask预测结果concat之后作为输入,下面是其对应的网络结构:

这部分的改进主要是基于速度考量; - 2)这里将原有的FC层去掉,直接使用全局池化进行替换从而提升速度;
2.2 Deformable Convolution with Intervals
为了增加网络的表达能力,文章在backbone中引入了DCNv2,具体的就是在ResNet网络的
C
3
C_3
C3到
C
5
C_5
C5上使用Deformable convolution替换原有的卷积。但是DCN的加入必然会导致速度的下降,文章也提到在增加性能1.8的mask mAP的情况下会增加8ms的处理时间,为了在时间与性能上达到合适的平衡,文章对此进行了研究,结果见下表所示:
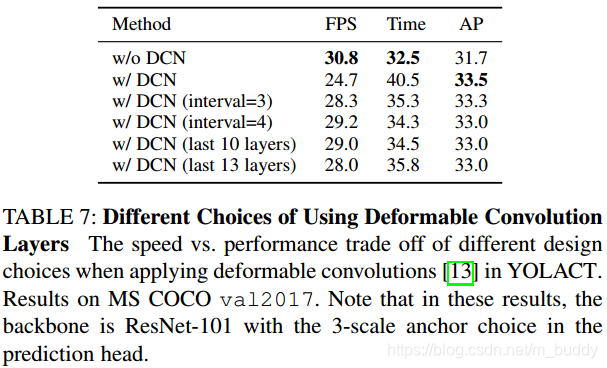
2.3 Optimized Prediction Head
这篇文章的方法基于的是一阶段的anchor机制检测器,所以anchor这类超参数的选择也会对网络的性能带来一定的影响。这里的改动主要有两个策略:
- 1)保持scale增加anchor的ratio,从 [ 1 , 1 2 , 2 ] [1,\frac{1}{2},2] [1,21,2]到 [ 1 , 1 2 , 2 , 1 3 , 3 ] [1,\frac{1}{2},2,\frac{1}{3},3] [1,21,2,31,3],对应anchor的数量会增加 5 3 \frac{5}{3} 35倍;
- 2)保持ratio增加scale,既是变为 [ 1 , 2 1 3 , 2 2 3 ] [1,2^{\frac{1}{3}},2^{\frac{2}{3}}] [1,231,232],对应anchor的数量会增加3倍;
两种策略达到的性能具体见下表所示: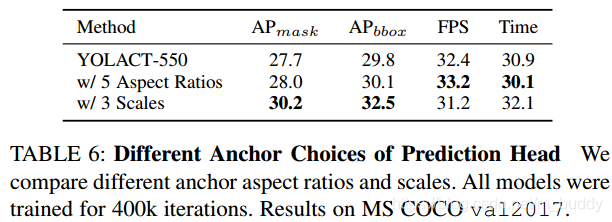
3. 实验结果
性能对比:
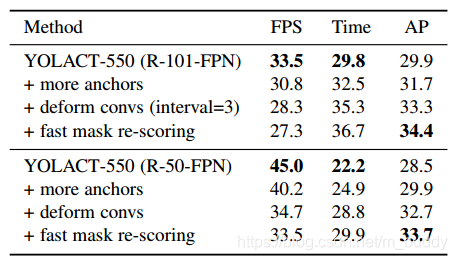
消融实验:

















 2461
2461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









