






 YOLACT是一种实时全卷积实例分割模型,能在MS-COCO数据集上达到29.8 mAP,33FPS的帧率。它通过并行的prototype mask生成和mask系数预测,避免了池化操作,提高了分割质量。文章介绍了网络设计、Fast NMS优化及实验结果,显示YOLACT在速度和分割质量上优于其他方法。
YOLACT是一种实时全卷积实例分割模型,能在MS-COCO数据集上达到29.8 mAP,33FPS的帧率。它通过并行的prototype mask生成和mask系数预测,避免了池化操作,提高了分割质量。文章介绍了网络设计、Fast NMS优化及实验结果,显示YOLACT在速度和分割质量上优于其他方法。
代码地址:YOLACT
1. 概述
导读:本篇文章在一阶段检测网络基础上提出了一个实时全卷积实例分割模型,在MS-COCO数据集上达到了了29.8 mAP,帧率为33FPS。并且该模型是在单GPU上就可以训练得到(设备友好型),这是将总任务划分为两个并行的子任务实现的:(1)生成prototype mask集合;(2)预测每个pre-instance mask系数。之后将mask系数与原始mask线性结合得到实例分割掩膜。文章发现这个过程并不需要重新池化操作(两阶段方法),因而可以生成高质量的掩膜,此外网络对于一些异常情况也能够较好处理。在传统NMS算法的基础上提出了Fast NMS(速度快了12ms),只带来了很小的性能损失。
文章提出的YOLACT方法具有如下的优势:
- 1)速度快,由于采用了并行结构与轻量化的组合方式,使其在一阶段检测网络的基础上只添加了少量计算量,在主干网络为ResNet-101+FPN的情况下达到30FPS;
- 2)分割掩膜质量高,由于没有使用两阶段方法中的pooling操作使得可以获得无损失的特征信息,并且在大目标的分割场景下性能表现更优秀;
- 3)模块通用化,文章提出的prototype生成与mask系数可以添加到现有的检测网络中去;
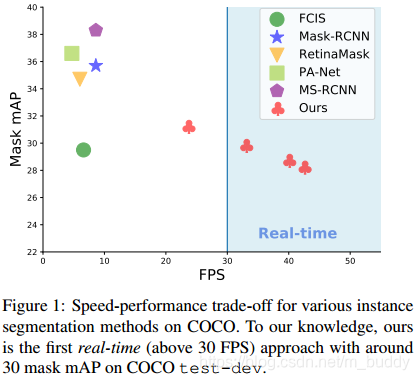
文章提出的方法与现有的实例分割网络性能对比:
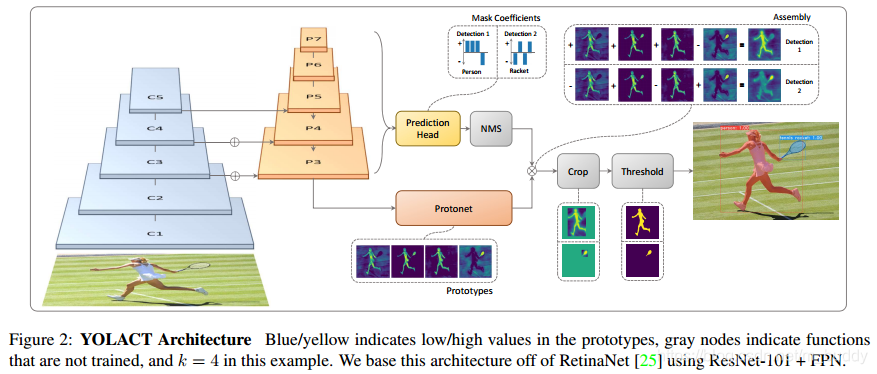
2. 网络设计
这篇文章的方法是在现有的一阶段检测网络的基础上添加一个掩膜分支,就像Mask R-CNN在Faster R-CNN基础上做的一样,区别是没有了特征池化操作。这里将整个任务划分为了两个并行的子任务:
- 1)prototype mask分支,使用FCN的网络结构去生成prototype mask,这个过程中并不会涉及到单个实例(单个实例是在检测结果上corp之后得到的);
- 2)目标检测分支,该分支对每个anchor去预测mask的系数,从而得到图像中实例的位置,之后经过mask分支与prototype mask做线性运算从而结合两个分支的结果;
这篇文章提出的网络结构见下图所示:
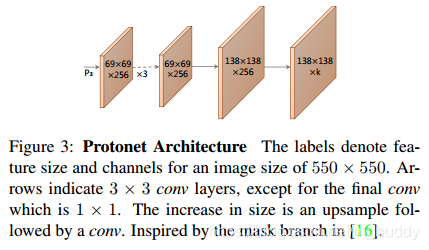
2.1 prototype的生成
在这个分支中会产生
k
k
k个prototype mask,产生的prototype mask的结构可以参考FCN网络(输入来自网络P3,输出的通道数为
k
k
k),如下图3所示,不过在这个分支中并没有计算损失,该分支的损失是来自于最后分支整合之后的最终掩膜损失。
在设计这个分支网络的时候考虑了两点:(1)来自骨干网络更深层次的特征其产生的结果鲁棒性更好;(2)更高的分辨率意味着更好的mask质量与小目标上更好的性能。
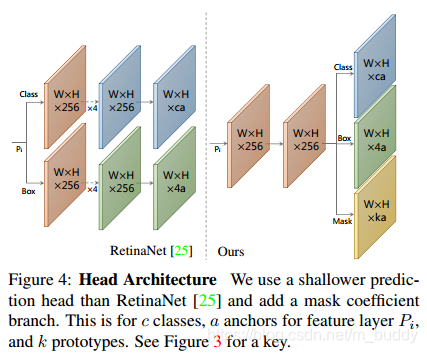
2.2 Mask Coefficients
传统的目标检测拥有两个分支,一个用于预测
c
c
c类分类的置信度,另外一个用于预测边界框的坐标。在此基础上这篇文章还引入了另外一个分支用于预测
k
k
k个mask coefficients,如图2中的正负关系,算是特征增强与排除无关干扰,这与prototype mask中是一一对应的。因而这里对于每个anchor生成的是
4
+
c
+
k
4+c+k
4+c+k的coefficients。对于检测部分定位损失是使用的L1损失函数,并且加入了OHEM保持正负样本的比例为1:3。
对于非线性,文章发现在最后的mask中构建区prototype是很重要的。因而使用tanh函数对
k
k
k个coefficients进行变换,从而无非线性的情况下表现更鲁棒。其结构见图4
2.3 Mask Assembly
这里是将生成的prototype mask与mask coefficient进行线性操作,之后使用sigmoid激活函数。
M
=
σ
(
P
C
T
)
M=\sigma (PC^T)
M=σ(PCT)
Losses:
这里采用的损失函数由三部分组成:分类的损失函数
L
c
l
s
L_{cls}
Lcls,定位的损失函数
L
b
o
x
L_{box}
Lbox,分割的损失函数
L
m
a
s
k
L_{mask}
Lmask。
cropping masks:
在inference阶段使用生成的预测框剪裁了最后的mask。在训练阶段则是使用GT框去剪裁,并且将计算出来的
L
m
a
s
k
L_{mask}
Lmask除以GT框的面积。
2.4 Emergent Behavior
YOLACT取得的效果可能有点出人意料,因为围绕实例分割任务的一个共识是:因为FCNs是平移不变的,所以需要在模型中添加 转移方差。因此,在Mask R-CNN和FCIS中,通过显式方法添加了转移方差:方向图、位置存档,或是把mask预测分支放在第二个stage,都使得它们不需要再处理定位问题。
在YOLACT,唯一算是添加转移方差的地方是使用预测框裁剪feature map时。但其实这只是为了改善对小目标的分割效果,作者发现对大中型目标,不裁剪效果就很好了。所以,YOLACT似乎通过其原型的不同激活学习到了如何定位目标。
怎么理解YOLACT隐式学习到了转移方差?
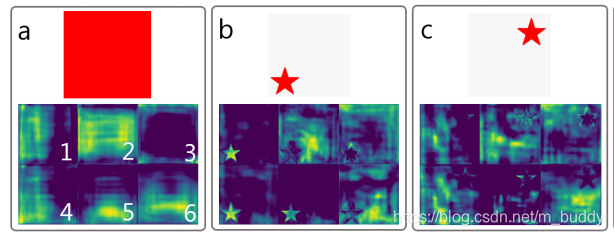
对于上图a,使用无padding的FCNs是得不到的,因为输入图像处处相同,卷积权值又共享,那么输出肯定也一样。 作者认为,像ResNet这样现代的FCNs通过连续的padding0,使得其具有隐式学习图像边界距离的能力。所以,ResNet隐含了转移方差于其中,YOLACT得益于此。如图b和图c,明显不同的feature map对不同位置的目标具有不同的响应。

许多原型mask只在图像的某些部分上激活,即它们只激活位于隐式学习边界一侧的对象。例如,上图中原型6学习的是背景信息。通过对这些原型进行组合,网络可以区分同一语义的不同(甚至重叠)的实例,比如在图d中,原型4减去原型5,可以区分开红色伞和绿色伞。
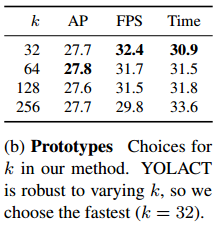
此外,原型学习是可压缩的。也就是说,如果protonet将多个原型的功能合并成一个,那么mask系数分支就会去对应学习相应的组合方法。例如,上图中,原型4具有分割的能力,但同时它又对左下角部分图像具有较高响应,原型5也类似,但它就对右下角部分响应更大。这也就解释了为什么可以根据实际情况调整原型数量(即protonet的输出通道数,默认为32),而又不会带来模型性能的下降。
3. 其它的优化
3.1 Fast NMS
NMS操作是检测算法中用来去除重复检测框的,但是这个步骤也是比较耗时的,这里就是对这部分进行加速,提处了Fast NMS。原始的NMS算法是顺序执行的,这里将其修改为并行执行,这就使得已经被排除的检测结果继续影响其它的检测结果(这个并不存在与传统NMS中),但是这样的改动可以使得Fast NMS算法使用标准的矩阵运算的得到(就可以加速了)。这里提出的新NMS算法其步骤可以归纳为:
- 1)计算类别为 c c c,选取结果top n n n的IoU矩阵,其大小为 c ∗ n ∗ n c*n*n c∗n∗n。在GPU上进行排序已经是可行的,IoU的计算也以被向量化
- 2)其次,通过检查是否有任何得分较高的检测结果且其IoU大于某个阈值
t
t
t,从而找到要删除的检测框。故我们通过将
X
X
X的下三角和对角区域设置为0,来实现:
X k i j = 0 , ∀ k , j , i ≤ j X_{kij}=0,\forall k,j,i\le j Xkij=0,∀k,j,i≤j - 3)上述可以在一个batch上使用triu call实现,之后保留列方向上的最大值,来计算每个检测器的最大IoU 矩阵K。
K k j = max i ( X k i j ) , ∀ k , j K_{kj}=\max_{i} (X_{kij}), \forall k,j Kkj=imax(Xkij),∀k,j - 4)最后,利用阈值 t ( K < t ) t(K\lt t) t(K<t)来处理矩阵,对每个类别保留最优的检测器。
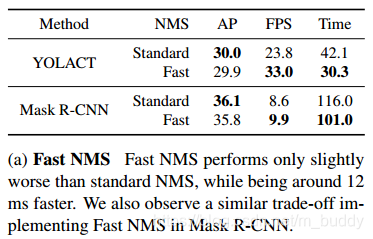
由于约束的放宽,Fast NMS 会删除更多的框,然而这和显著提升速度相比,对性能的影响微不足道(Table 2a)。
Fast NMS 比传统NMS在Cython上的实现快11.8ms,而mAP仅仅下降了0.1%,用Mask R-CNN做对比,Fast NMS快16.5ms,mAP降低了0.3%。
3.2 语义分割损失
Fast NMS 在提升速度的情况下,有少许的性能损失,还有别的方法在提升性能的情况下,对速度没有任何损失。
其中一种方法,在训练中给模型添加额外的损失函数,但在测试中不添加,这样在没有速度损失的情况下有效的提升了特征的丰富性。
故我们在训练过程中,给特征域增加了语义分割损失。因为我们从实例注释中构造损失的真值,没有直接的捕捉语义分割(也就是没有强制要求每个像素都是一个标准类)。
为了在训练中预测,我们简单的将有 c c c个输出通道的 1 × 1 1×1 1×1卷积层直接附加到主干网络最大的特征图( P 3 P_3 P3)上,因为,每个像素都可以分配多于1的类别,我们使用sigmoid和 c c c个通道而不是softmax和 c + 1 c+1 c+1个通道,这样定义损失函数的训练方法将mAP提升了0.4%。
4. 实验结果
4.1 网络的整体性能对比
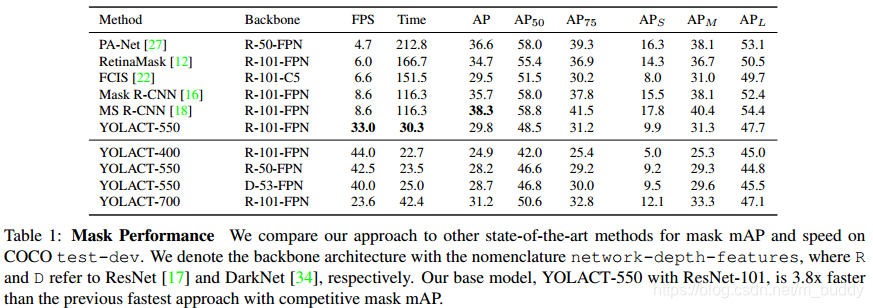
网络的性能与当前的方法的对比如上表所示,文中使用了ResNet-50、ResNet-101与DarkNet53三种基础网络,其性能对比如上表所示,对于需要更快速度的情况下,换用ResNet-50或是DarkNet53是更好的选择,而不是减小图像的尺寸。
4.2 高质量分割
这里得益于高分辨率的分割mask, 138 ∗ 138 138*138 138∗138,和没有经过pooling操作的原始特征用于生成分割掩膜,这里相比Mask R-CNN在95% IoU阈值条件下超过其0.6,这就说明了pooling操作对于分割来说是具有负面影响的。
4.3 分割稳定性分析
本文的方法在动态视频上的稳定性高于Mask R-CNN , Mask R-CNN在帧间过渡的时候有很多跳动,甚至在目标静止的情况下也是一样。之所以认为本文的方法对动态视频更稳定原因有两个:
- 1)本文的mask性能更高,故帧间并没有很大误检;
- 2)本文的模型是单级的,多级模型更多的依赖于第一级产生的区域提议本文的方法当模型在帧间预测多个不同的候选框时,protonet不响应,故本文的方法对动态视频更稳定;

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









