







深度神经网络DNN反向传播BP算法推导、δ法则
基于MATLAB软件和DNN深度神经网络的MNIST数据集手写字符识别
分别仿真了仅有随机梯度下降的DNN网络、应用BatchSize批量训练的DNN网络、应用批量训练和Adam优化算法的DNN网络。
文章目录
前言
\;\;\;\;\; 本文在得出权重w和偏置b的更新公式后,在MATLAB中分别仿真了仅有随机梯度下降SGD的DNN网络、应用BatchSize批量训练的DNN网络、应用批量训练和Adam优化算法的DNN网络,用这三种方法训练MNIST数据集的手写字符识别。仅训练10次,最高准确率达到了97.46%,进一步训练调参准确率还可提升很多。
提示:以下是本篇文章正文内容,转载请附上链接!
一、单个神经元的内部结构
\;\;\;\;\;
神经网络中的神经元是对生物神经元的模拟,它接收来自外部的若干个变量值,为每个变量值赋予不同的权重,对变量进行加权求和,并经过内部激活函数的处理,最终输出激活值。

首先对输入变量进行加权求和:
z
=
x
1
∗
w
1
+
x
2
∗
w
2
+
x
3
∗
w
3
+
⋯
+
x
n
∗
w
n
+
b
=
∑
i
=
1
n
x
i
w
i
+
b
=
x
∗
w
+
b
\begin{aligned}\text{z}&=x_1*w_1+x_2*w_2+x_3*w_3+\cdots+x_n*w_n+b\\&=\sum_{i=1}^nx_iw_i+b\\&=\mathbf{x}*\mathbf{w}+b\end{aligned}
z=x1∗w1+x2∗w2+x3∗w3+⋯+xn∗wn+b=i=1∑nxiwi+b=x∗w+b
然后将加权求和结果输入到激活函数:
y
=
f
(
z
)
=
f
(
x
∗
w
+
b
)
y=f(z)=f(\mathbf{x}*\mathbf{w}+b)
y=f(z)=f(x∗w+b)
输入
x
\mathbf{x}
x:神经元的输入变量值,可以理解为上一层神经元的输出结果。
权重
w
\mathbf{w}
w:每一个输入对应着一个权重,代表着该输入的重要程度,重要程度越高,则权重越大。
偏置b:偏置可以理解为激活该神经元的阈值,当超过阈值时该神经元被激活。
激活函数f:当输入激励达到一定强度,神经元就会被激活,产生输出信号。模拟这一细胞激活过程的函数,就叫激活函数。
输出y:激活函数的输出结果,不同的激活函数有着不同的输出结果。
二、前向传播
先进行相关符号的定义:
w
j
k
l
w_{jk}^{l}
wjkl:第(
l
−
1
l-1
l−1)层的第
k
k
k 个神经元连接到第
l
l
l 层的第
j
j
j 个神经元的权重
b
j
l
b_j^l
bjl:第
l
l
l 层的第
j
j
j 个神经元的偏置
z
j
l
z_j^l
zjl:第
l
l
l 层的第
j
j
j 个神经元的带权输入(上一层的激活值与偏置的加权之和)
a
j
l
a_j^l
ajl:第
l
l
l 层的第
j
j
j 个神经元的激活值

第1层神经元的带权输入值为:
[
z
1
(
1
)
z
2
(
1
)
]
=
[
w
11
(
1
)
w
12
(
1
)
w
21
(
1
)
w
22
(
1
)
]
[
x
1
x
2
]
+
[
b
1
(
1
)
b
2
(
1
)
]
=
w
1
x
+
b
1
\begin{bmatrix}z_1^{(1)}\\z_2^{(1)}\end{bmatrix}=\begin{bmatrix}w_{11}^{(1)}&w_{12}^{(1)}\\w_{21}^{(1)}&w_{22}^{(1)}\end{bmatrix}\begin{bmatrix}x_1\\x_2\end{bmatrix}+\left[\begin{array}{c}b_1^{(1)}\\b_2^{(1)}\end{array}\right]=\mathbf{w}_1\mathbf{x}+\mathbf{b}_1
[z1(1)z2(1)]=[w11(1)w21(1)w12(1)w22(1)][x1x2]+[b1(1)b2(1)]=w1x+b1
第1层神经元的激活值为,其中
σ
\sigma
σ为激活函数:
y
1
=
[
a
1
(
1
)
a
2
(
1
)
]
=
[
σ
(
z
1
(
1
)
)
σ
(
z
2
(
1
)
)
]
\mathbf{y}_1=\left[\begin{array}{c}a_1^{(1)}\\a_2^{(1)}\end{array}\right]=\left[\begin{array}{c}\sigma\Big(z_1^{(1)}\Big)\\\sigma\Big(z_2^{(1)}\Big)\end{array}\right]
y1=[a1(1)a2(1)]=
σ(z1(1))σ(z2(1))
第2层神经元的带权输入值为:
[
z
1
(
2
)
z
2
(
2
)
]
=
[
w
11
(
2
)
w
12
(
2
)
w
21
(
2
)
w
22
(
2
)
]
[
a
1
(
1
)
a
2
(
1
)
]
+
[
b
1
(
2
)
b
2
(
2
)
]
=
w
2
y
1
+
b
2
\begin{bmatrix}z_1^{(2)}\\z_2^{(2)}\end{bmatrix}=\begin{bmatrix}w_{11}^{(2)}&w_{12}^{(2)}\\w_{21}^{(2)}&w_{22}^{(2)}\end{bmatrix}\left[\begin{array}{c}a_1^{(1)}\\a_2^{(1)}\end{array}\right]+\left[\begin{array}{c}b_1^{(2)}\\b_2^{(2)}\end{array}\right]=\mathbf{w}_2\mathbf{y}_1+\mathbf{b}_2
[z1(2)z2(2)]=[w11(2)w21(2)w12(2)w22(2)][a1(1)a2(1)]+[b1(2)b2(2)]=w2y1+b2
第2层神经元的激活值为:
y
=
[
y
1
y
2
]
=
[
a
1
(
2
)
a
2
(
2
)
]
=
[
σ
(
z
1
(
2
)
)
σ
(
z
2
(
2
)
)
]
\mathbf{y}=\left[\begin{array}{c}y_1\\y_2\end{array}\right]=\left[\begin{array}{c}a_1^{(2)}\\a_2^{(2)}\end{array}\right]=\left[\begin{array}{c}\sigma\Big(z_1^{(2)}\Big)\\\sigma\Big(z_2^{(2)}\Big)\end{array}\right]
y=[y1y2]=[a1(2)a2(2)]=
σ(z1(2))σ(z2(2))
三、反向传播
对于每一个样本,拟合误差用如下二次损失函数表示:
C
=
1
2
∑
j
(
y
j
−
d
j
)
2
=
1
2
∑
j
(
a
j
(
2
)
−
d
j
)
2
\begin{aligned}C&=\frac12\sum_j(y_j-d_j)^2=\frac12\sum_j(a_j^{(2)}-d_j)^2\end{aligned}
C=21j∑(yj−dj)2=21j∑(aj(2)−dj)2
其中
j
j
j 表示第
j
j
j 个神经元,
y
j
y_j
yj 表示输出层第
j
j
j 个神经元的预测值(激活值),
d
j
d_j
dj 表示第
j
j
j 个神经元的标签。

第2层神经元的误差为:
e
1
=
y
1
−
d
1
e
2
=
y
2
−
d
2
e_{1} = y_{1} - d_{1}\\e_{2} = y_{2} - d_{2}
e1=y1−d1e2=y2−d2
第2层第1个神经元的
δ
1
(
2
)
\delta_1^{(2)}
δ1(2) 为:
δ
1
(
2
)
=
∂
C
∂
z
1
(
2
)
=
∂
C
∂
a
1
(
2
)
⋅
∂
a
1
(
2
)
∂
z
1
(
2
)
=
1
2
∑
j
(
a
j
(
2
)
−
d
j
)
2
∂
a
1
(
2
)
⋅
∂
a
1
(
2
)
∂
z
1
(
2
)
=
(
a
1
(
2
)
−
d
1
)
⋅
∂
a
1
(
2
)
∂
z
1
(
2
)
=
(
y
1
−
d
1
)
⋅
σ
′
(
z
1
(
2
)
)
=
σ
′
(
z
1
(
2
)
)
⋅
e
1
\begin{aligned} \delta_1^{(2)}=\frac{\partial C}{\partial z_1^{(2)}} &=\frac{\partial C}{\partial a_1^{(2)}}\cdot\frac{\partial a_1^{(2)}}{\partial z_1^{(2)}} =\frac{\frac12\sum_j(a_j^{(2)}-d_j)^2}{\partial a_1^{(2)}}\cdot\frac{\partial a_1^{(2)}}{\partial z_1^{(2)}} \\ &=\begin{pmatrix}a_1^{(2)}-d_1\end{pmatrix}\cdot\frac{\partial a_1^{(2)}}{\partial z_1^{(2)}} =(y_1-d_1)\cdot\sigma^{\prime}(z_1^{(2)})=\sigma^{\prime}(z_1^{(2)})\cdot e_{1} \end{aligned}
δ1(2)=∂z1(2)∂C=∂a1(2)∂C⋅∂z1(2)∂a1(2)=∂a1(2)21∑j(aj(2)−dj)2⋅∂z1(2)∂a1(2)=(a1(2)−d1)⋅∂z1(2)∂a1(2)=(y1−d1)⋅σ′(z1(2))=σ′(z1(2))⋅e1
同理,第2层第2个神经元的
δ
2
(
2
)
\delta_2^{(2)}
δ2(2) 为:
δ
2
(
2
)
=
σ
′
(
z
2
(
2
)
)
⋅
e
2
\begin{aligned} \delta_2^{(2)}=\sigma^{\prime}(z_2^{(2)})\cdot e_{2} \end{aligned}
δ2(2)=σ′(z2(2))⋅e2
第2层第1个神经元偏置
b
1
(
2
)
b_1^{(2)}
b1(2) 的偏导数为:
∂
C
∂
b
1
(
2
)
=
∂
C
∂
z
1
(
2
)
⋅
∂
z
1
(
2
)
∂
b
1
(
2
)
=
δ
1
(
2
)
⋅
∂
(
w
11
(
2
)
a
1
(
1
)
+
w
12
(
2
)
a
2
(
1
)
+
b
1
(
2
)
)
∂
b
1
(
2
)
=
δ
1
(
2
)
\begin{aligned} \frac{\partial C}{\partial b_1^{(2)}}=\frac{\partial C}{\partial z_1^{(2)}}\cdot\frac{\partial z_1^{(2)}}{\partial b_1^{(2)}} =\delta_1^{(2)}\cdot\frac{\partial\left(w_{11}^{(2)}a_1^{(1)}+w_{12}^{(2)}a_2^{(1)}+b_1^{(2)}\right)}{\partial b_1^{(2)}} =\delta_1^{(2)} \end{aligned}
∂b1(2)∂C=∂z1(2)∂C⋅∂b1(2)∂z1(2)=δ1(2)⋅∂b1(2)∂(w11(2)a1(1)+w12(2)a2(1)+b1(2))=δ1(2)
同理:
∂
C
∂
b
2
(
2
)
=
=
δ
2
(
2
)
\begin{aligned} \frac{\partial C}{\partial b_2^{(2)}}= =\delta_2^{(2)} \end{aligned}
∂b2(2)∂C==δ2(2)
第2层第1个神经元权重
w
11
(
2
)
w_{11}^{(2)}
w11(2) 的偏导数为:
∂
C
∂
w
11
(
2
)
=
∂
C
∂
z
1
(
2
)
⋅
∂
z
1
(
2
)
∂
w
11
(
2
)
=
δ
1
(
2
)
⋅
∂
(
w
11
(
2
)
a
1
(
1
)
+
w
12
(
2
)
a
2
(
1
)
+
b
1
(
2
)
)
∂
w
11
(
2
)
=
δ
1
(
2
)
⋅
a
1
(
1
)
\begin{aligned} \frac{\partial C}{\partial w_{11}^{(2)}} &=\frac{\partial C}{\partial z_1^{(2)}}\cdot\frac{\partial z_1^{(2)}}{\partial w_{11}^{(2)}}=\delta_{1}^{(2)}\cdot\frac{\partial\left(w_{11}^{(2)}a_1^{(1)}+w_{12}^{(2)}a_2^{(1)}+b_1^{(2)}\right)}{\partial w_{11}^{(2)}}=\delta_1^{(2)}\cdot a_1^{(1)} \end{aligned}
∂w11(2)∂C=∂z1(2)∂C⋅∂w11(2)∂z1(2)=δ1(2)⋅∂w11(2)∂(w11(2)a1(1)+w12(2)a2(1)+b1(2))=δ1(2)⋅a1(1)
同理得:
∂
C
∂
w
2
=
[
δ
1
(
2
)
δ
2
(
2
)
]
y
1
T
\begin{aligned} \frac{\partial C}{\partial \mathbf{w}_2} =\left[\begin{array}{c}\delta_1^{(2)}\\\delta_2^{(2)}\end{array}\right] \end{aligned}\mathbf{y}_1^{T}
∂w2∂C=[δ1(2)δ2(2)]y1T

[
e
1
(
1
)
e
2
(
1
)
]
=
[
w
11
(
2
)
w
21
(
2
)
w
12
(
2
)
w
22
(
2
)
]
[
δ
1
δ
2
]
=
w
2
T
[
δ
1
δ
2
]
\begin{bmatrix}e_1^{(1)}\\e_2^{(1)}\end{bmatrix}=\begin{bmatrix}w_{11}^{(2)}&w_{21}^{(2)}\\w_{12}^{(2)}&w_{22}^{(2)}\end{bmatrix}\begin{bmatrix}\delta_1\\\delta_2\end{bmatrix}=\mathbf{w}_2^T\begin{bmatrix}\delta_1\\\delta_2\end{bmatrix}
[e1(1)e2(1)]=[w11(2)w12(2)w21(2)w22(2)][δ1δ2]=w2T[δ1δ2]
那么可以总结以下公式:
δ
j
l
=
(
a
j
l
−
d
j
)
⋅
σ
′
(
z
j
l
)
∂
C
∂
b
j
l
=
δ
j
l
∂
C
∂
w
j
k
l
=
δ
j
l
⋅
a
k
l
−
1
δ
l
−
1
=
(
(
w
l
)
T
δ
l
)
⊙
σ
′
(
z
l
−
1
)
\begin{aligned} &\delta_j^l=(a_j^l-d_j)\cdot\sigma^{\prime}(z_j^l) \\ &\frac{\partial C}{\partial b_j^l}=\delta_j^l \\ &\frac{\partial C}{\partial w_{jk}^l}=\delta_j^l\cdot a_k^{l-1} \\ &\delta^{l-1}=\left(\left(w^l\right)^T\delta^l\right)\odot\sigma^{\prime}\left(z^{l-1}\right) \end{aligned}
δjl=(ajl−dj)⋅σ′(zjl)∂bjl∂C=δjl∂wjkl∂C=δjl⋅akl−1δl−1=((wl)Tδl)⊙σ′(zl−1)
然后更新权重和偏置:
w
j
k
l
→
(
w
j
k
l
)
′
=
w
j
k
l
−
α
∂
C
∂
w
j
k
l
b
j
l
→
(
b
j
l
)
′
=
b
j
l
−
α
∂
C
∂
b
j
l
w_{jk}^l\to\left(w_{jk}^l\right)^{\prime}=w_{jk}^l-\alpha\frac{\partial C}{\partial w_{jk}^l}\\b_j^l\to\left(b_j^l\right)^{\prime}=b_j^l-\alpha\frac{\partial C}{\partial b_j^l}
wjkl→(wjkl)′=wjkl−α∂wjkl∂Cbjl→(bjl)′=bjl−α∂bjl∂C
四、使用 SGD 方法在 MATLAB 中进行 MNIST 数据集的手写字符识别
\;\;\;\;\;
设置四层神经网络,参数设置如下:
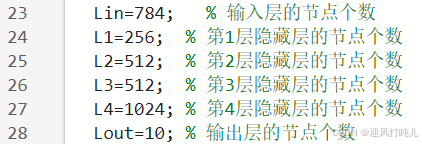
\;\;\;\;\;
每层神经元的数量支持随意修改,仅使用SGD训练神经网络,每一个样本更新一次梯度,当学习率设为0.001,迭代次数设为10时,训练网络的准确率如下图所示,最高准确率为95.2%,很明显还没收敛,还可以继续训练更多的次数。

五、使用 BatchSize 方法在 MATLAB 中进行 MNIST 数据集的手写字符识别
\;\;\;\;\;
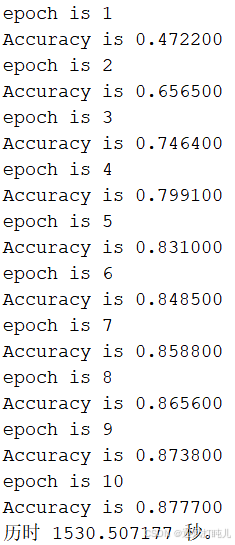
神经网络设置参数保持不变,学习率设为0.01,应用批次训练的方法训练神经网络,批次大小设置为256,训练10次的结果如下图所示,最高准确率为87.77%,很明显还没收敛,还可以继续训练更多的次数。可见批次训练梯度更新较慢且训练结果比较平缓。
六、使用 Adam 优化算法在 MATLAB 中进行 MNIST 数据集的手写字符识别
\;\;\;\;\; Adam算法是一种自适应学习率的优化算法,结合了动量和自适应学习率的特性。主要思想是根据参数的梯度来动态调整每个参数的学习率。核心原理包括:
- 动量(Momentum):Adam算法引入了动量项,以平滑梯度更新的方向。这有助于加速收敛并减少震荡。
- 自适应学习率:Adam算法计算每个参数的自适应学习率,允许不同参数具有不同的学习速度。
- 偏差修正(Bias Correction):Adam算法迭代初期可能受偏差影响,因此它使用偏差修正来纠正这个问题。
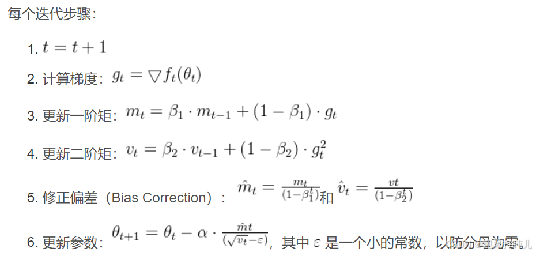
\;\;\;\;\; 神经网络设置参数保持不变,学习率设为0.001,应用批次训练的方法和Adam 优化算法训练神经网络,批次大小设置为256,训练10次的结果如下图所示,最高准确率为97.46%,很明显还没收敛,还可以继续训练更多的次数。可见在批次训练上应用Adam优化算法大幅提升训练效果,所以自从Adam优化算法一被提出就在深度学习中得到广泛应用。

七、MATLAB源代码
基于MATLAB软件和DNN深度神经网络的MNIST数据集手写字符识别源代码
总结
\;\;\;\;\; 以上就是本文的全部内容,在得出权重和偏置的更新公式后,在MATLAB中分别仿真了仅有随机梯度下降的DNN网络、应用BatchSize批量训练的DNN网络、应用批量训练和Adam优化算法的DNN网络,对比各自的训练效果可以得出应用不同训练机制和优化算法的训练效果好坏。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











