




下面的博客内容完美地展示了如何设计一个 “主-从”详情页接口,并将 JOIN FETCH和DTO投影分页这两种强大的JPA技巧结合起来,构建出一个功能复杂但性能卓越的API。
JPA“主-从”详情页查询的艺术:JOIN FETCH与DTO分页的完美协奏
在开发Web应用时,“主-从”详情页是一个极其常见的场景。想象一下“订单详情页”:上方是订单的主信息(订单号、总价),下方是该订单包含的商品分页列表。
如何设计一个API,能一次性地为这样的页面提供所有需要的数据,同时又能保证极致的性能?
一个常见的错误做法是,在一个巨大的查询中,试图同时JOIN主表和子表并进行分页。这往往会导致内存分页的性能灾难,或者因为笛卡尔积而产生错误的数据。
今天,我将带你深入解剖一个GET /api/app/solution-brands/{id}/detail(小程序品牌详情)接口。我们将看到,如何通过一种名为 “两步查询法”的优雅架构模式,将JOIN FETCH(用于获取主信息)和DTO投影分页(用于获取子列表)这两大神器结合,演奏出一曲高性能数据查询的完美协奏。
业务需求:一个“品牌主页”的全景视图 🖼️
我们的目标是为小程序端开发一个“品牌详情页”,这个页面需要展示一个“全景”视图:
- 品牌主信息:品牌的Logo、名称、英文名、以及小程序专属的介绍(来自
SolutionBrand和Brand两个实体)。 - 产品分页列表:该品牌下的所有商品(
SolutionProduct)的分页列表,且每个商品只需展示部分核心字段。
核心挑战:
- 数据聚合:需要的数据分散在
SolutionBrand,Brand,SolutionProduct,Product等多张表中。 - 子列表分页:产品列表必须支持高效的数据库分页。
- 性能:整个页面的数据,必须通过最少的数据库交互来获取。
解决方案:“两步查询法”——先查主,再分页查从
我们的核心策略是分而治之。将一个复杂的页面数据聚合任务,分解为两个职责单一、各自最高效的数据库查询。
第一步:JOIN FETCH——高效获取“主信息”
我们首先通过一次JOIN FETCH查询,将页面“上半部分”需要的所有品牌信息一次性加载到内存中。
Repository层:
// SolutionBrandRepository.java
@Query("SELECT sb FROM SolutionBrand sb JOIN FETCH sb.brand WHERE sb.id = :brandId AND sb.admin.id = :adminId")
Optional<SolutionBrand> findDetailByIdAndAdminId(...);
技术解读:
JOIN FETCH sb.brand: 这是避免N+1的关键。它在查询SolutionBrand的同时,就将其关联的Brand实体完整地加载了回来。- 安全校验:
WHERE ... AND sb.admin.id = :adminId确保了数据隔离。
对应的SQL (Structured Query Language) 日志:
-- 日志1: 一次性查询品牌主信息
Hibernate:
select ... from solution_brand sb
inner join brand b on sb.brand_id=b.id
where sb.id=? and sb.admin_id=?
这一步,我们用一次高效的查询,就获取了所有非列表数据。
第二步:DTO投影分页——精准获取“子列表”
现在,我们来处理页面“下半部分”的产品分页列表。为了极致的性能,我们使用DTO (Data Transfer Object) 投影。
Repository层:
// SolutionProductRepository.java
@Query(value = "SELECT new com.productQualification.suitselection.vo.AppBrandProductVO(" +
" sp.id, sp.appGroupBuyPrice, p.image, p.name, ...)" +
"FROM SolutionProduct sp JOIN sp.product p " +
"WHERE sp.solutionBrand.id = :brandId AND sp.appDisplayStatus = 1",
countQuery = "SELECT count(sp) FROM SolutionProduct sp WHERE sp.solutionBrand.id = :brandId AND ...")
Page<AppBrandProductVO> findProductsByBrandId(@Param("brandId") Integer brandId, Pageable pageable);
技术解读:
SELECT new ...: 构造器表达式直接将查询结果映射到轻量级的AppBrandProductVO,避免加载完整的SolutionProduct和Product实体。Pageable+countQuery: 实现了真正的数据库分页,高效且准确。
对应的SQL日志:
-- 日志2: DTO投影分页查询,获取产品子列表
Hibernate:
select
sp.id as col_0_0_, sp.app_group_buy_price as col_1_0_, p.image as col_2_0_, ...
from
solution_product sp
inner join
product p on sp.product_id=p.id
where
sp.solution_brand_id=? and sp.app_display_status=1
order by ... limit ?
Service层:优雅的“数据织工”
Service层的职责,就是将这两步查询的结果,在内存中优雅地“编织”成最终的响应VO (View Object)。
// AppSolutionBrandService.java
@Transactional(readOnly = true)
public AppBrandDetailVO getBrandDetailWithProducts(...) {
// **第一步:查询主信息**
SolutionBrand solutionBrand = brandRepository.findDetailByIdAndAdminId(...)
.orElseThrow(...);
// **第二步:分页查询子列表**
Pageable pageable = query.toPageable();
Page<AppBrandProductVO> productPage = productRepository.findProductsByBrandId(...);
// **第三步:组装最终的VO**
AppBrandDetailVO resultVO = new AppBrandDetailVO();
resultVO.setName(solutionBrand.getBrand().getName());
// ... 填充其他品牌信息 ...
resultVO.setProducts(productPage); // <-- 将产品分页结果直接放入
return resultVO;
}
结论:“主-从”查询的最佳实践 💡
这次“品牌详情页”接口的实现,完美地展示了处理“主-从”数据聚合的最佳实践:
- 坚决分离:永远不要试图在一个SQL查询中,同时对主表和子表进行
JOIN并对子表进行分页。这会导致数据错误和性能问题。 - 主表用
JOIN FETCH:对于主信息的获取,使用JOIN FETCH来一次性加载所有需要的关联对象。 - 子表用DTO投影分页:对于子列表的获取,使用独立的、带
Pageable的DTO投影查询,实现最高效的数据库分页。
通过这套“两步查询法”的组合拳,我们用固定的2次数据库交互,就构建了一个功能复杂、但性能卓越、代码清晰的详情页API。
附录:图表化总结与深度解析 📊✨
“主-从”查询策略总结表 📋
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
JOIN FETCH (主信息) 🏛️ | 一次性加载对象图,避免N+1 | 存在可接受的“过度查询” | 获取主实体及其关联对象 |
| DTO投影分页 (子列表) 📄 | 性能极致,精准获取,真分页 | 需要为VO编写构造器 | 获取关联的子实体分页列表 |
| “两步查询法” (组合) ✨ | 性能最优,职责清晰,无N+1 | 需要两次DB (Database) 交互 | “主-从”详情页 |
| 一句话总结 | “先查‘房产证’,再分页查‘房间列表’” |
接口处理流程图 (Flowchart) 💡
关键交互时序图 (Sequence Diagram) 🔄
实体状态图 (State Diagram) 🚦
此接口为只读操作,不改变任何实体状态。
核心类图 (Class Diagram) 🏗️
展示了Service层如何协调两个Repository和多个VO。
实体关系图 (Entity Relationship Diagram) 🔗
用ER图的形式更直观地展示查询涉及的所有数据库表。
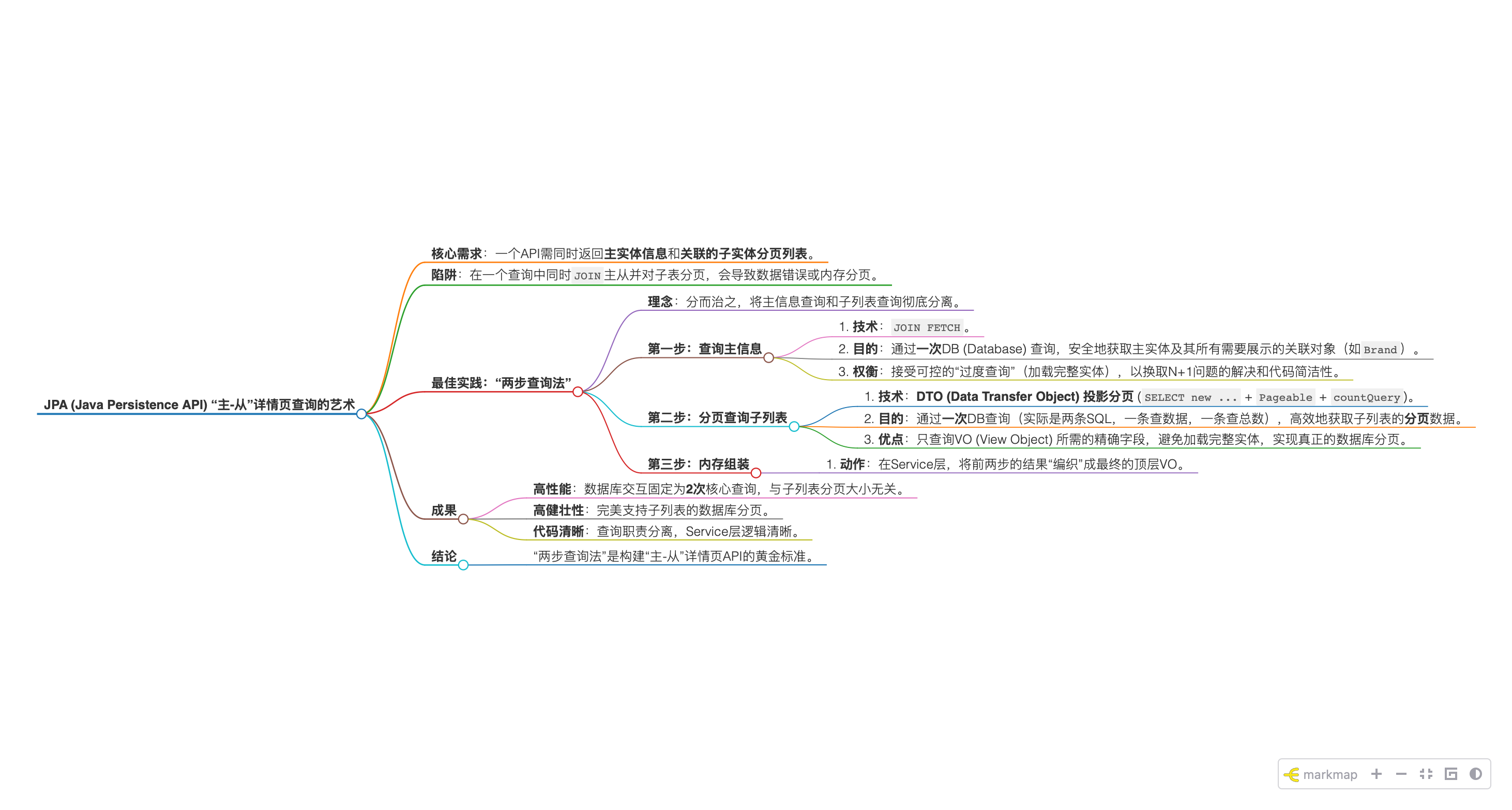
思维导图 (Markdown Format) 🧠
- JPA (Java Persistence API) “主-从”详情页查询的艺术
- 核心需求:一个API需同时返回主实体信息和关联的子实体分页列表。
- 陷阱:在一个查询中同时
JOIN主从并对子表分页,会导致数据错误或内存分页。 - 最佳实践:“两步查询法”
- 理念:分而治之,将主信息查询和子列表查询彻底分离。
- 第一步:查询主信息
- 技术:
JOIN FETCH。 - 目的:通过一次DB (Database) 查询,安全地获取主实体及其所有需要展示的关联对象(如
Brand)。 - 权衡:接受可控的“过度查询”(加载完整实体),以换取N+1问题的解决和代码简洁性。
- 技术:
- 第二步:分页查询子列表
- 技术:DTO (Data Transfer Object) 投影分页 (
SELECT new ...+Pageable+countQuery)。 - 目的:通过一次DB查询(实际是两条SQL,一条查数据,一条查总数),高效地获取子列表的分页数据。
- 优点:只查询VO (View Object) 所需的精确字段,避免加载完整实体,实现真正的数据库分页。
- 技术:DTO (Data Transfer Object) 投影分页 (
- 第三步:内存组装
- 动作:在Service层,将前两步的结果“编织”成最终的顶层VO。
- 成果
- 高性能:数据库交互固定为2次核心查询,与子列表分页大小无关。
- 高健壮性:完美支持子列表的数据库分页。
- 代码清晰:查询职责分离,Service层逻辑清晰。
- 结论
- “两步查询法”是构建“主-从”详情页API的黄金标准。



















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









