




完美地展示了如何设计一个 “深度复制”接口,并将JOIN FETCH和JPA级联保存这两个强大的特性结合起来,构建出一个功能复杂但代码优雅的高性能API。
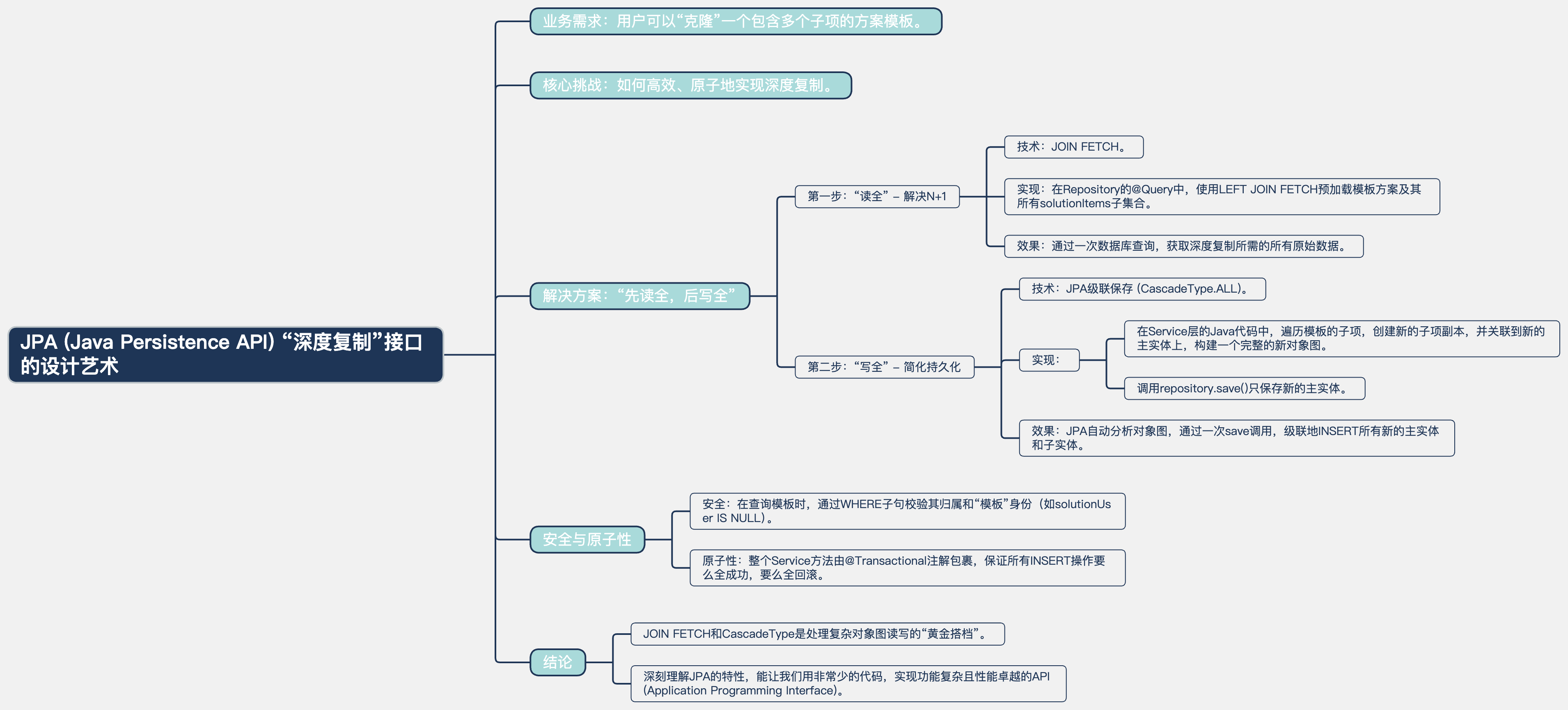
JPA中的“克隆”艺术:如何为一个“复制方案”接口实现高效的深度复制
在软件开发中,“模板”是一个常见的设计模式。我们预设一些优秀的模板,用户可以一键“克隆”并在此基础上进行修改,从而极大地提升用户体验和工作效率。
然而,实现一个“克隆”或“复制”接口,特别是当模板对象还包含一个子对象集合(如一个“方案”包含多个“产品项”)时,就变得不再简单。我们必须面对一个核心挑战:如何高效地实现“深度复制”,避免在复制子对象集合时陷入N+1查询的性能陷阱?
今天,我将带你深入解剖一个POST /api/app/solutions/{templateId}/copy(小程序复制方案模板)接口。我们将看到,如何通过**JOIN FETCH进行一次性预加载**,并利用JPA (Java Persistence API) 级联保存的“魔法”,构建出一个既安全又具备高性能的“深度复制”接口。
业务场景:一键“抄作业”,创建我的专属方案 📝
我们的需求是:在小程序中,提供一些由后台管理员预设的“应季热销”等方案模板。用户看到喜欢的模板后,可以点击“复制”按钮,系统会自动为该用户创建一个一模一样的、新的、可编辑的“自组方案”。
数据模型:
Solution(方案)与SolutionItem(方案项)是一对多关系。- 模板方案的
solutionUser字段为NULL。 - 用户复制后的新方案,
solutionUser字段为当前用户,type字段变为“自组方案”。
核心挑战:
- 深度复制:在创建新
Solution的同时,必须遍历模板的所有SolutionItem,并为新Solution创建全新的SolutionItem副本。 - 性能:在遍历模板的
SolutionItem集合时,如何避免因懒加载(FetchType.LAZY)而引发的N+1查询? - 原子性:创建
Solution和创建所有SolutionItem副本,必须是一个原子操作。
解决方案:“先读全,后写全”的优雅之道
我们的核心策略是:先用一次查询将模板及其所有子项完整读入内存,然后在Java层面构建出完整的、新的对象图,最后用一次save操作让JPA自动完成所有写入。
第一步:JOIN FETCH——高效的“完整读取”
这是解决N+1问题的关键。我们编写一个查询,它在查找模板方案的同时,就将其所有的solutionItems子项“贪婪”地加载回来。
Repository层:
// SolutionRepository.java
@Query("SELECT s FROM Solution s LEFT JOIN FETCH s.solutionItems WHERE s.id = :templateId AND s.admin.id = :adminId AND s.solutionUser IS NULL")
Optional<Solution> findTemplateWithItemsByIdAndAdminId(...);
技术解读:
LEFT JOIN FETCH s.solutionItems: 这是性能的基石。它告诉JPA:“在查询Solution时,立即将它关联的solutionItems集合也查出来。”WHERE ... AND s.solutionUser IS NULL: 这是一个重要的安全校验,确保了用户只能复制真正的“模板”方案。
对应的SQL (Structured Query Language) 日志:
-- 日志1: 一次性查询模板及其所有子项
Hibernate:
select ... from solution s0_
left outer join solution_item si1_ on s0_.id=si1_.solution_id
where s0_.id=? and s0_.admin_id=? and (s0_.solution_user_id is null)
这一步,我们用一次高效的查询,就获取了深度复制所需的所有“原材料”。
第二步:Java内存中的“克隆”与“换主”
在Service层,我们进行纯粹的Java对象操作,构建出新的对象图。
// AppSolutionService.java
@Transactional
public AppSolutionCreateVO copySolutionFromTemplate(...) {
// 1. 一次性加载模板及其所有产品项
Solution template = solutionRepository.findTemplateWithItemsByIdAndAdminId(...)
.orElseThrow(...);
// 2. 查找当前用户
SolutionUser currentUser = ...;
// 3. 创建新的方案实体(副本)
Solution newSolution = new Solution();
newSolution.setName(template.getName() + " - 副本");
// ...
// 4. 为副本设置新的“主人”和类型
newSolution.setSolutionUser(currentUser);
newSolution.setAdmin(currentUser.getAdmin());
newSolution.setType(Solution.TYPE_CUSTOM);
// 5. 深度复制产品项
Set<SolutionItem> newItems = template.getSolutionItems().stream()
.map(originalItem -> SolutionItem.builder()
.solution(newSolution) // <-- 关键:关联到新的方案
.solutionProduct(originalItem.getSolutionProduct()) // 引用相同的福利产品
.quantity(originalItem.getQuantity())
.build())
.collect(Collectors.toSet());
newSolution.setSolutionItems(newItems);
// ...
}
第三步:JPA级联保存——“一键写入”的魔法 🪄
这是JPA作为全自动ORM (Object-Relational Mapping) 框架最神奇的地方。
Service层 (续):
// AppSolutionService.java
// ...
// 6. 保存新的方案及其所有级联的方案项
Solution savedSolution = solutionRepository.save(newSolution);
return new AppSolutionCreateVO(savedSolution.getId());
}
save(newSolution)背后的魔法:
- 由于
Solution实体中的solutionItems集合上设置了cascade = CascadeType.ALL,当我们调用save(newSolution)时,JPA会自动:INSERT主实体:先将newSolution插入到solution表中。INSERT子实体:然后遍历newSolution.getSolutionItems()集合,将里面的每一个新的SolutionItem实例,都INSERT到solution_item表中。
对应的SQL日志:
-- 2. 查找当前用户
Hibernate: select ... from solution_user where id=?
-- 3. 插入新的Solution主表
Hibernate: insert into solution (...) values (...)
-- 4. 级联插入所有新的SolutionItem子表
Hibernate: insert into solution_item (...) values (...)
Hibernate: insert into solution_item (...) values (...)
Hibernate: insert into solution_item (...) values (...)
结论:JOIN FETCH与Cascade的完美协奏 🎼
这次“深度复制”接口的实现,完美地展示了JPA中两个核心特性的协同工作:
JOIN FETCH负责“读”:它像一个高效的“采购员”,通过一次数据库交互,就将复制所需的所有“原材料”(模板及其所有子项)一次性采购回来,彻底杜绝了N+1问题。CascadeType.ALL负责“写”:它像一个智能的“装配工”,我们只需要在Java内存中将新的对象图“搭建”好,一次save()调用,它就能自动地将整个图的所有部分(主实体和所有子实体)持久化到数据库中。
通过这套“读写”组合拳,我们构建了一个功能复杂,但代码清晰、性能卓越的“克隆”接口。
附录:图表化总结与深度解析 📊✨
核心技术总结表 📋
| 技术 | 在本接口中的角色 | 解决的核心问题 |
|---|---|---|
JOIN FETCH | 高效读取器 📖 | N+1查询,避免在遍历子项时多次查询DB |
CascadeType.ALL | 智能写入器 ✍️ | 手动多次save,简化了持久化复杂对象图的代码 |
@Transactional | 安全保障员 🛡️ | 数据不一致,保证主实体和子实体的创建是原子操作 |
| 一句话总结 ✨ | “一次读全,一次写全,事务保证安全” |
接口处理流程图 (Flowchart) 💡
关键交互时序图 (Sequence Diagram) 🔄
实体状态图 (State Diagram) 🚦
以新创建的Solution和SolutionItem为例,展示其状态流转。
核心类图 (Class Diagram) 🏗️
展示了Solution与SolutionItem之间的一对多和级联关系。
实体关系图 (Entity Relationship Diagram) 🔗
用ER图的形式更直观地展示Solution与SolutionItem的关系。
思维导图 (Markdown Format) 🧠



















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









