




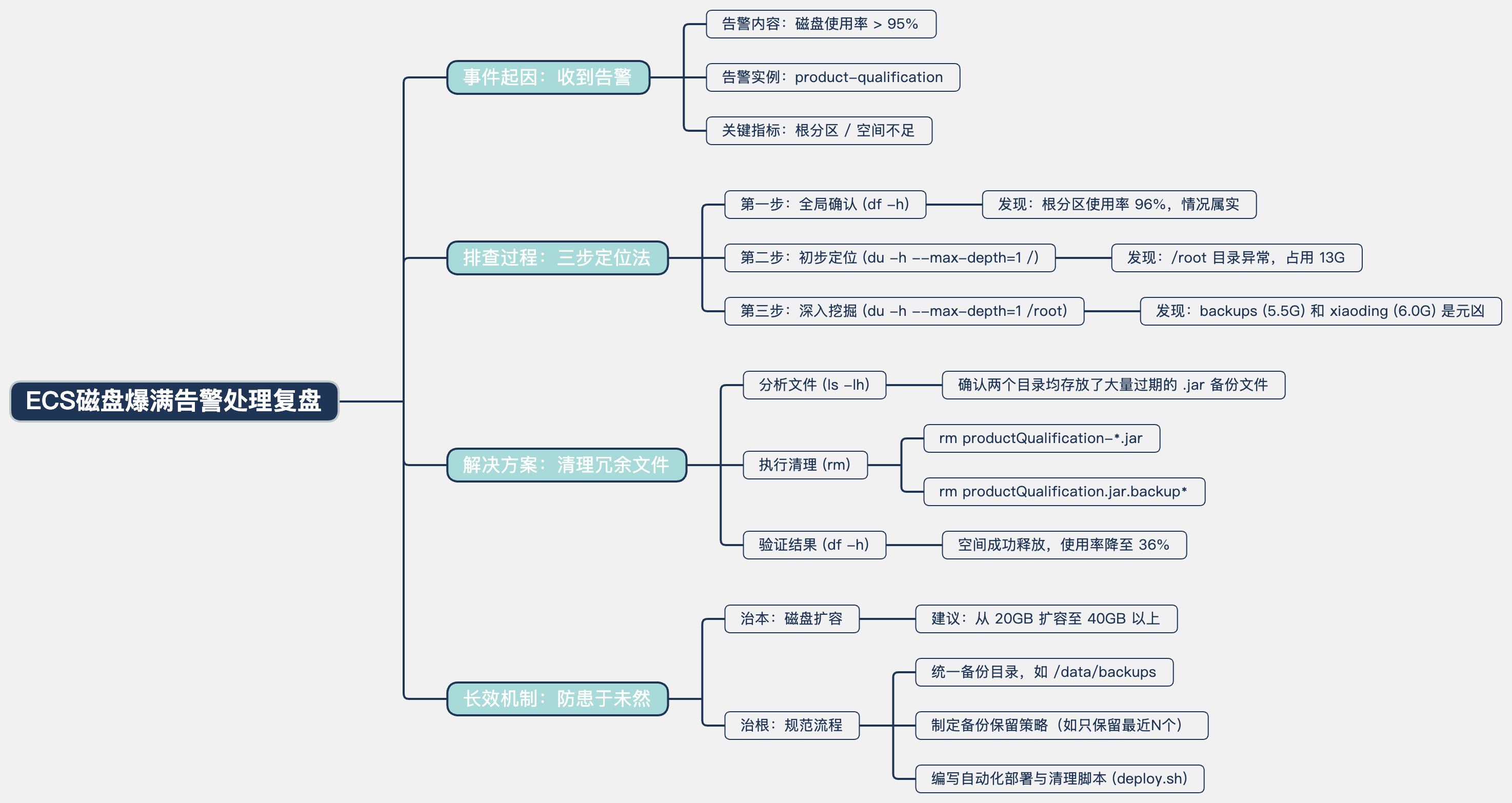
从96%到36%:一次阿里云ECS磁盘爆满告警的实战排查与根治全记录
“叮咚!”——凌晨,一条来自阿里云的告警短信划破了宁静。对于任何一个开发者或运维人员来说,这声音都足以让人心头一紧。点开一看,果然是线上服务器的紧急告警:磁盘使用率超过95%。
磁盘爆满是最高优先级的告警之一,它意味着服务随时可能中断、数据无法写入、甚至系统崩溃。本文将完整复盘一次真实的告警处理过程,从收到告警短信开始,一步步带你分析问题、定位元凶、清理空间,并最终建立起长效的防范机制,将磁盘使用率从危险的96%降至健康的36%。
警报拉响:告警信息分析
首先,让我们看看最初的“案发现场”——告警短信和监控面板。
告警短信:
【阿里云】尊敬的nayaci@icloud.com - …, 华东1(杭州)的云服务器ECS (Elastic Compute Service, 弹性计算服务) 发生告警 , 实例:product-qualification/47.96.108.49[{…}] ,(旧Agent)disk.usage.utilization_device平均值>95 % 当前值: 95.04% 告警规则SystemDefault_acs_ecs_dashboard_vm.DiskUtilization 请登录云监控查看
关键信息提取:
- 问题实例:
product-qualification(IP (Internet Protocol, 互联网协议) 地址:47.96.108.49) - 问题指标:
disk.usage.utilization_device(磁盘设备使用率) - 触发条件:平均值 > 95%,当前值为 95.04%
- 挂载点:
mountpoint=/(根分区)
监控面板:
登录阿里云控制台,监控图表直观地证实了告警的真实性。
左上角的“磁盘使用率(%)”图表显示一条几乎触顶的直线,恒定在100%附近,情况十分危急。
第一章:现场勘查 - 登录服务器,初步诊断
理论分析完毕,立刻开始实战。我们的首要任务是登录服务器,确认具体情况。
步骤1:远程登录服务器
使用SSH (Secure Shell, 安全外壳协议) 工具,以root用户身份登录目标服务器。
ssh root@47.96.108.49
步骤2:确认磁盘整体使用情况 (df -h)
df (disk free, 磁盘可用空间) -h 是我们勘查现场的第一个核心命令,它能以人类可读的格式(-h)列出所有文件系统的磁盘使用情况。
root@product-qualification:~# df -h
Filesystem Size Used Avail Use% Mounted on
udev 1.9G 0 1.9G 0% /dev
tmpfs 377M 2.8M 374M 1% /run
/dev/vda1 20G 18G 946M 96% /
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
tmpfs 377M 0 377M 0% /run/user/0
输出结果清晰地告诉我们:
- 根分区
/dev/vda1的总大小为 20G。 - 已用空间 18G,可用空间仅剩 946M。
- 使用率高达 96%,与告警信息完全吻合。
第二章:追根溯源 - 寻找占用空间的“真凶”
明确了是根分区的问题后,下一步就是找出到底是什么文件或目录占用了这18G的空间。这里我们请出第二位“神探”——du (disk usage, 磁盘使用情况) 命令。
步骤1:从根目录开始,全局扫描 (du -h --max-depth=1 / | sort -rh)
这个命令组合非常强大:
du -h --max-depth=1 /:计算根目录/下第一层所有目录和文件的大小。| sort -rh:通过管道将结果传递给sort命令,-r表示逆序(从大到小),-h表示按人类可读的数值(如G, M)排序。
root@product-qualification:~# du -h --max-depth=1 / | sort -rh
18G /
13G /root
2.0G /usr
1.6G /var
712M /lib
...
结果一目了然,/root 目录竟然占用了13G! 这极不寻常。通常 /root 目录只存放管理员的少量配置文件,不应如此庞大。我们找到了头号嫌疑犯。
步骤2:层层深入,锁定具体目录
我们继续对 /root 目录使用同样的排查方法。
root@product-qualification:~# cd /root
root@product-qualification:~# du -h --max-depth=1 . | sort -rh
13G .
6.0G ./xiaoding
5.5G ./backups
294M ./.ssh
164M ./logs
...
案情进一步明朗,/root 目录下的 xiaoding (6.0G) 和 backups (5.5G) 这两个子目录是罪魁祸首,它们联手贡献了超过11G的空间。
第三章:执行清理 - 快速释放空间
现在我们已经锁定了目标,可以开始清理行动了。我们先从名字看起来最像“垃圾堆”的 backups 目录入手。
步骤1:分析并清理 /root/backups 目录
进入目录,使用 ls (list, 列出文件) -lh 查看文件详情。
root@product-qualification:~/backups# ls -lh
total 5.5G
...
-rw-r--r-- 1 root root 292M Nov 14 2023 productQualification-2311140254.jar
-rw-r--r-- 1 root root 292M Nov 14 2023 productQualification-2311140256.jar
...
-rw-r--r-- 1 root root 293M Mar 28 2024 productQualification-2403281344.jar
-rw-r--r-- 1 root root 293M Dec 25 2024 productQualification.jar
原来这里堆积了大量带有时间戳的Java应用(.jar)备份文件。这显然是由于不规范的部署流程,只备份不清理导致的。我们只需要保留最新的 productQualification.jar 即可。
执行清理:
# 使用通配符*删除所有带时间戳的旧备份
root@product-qualification:~/backups# rm productQualification-*.jar
检查战果:
root@product-qualification:~/backups# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 20G 13G 6.1G 68% /
效果显著! 磁盘使用率瞬间从96%降至68%,可用空间恢复到6.1G,服务器警报解除!
步骤2:分析并清理 /root/xiaoding 目录
虽然警报解除了,但我们还要清理另一个“占地大户”。同样的方法,进入 xiaoding 目录并查看。
root@product-qualification:~/xiaoding# ls -lh
total 6.0G
-rw-r--r-- 1 root root 293M Dec 29 2024 productQualification.jar.backup1
-rw-r--r-- 1 root root 293M Jan 14 2025 productQualification.jar.backup10
...
-rw-r--r-- 1 root root 293M Feb 11 2025 productQualification.jar.backup21
真相大白,这里是另一套备份规则产生的冗余文件。毫不犹豫,全部删除。
执行清理:
root@product-qualification:~/xiaoding# rm productQualification.jar.backup*
检查最终成果:
root@product-qualification:~/xiaoding# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 20G 6.5G 13G 36% /
完美! 磁盘使用率最终降至健康的 36%,可用空间达到 13G。本次紧急救援任务圆满完成。
第四章:亡羊补牢 - 建立长效防范机制
解决燃眉之急只是第一步,更重要的是防止历史重演。我们需要从根源上解决问题。
根本原因分析:
- 磁盘容量规划不足:20GB的系统盘对于一个需要持续部署和产生日志的线上应用来说,容量过小,容错空间极低。
- 缺乏规范的备份策略:备份文件被随意存放在
/root目录下,并且没有自动清理旧备份的机制,导致无限累积。
长效解决方案:
1. 【治本之策】磁盘扩容
这是最直接、最有效的办法。登录阿里云ECS控制台,为该实例的系统盘执行在线扩容操作,建议至少扩容到 40GB或50GB。这能极大地提高服务器的稳定性,避免因容量问题引发的各种“血案”。
2. 【规范流程】建立自动化备份与清理策略
我们不能再依赖“手动备份-忘记删除”这种原始且危险的模式。应该通过一个简单的自动化脚本来规范部署和备份流程。
- 统一备份位置:创建专门的备份目录,如
mkdir(make directory, 创建目录)-p /data/backups/product-qualification。 - 实施保留策略:例如,只保留最近5个版本的备份。
示例:一个简单的自动化部署与备份脚本 (deploy.sh)
#!/bin/bash
# --- 配置区 ---
APP_NAME="productQualification"
APP_DIR="/opt/app"
BACKUP_DIR="/data/backups/product-qualification"
JAR_FILE_NAME="${APP_NAME}.jar"
MAX_BACKUPS=5 # 最多保留的备份数量
# --- 脚本正文 ---
# 1. 确保备份目录存在
mkdir -p ${BACKUP_DIR}
# 2. 备份当前正在运行的版本
if [ -f "${APP_DIR}/${JAR_FILE_NAME}" ]; then
TIMESTAMP=$(date +"%Y%m%d-%H%M%S")
BACKUP_FILE="${BACKUP_DIR}/${JAR_FILE_NAME}.${TIMESTAMP}"
echo "正在备份当前版本到 ${BACKUP_FILE} ..."
cp "${APP_DIR}/${JAR_FILE_NAME}" "${BACKUP_FILE}"
fi
# 3. 清理旧的备份
echo "正在清理旧备份,只保留最新的 ${MAX_BACKUPS} 个..."
# ls -t: 按修改时间排序 | tail -n +X: 从第X行开始显示 | xargs rm -f: 删除
ls -t ${BACKUP_DIR}/${JAR_FILE_NAME}.* | tail -n +$((${MAX_BACKUPS} + 1)) | xargs -r rm -f
# 4. 部署新版本 (假设新包已上传到/tmp/new_version.jar)
echo "正在部署新版本..."
# systemctl stop ${APP_NAME} # 停止服务
cp /tmp/new_version.jar ${APP_DIR}/${JAR_FILE_NAME}
# systemctl start ${APP_NAME} # 启动服务
echo "部署完成!"
未来,每次部署只需运行这个脚本,它就能自动完成备份、清理、部署的全过程,一劳ỳ永逸。
✨ 总结与图表回顾 📈
一次看似惊心动魄的磁盘告警,通过一套清晰的排查逻辑(df -> du -> ls)和果断的清理操作,最终被轻松化解。更重要的是,这次经历促使我们审视并优化了服务器的管理策略。记住,优秀的运维不仅在于能快速“救火”🔥,更在于能构建一个不会“着火”的系统 🛡️。希望这次完整的实战记录,能为你未来的服务器管理工作带来帮助。
📝 核心流程总结表
| 步骤 🔢 | 核心命令 💻 | 目的 🎯 | 关键发现/成果 💡 |
|---|---|---|---|
| 1. 告警确认 | df -h | 确认磁盘使用率,验证告警真实性 | 根分区 / 使用率高达 96% |
| 2. 全局排查 | du -h --max-depth=1 / | sort -rh | 从根目录查找最大的目录 | 锁定嫌疑犯:/root 目录占用 13G |
| 3. 深入排查 | du -h --max-depth=1 /root | 进一步分析 /root 目录内部构成 | 发现元凶:backups (5.5G) 和 xiaoding (6.0G) |
| 4. 清理行动 | rm <文件名> | 删除两个目录下的冗余备份文件 | 成功释放 11.5G 空间 |
| 5. 最终验证 | df -h | 确认问题已解决 | 磁盘使用率降至健康的 36% ✅ |
🗺️ 故障排查流程图 (Flowchart)
🔄 运维交互时序图 (Sequence Diagram)
🚦 服务器状态图 (State Diagram)
🏗️ 自动化脚本类图 (Class Diagram)
🔗 服务器文件系统实体关系图 (Entity Relationship Diagram)
🧠 思维导图 (Markdown Format)



















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









