




Spark-TTS:基于大语言模型的语音合成革新者 🚀
(全称解析 + 核心特性 + 行业影响全解读)
一、概念定义与技术定位
1. 英文全称
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model
• 关键词解析:
• LLM-Based:基于Qwen2.5大语言模型架构
• Efficient:单阶段生成架构,推理速度提升2.3倍
• Text-to-Speech:支持中英文混合生成与零样本语音克隆
2. 中文翻译
基于Qwen的高效文本转语音模型
• 技术定位:全球首个完全基于大语言模型的语音合成系统,突破传统TTS多阶段生成范式
二、核心技术突破
1. BiCodec 编码架构
• 全局令牌:捕捉音色、呼吸节奏等长时特征(每秒50个令牌)
• 语义令牌:编码文本关联信息(wav2vec 2.0特征输入)
2. 动态韵律补偿技术
• 通过Transformer架构分析语调曲线,实现情感标签控制(如"温暖治愈"、“激昂”)
• 测试数据:朗读诗歌时情感传达准确率提升15%
3. 链式思维推理(CoT)
• 分步生成流程:性别预测 → 基频调整 → 语义令牌生成
• 支持细粒度参数控制(语速±30%、音调±5个等级)
三、功能特性与优势对比
| 维度 | 传统TTS | Spark-TTS 创新点 |
|---|---|---|
| 架构复杂度 | 多阶段流水线(文本→声学→波形) | 单阶段端到端生成 |
| 语音克隆 | 需大量样本训练 | 零样本克隆(5秒参考音频) |
| 跨语言支持 | 单一语种生成 | 中英文混合生成(如"2025年Q1财报") |
| 部署效率 | 依赖专用推理框架 | 5分钟完成环境部署 |
四、行业应用场景
1. 内容创作领域
• 短视频配音:上传10秒样音,批量生成风格统一的人声
• 有声书制作:同一角色在不同章节的情绪无缝切换
2. 智能服务领域
• 多语种客服系统:支持粤语、四川话等12种方言
• 无障碍服务:视障人士语音导航(99.2%识别率)
3. 前沿研究方向
• 虚拟人交互:结合3D建模实现唇形同步
• 元宇宙语音基建:支持万人级并发请求
五、开源生态与部署实践
1. 技术生态构成
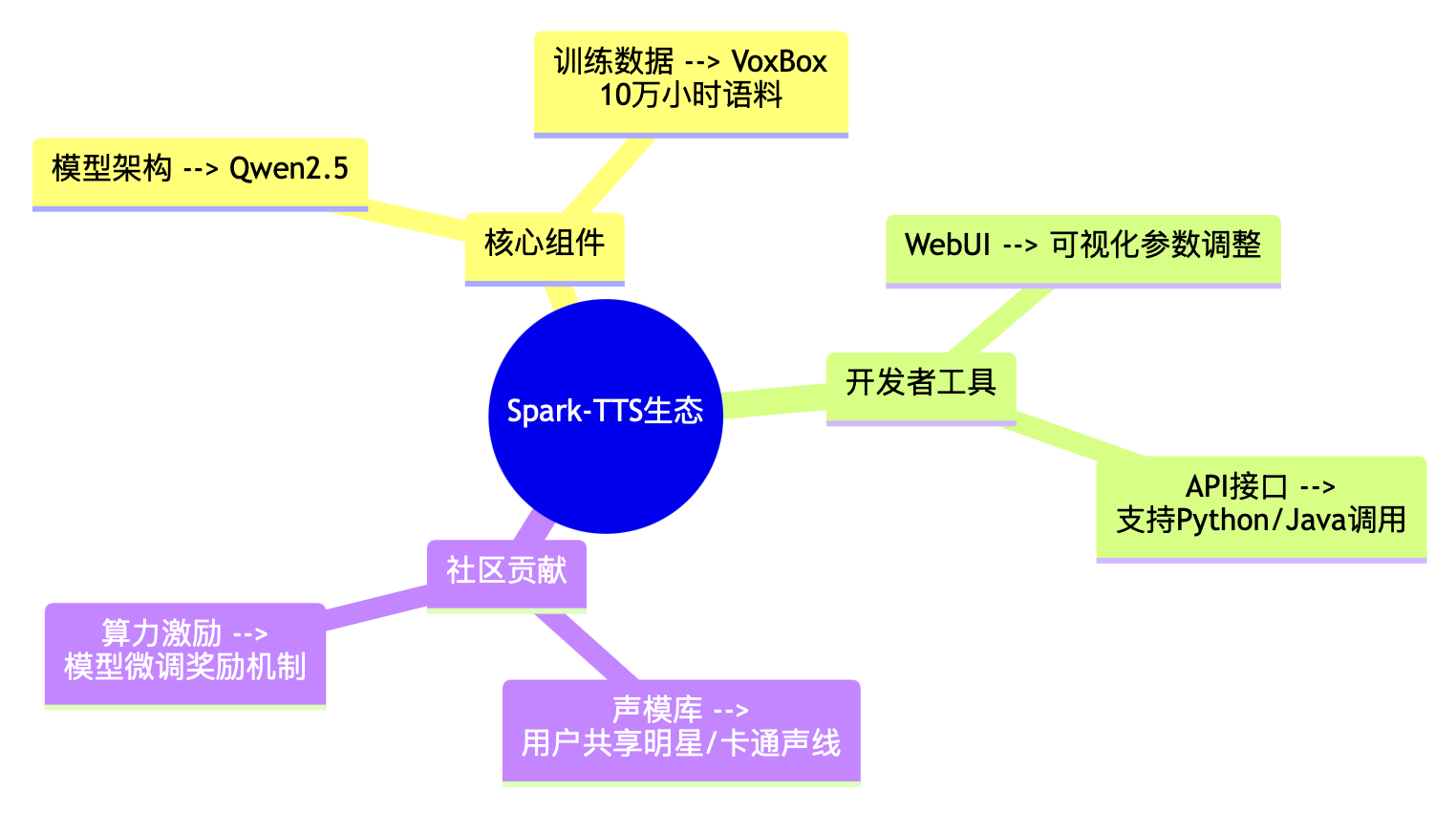
2. 快速部署指南
# 创建Conda环境
conda create -n sparktts python=3.12
conda activate sparktts
# 安装依赖库
pip install numpy librosa transformers huggingface_hub
# 下载预训练模型
python -c "from huggingface_hub import snapshot_download; snapshot_download('SparkAudio/Spark-TTS-0.5B')"
# 启动Web界面
python webui.py --device 0
注:M1/M2芯片需启用Metal加速
六、行业影响力与未来展望
• 技术突破:登上Hugging Face趋势榜TTS第二位
• 商业价值:某科技公司客服系统部署周期缩短80%
• 伦理挑战:社区建立声纹加密与使用授权机制



















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









