






我们来回顾下昨日技术进展,内容较多。
另外一个是,从MetaGPT、LangGraph看Agent记忆实现机制,以加强昨日关于Agent机记忆体的认识。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、从MetaGPT、LangGraph看Agent记忆实现机制
1、MetaGPT的记忆实现
在MetaGPT中,Memory类是智能体的记忆的抽象。当初始化时,Role初始化一个Memory对象作为self.rc.memory属性,它将在之后的_observe中存储每个Message,以便后续的检索。
memeory的实现地址在:https://github.com/geekan/MetaGPT/tree/main/metagpt/memory
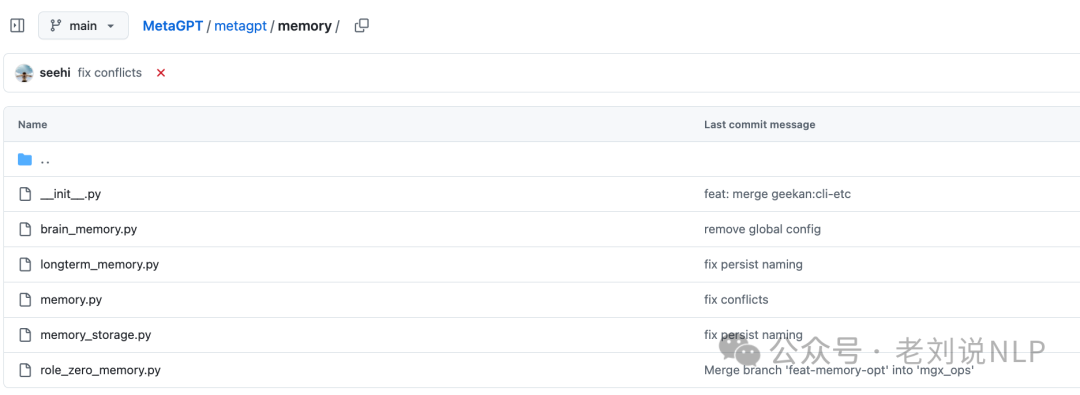
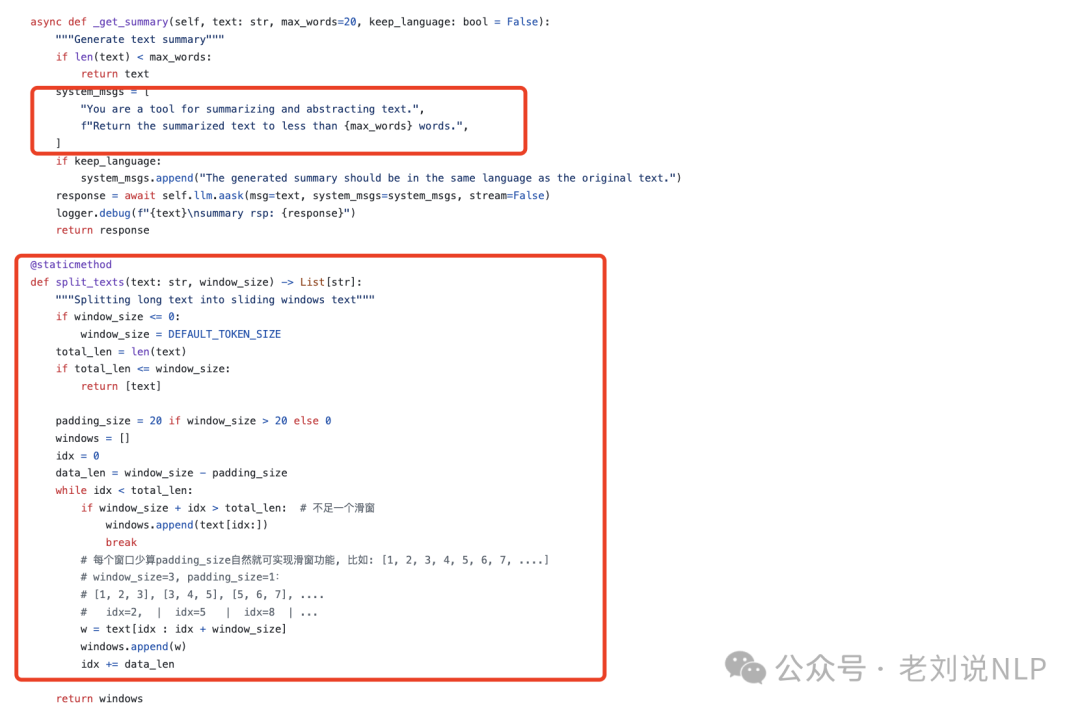
memory.py为基础的记忆类,用于存储和管理智能体的短期记忆。它通过一个列表storage来保存消息(Message对象),并提供了一系列接口来添加、删除、检索和清空记忆。例如:在memory.py中,记忆被存储为一个列表storage,其中每个元素是一个Message对象。该类提供了以下主要接口:add添加一条新的记忆,并更新索引以便快速检索;get_by_role:根据角色检索记忆;get_by_content根据内容关键字检索记忆;delete和clear删除特定记忆或清空所有记忆。这里用到windows滑窗口。
实现上基于Python列表(Message类队列)存储当前对话上下文,依赖大模型默认8K tokens窗口,通过LLM生成摘要压缩超长内容(如将50条消息压缩为10条关键点),引入滑动窗口淘汰旧消息,避免内存溢出。
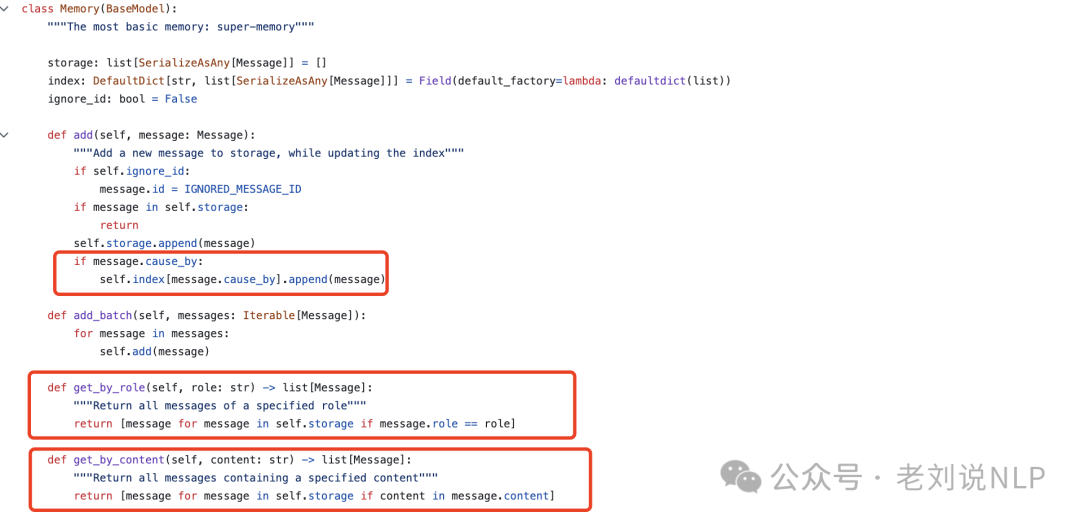
longterm_memory.py为长时记忆的实现,用于持久化存储智能体的记忆。它会在智能体启动时恢复记忆,并在记忆发生变化时更新存储,用的是embedding-faiss做存储召回。
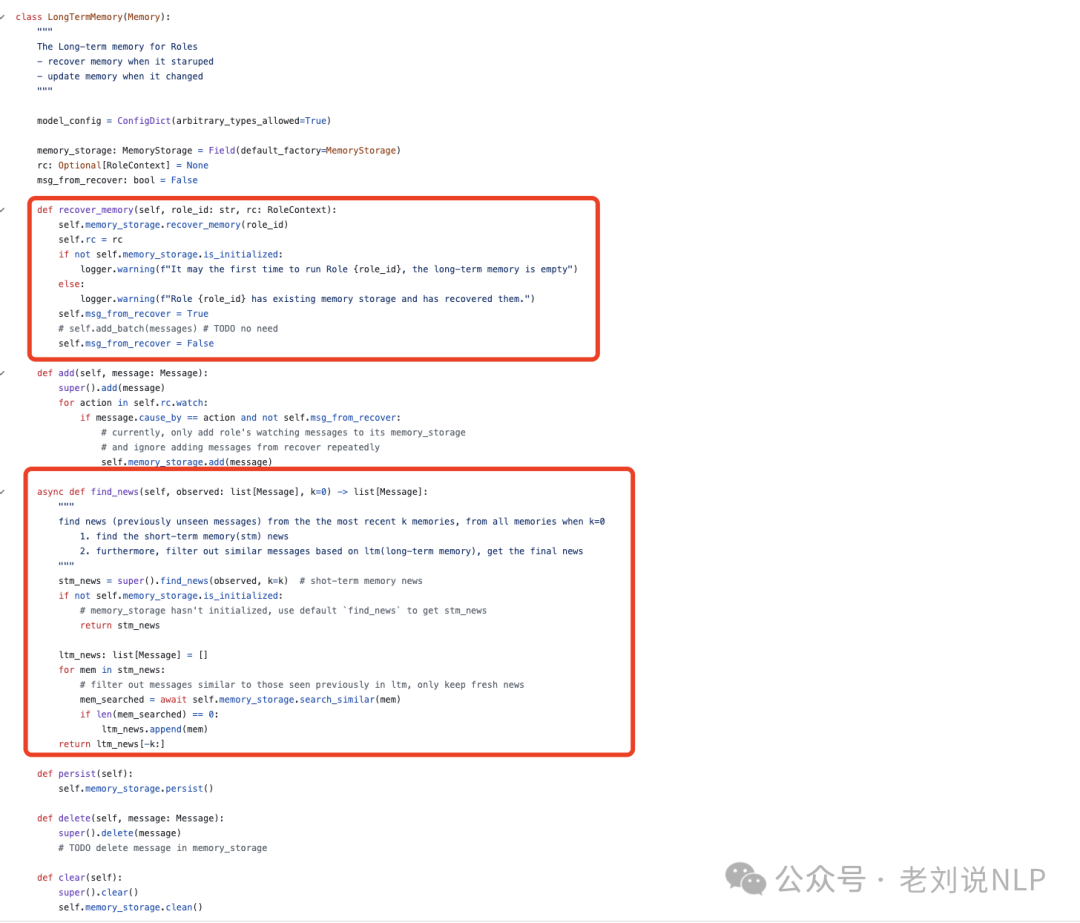
memory_storage.py辅助longterm_memory.py进行记忆的持久化存储和查询,持久化用的还是faiss。
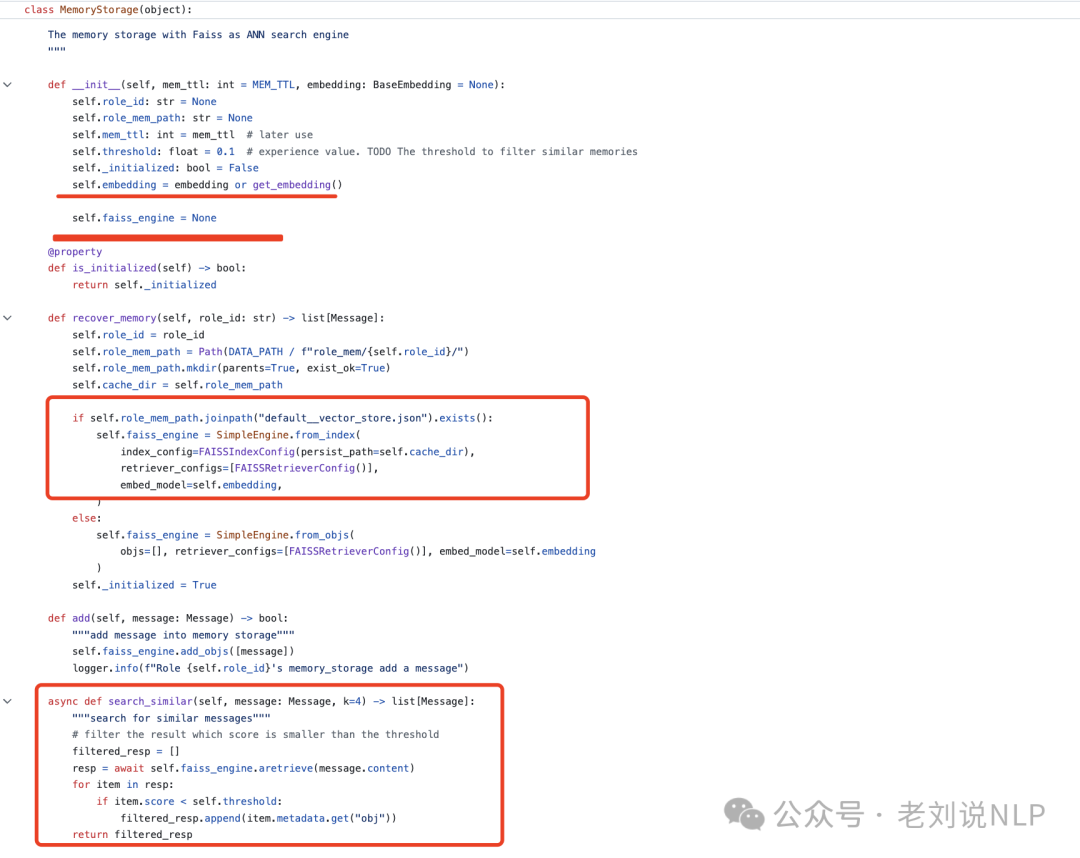
然后,在brain_memory.py,Used for long-term storage and automatic compression,采用Redis存储,并且里面有summary信息的步骤,将历史对话信息用大模型进行总结,然后存储到Redis里面,如果放Redis,那么其实就是为了加速用的,配合做短期索引用。
因此,综合如上,MetaGPT使用的是Redis, python-list,Faiss做的记忆存储,并且还用到了embedding嵌入以及llm做摘要。
详细的,看源码:https://docs.deepwisdom.ai/main/zh/guide/tutorials/use_memories.html,https://github.com/geekan/MetaGPT
2、LangGraph
LangGraph这个Agent架构核心在于理解如何将Agent的行为和状态管理通过图(Graph)的形式进行组织和协调,其通过StateGraph的概念,允许开发者定义一个状态对象,并通过节点(Nodes)和边(Edges)来管理状态的更新和流转,每个节点代表一个操作或步骤,边表示节点之间的依赖关系。
更进一步的:
State(状态)表示应用程序当前的快照,可以是任何Python类型,但通常是TypedDict或Pydantic BaseModel。
Nodes(节点)表示Python函数,接收当前状态作为输入,执行某些计算或副作用,并返回更新后的状态。
Edges(边)表示控制流规则,决定基于当前状态的下一个要执行的节点。可以是条件分支或固定过渡。
由于LangGraph支持并发处理多个任务,这意味着它可以同时处理多个用户请求或内部任务,而不会相互干扰。
所以,LangGraph为了做到状态隔离,每个线程(或任务)在LangGraph中都有其独立的状态。这种隔离确保了一个任务的状态变化不会影响到其他任务。
所以无论是短期记忆,还是长期记忆,围绕的都是线程做的。
LangGraph中短期记忆(Short-Term Memory)用于在对话过程中保持上下文,每次Graph被调用或一个步骤完成时,短期记忆会更新,并在每个步骤开始时被读取。短期记忆的实现通常涉及定义一个MemorySaver()对象,并在编译workflow时将其赋值给checkpointer。
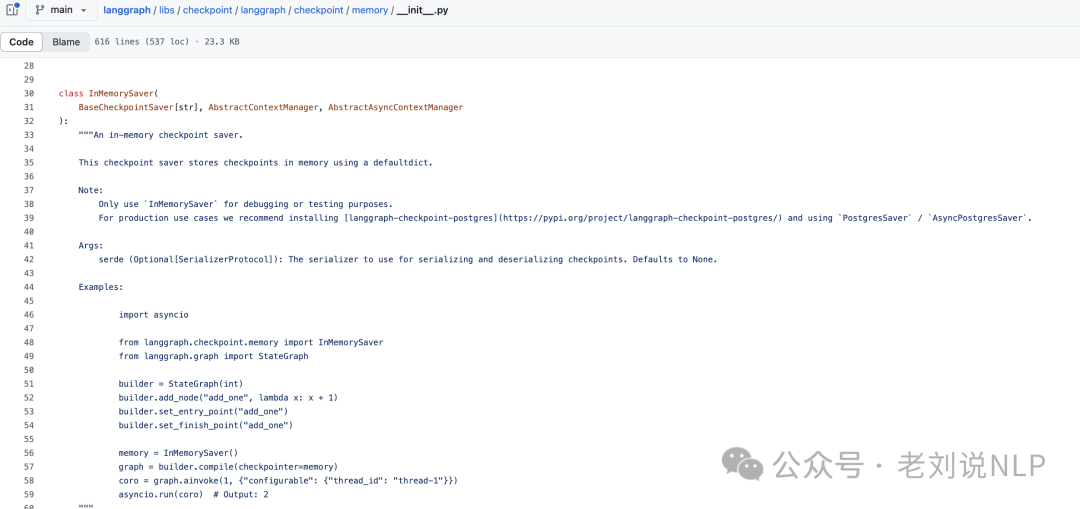
这些检查点(checkpoints)是对话状态的快照,checkpointer(https://github.com/langchain-ai/langgraph/tree/main/libs/checkpoint,https://github.com/langchain-ai/langgraph/blob/main/libs/checkpoint/langgraph/checkpoint/memory/init.py),会持久化到数据库中,以便在需要时恢复线程。

因此,这块的查找,就可以变成了图的查找方式,但是针对上下文越来越多的情况,也有几个花式对策,滑动窗口记忆,只保留最近的几轮对话,丢弃较早的历史记录,以控制内存占用;动态Token裁剪,根据模型的Token预算智能裁剪对话历史,保留最重要的信息。增量摘要记忆,定期生成对话的摘要,保留关键上下文脉络,同时减少冗余信息。,可以参见:https://langchain.com/langgraph
但是,这做的都是短时记忆,LangGraph本身不提供跨会话的长期记忆功能,如果开发者需要持久化存储记忆,可以引入特定的节点,用于将记忆和变量存入外部数据库,以便后续检索。,这样以来,faiss那些,也还需要用上。
这块的实践,可以参考:https://github.com/langchain-ai/langgraph/blob/main/docs/docs/how-tos/memory/manage-conversation-history.ipynb
二、老刘说NLP技术社区昨日技术进展回顾
【老刘说NLP20250323技术进展早报】围绕大模型微调工具ZO2、文档处理工具PdfCraft,claude-think-tool,Agent记忆,svg文本转图。qwen3-omni开源预测,及平日学习心得等话题,供各位参考。
1、关于大模型微调的轮子进展
传统的基于一阶优化器的方法(如SGD)在模型规模扩大时会显著增加内存。主要体现在计算和通信操作的多次重复,每次前向和后向传播都需要传输相同的参数数据,增加了通信量和延迟;每次通信操作的数据传输量大,前向和后向传播都需要传输参数和激活值,进一步增加了数据传输量。
一些工作尝试将CPU卸载技术引入LLM训练,但这些工作通常受限于一阶优化器的能力和有限的GPU内存,限制了大规模模型在单GPU系统上的可扩展性。

ZO2,在18GB GPU显存完成175B参数模型的全参数微调: https://github.com/liangyuwang/zo2,ZO2: Scalable Zeroth-Order Fine-Tuning for Extremely Large Language Models with Limited GPU Memory:https://https://arxiv.org/pdf/2503.12668可看技术实现原理。
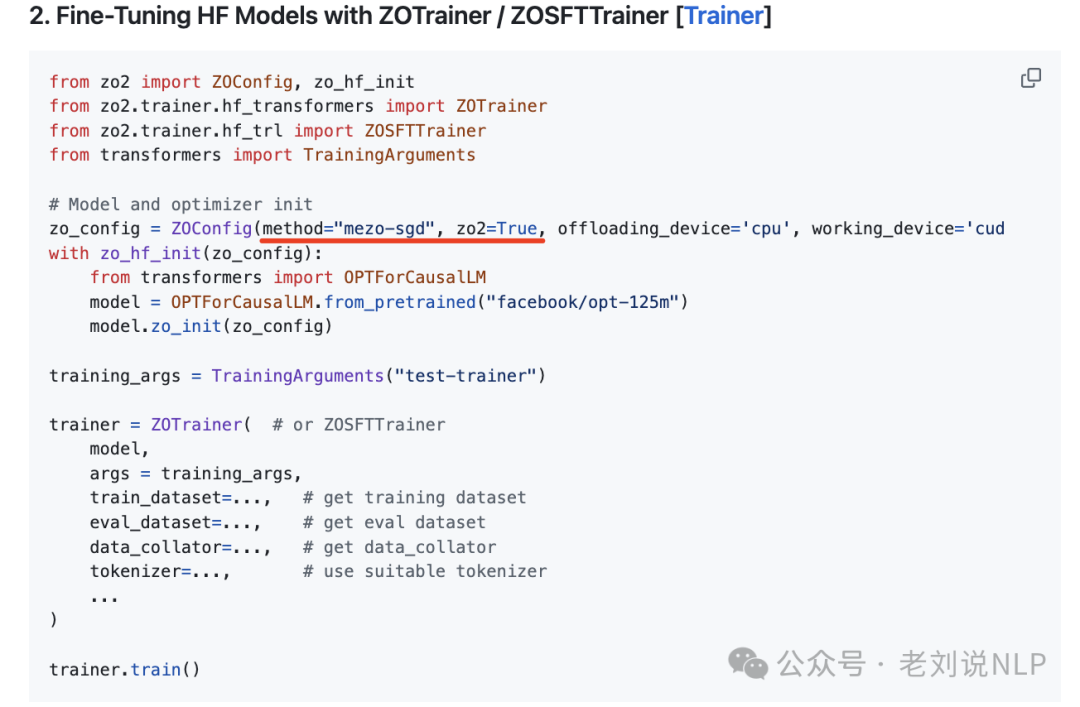
核心步骤如下:
通过使用双重前向传播来估计参数梯度,从而避免了传统方法中对后向传播的依赖,减少计算步骤。
双重前向传播方面利用双重前向传播来估计参数梯度。每个参数在前向传播中被扰动两次,分别计算正负扰动的损失,然后通过差分法近似梯度。
CPU卸载策略方面通过动态地将模型参数在CPU和GPU之间转移,优化计算流并最大化GPU利用率,包括仅在最后一次计算后将参数上传到GPU,减少通信频率通过异步任务管理策略,使计算和通信任务重叠,减少空闲时间,并在AMP模式下支持低位数精度(如bfloat16和float16),以减少数据传输量并加速计算参数在从GPU卸载到CPU时被压缩,上传回GPU时再解压缩。
2、关于文档处理的另一个轮子
文档处理的轮子越来越多,但很多都是换汤不换药,大多都是基于原有的模型组件在组装串一次,例如pdf-craft,将PDF按页读出,并使用DocLayout-YOLO(https://github.com/opendatalab/DocLayout-YOLO)版式分析加规则,将书页中的正文提取出来,并过滤掉页眉、页脚、脚注、页码等元素。在跨页过程中,使用算法判断以处理前后文跨页顺接问题,最终生成语义通顺的文本。书页使用OnnxOCR(https://github.com/jingsongliujing/OnnxOCR)进行文本识别,并使用layoutreader(https://github.com/ppaanngggg/layoutreader)做阅读顺序。

其中,有个点可以关注,其提到,如果要解析书籍(一般超过100页),建议将其转换为EPUB(https://en.wikipedia.org/wiki/EPUB)格式文件,为什么?会更快? 在转换过程中,此库会将本地OCR识别到的数据传递给LLM,并通过特定的信息(比如目录)构建书籍的结构,最终生成有目录和章节的EPUB文件,在这个解析和构建过程中,每页的注释和引用信息都会通过LLM读取,然后以新的格式呈现在EPUB文件中。另外LLM可以一定程度上纠正OCR的错误,这个可以理解,但是这块的目的不是很理解。
地址在:https://github.com/oomol-lab/pdf-craft
3、关于推理模型思考工具
《The "think" tool: Enabling Claude to stop and think in complex tool use situations》,“思考”工具让Claude在复杂的工具使用情况下停下来思考用于解决复杂问题。
工具的定义如下:

地址在:https://www.anthropic.com/engineering/claude-think-tool,基于这个概念,目前已经有一些实现,如:https://github.com/littleironwaltz/claude-think-tool
4、心得分享
多看一些开源项目的feishu、github、blog、issue,会比论文舒畅的多得多。并且会让自己很inner-peace。
但是这些链接地址,通常是需要我们自己去挖掘的,并不是直接等着喂饭。
例如,昨日天气燥热,出去看看花,回来还是烦躁。看看arxiv,是再也没好文章看了。索引看dify的代码跟feishu、github、blog、issue,慢慢地,心情就平复下来了。这种心得也分享给大家。如果你觉得很烦躁,静不下心来,你就去看书。
因为专注,所以深度,因为深度,所以有数,因为有数,所以不躇,因为不躇,所以满足。
5、关于Agent的记忆问题
从具体案例出发,看看Dify的知识库分段及召回逻辑设计,这个比看论文要踏实的多。dify提到的qa对生成逻辑,父子分段逻辑,这些都是很基础的,大家可以加深下印象。
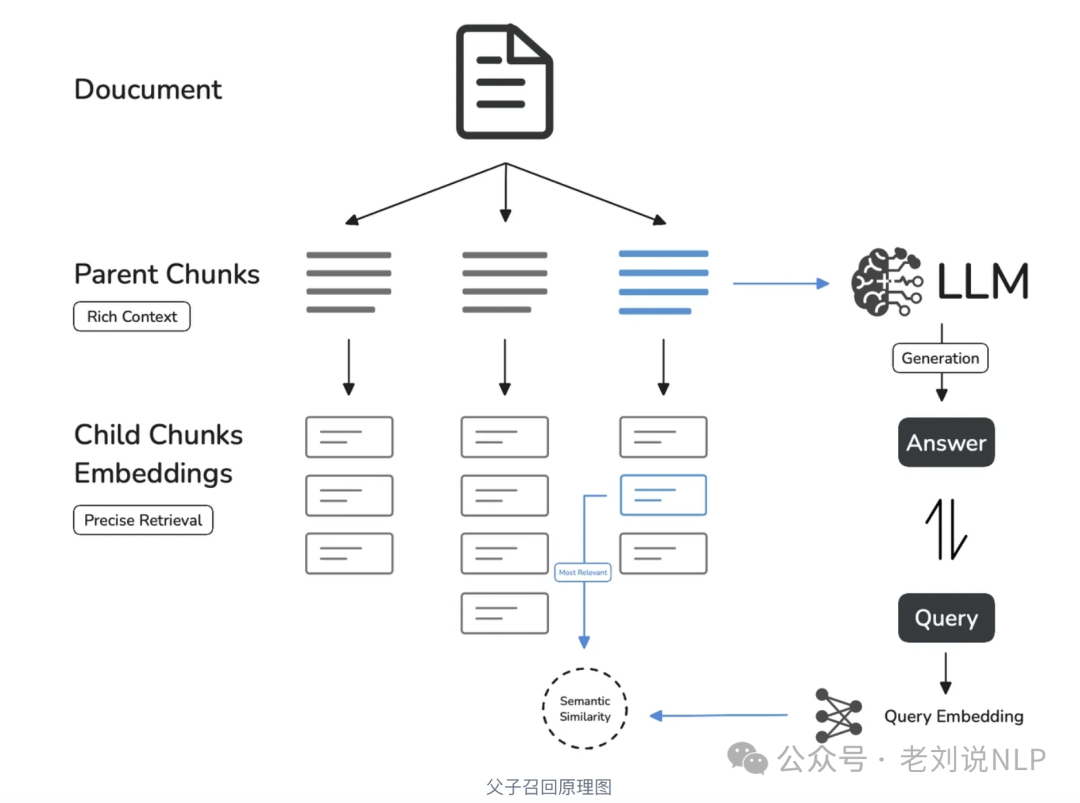
地址:https://mp.weixin.qq.com/s/WHBZqKPCtkyVBJpjG1oOXQ
6、Aent评估技术总结
《Survey on Evaluation of LLM-based Agents》, LLM智能体评估领域的最新进展,从能力评估、应用评估、通用评估和评估框架四个维度,系统地总结了现有评估方法、基准和工具。
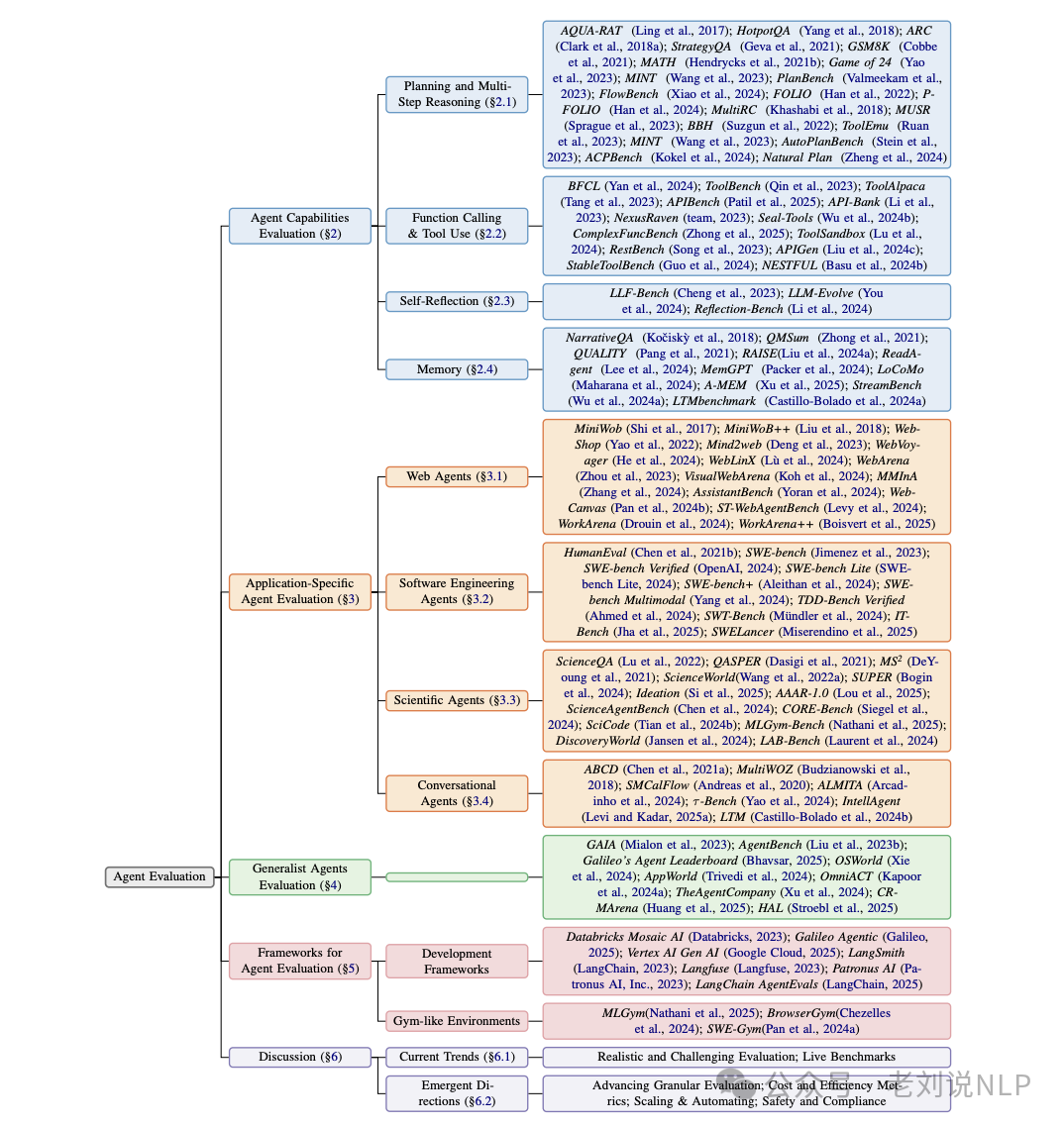
地址在:https://arxiv.org/pdf/2503.16416
7、关于agent记忆系统的技术总结
《A Survey on the Memory Mechanism of Large Language Model based Agents》,对Agent的记忆系统做了较为完整的技术总结,论文在:https://arxiv.org/pdf/2404.13501.pdf,地址在:https://github.com/nuster1128/LLM_Agent_Memory_Survey。实践,可以配合:https://modelscope-agent.readthedocs.io/zh-cn/latest/modules/memory.html
8、开源进展Qwen2.5-Omni-7B
千问目测还要发一个Qwen2.5-Omni-7B 模型,这是一个端到端的多模态模型,支持文本,图片,音频,视频作为输入,输出支持文本和语音
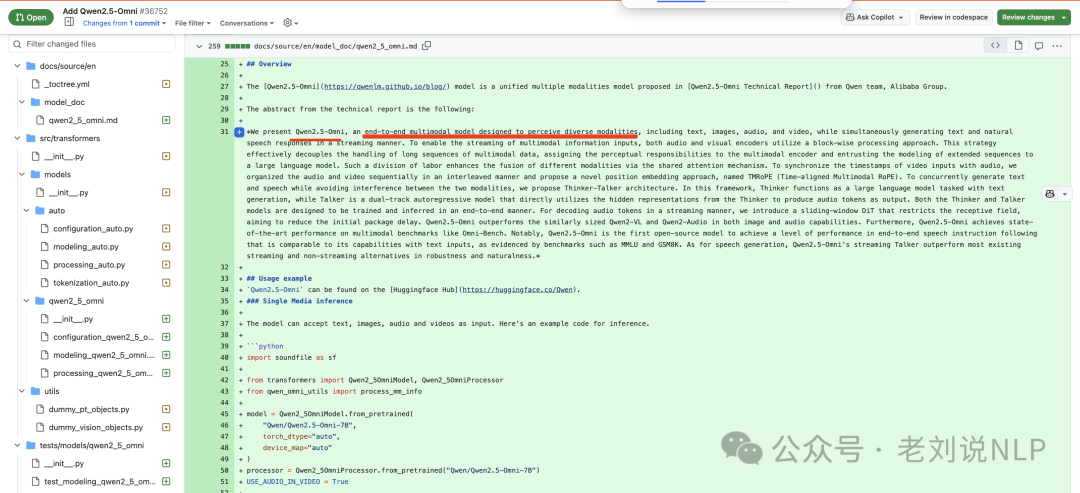
地址在:https://github.com/huggingface/transformers/pull/36752/commits/b4ff115375f02b59eb3e495c9dd3c1219e63ff50
9、关于AVG文转图应用
cvpr2025的工作,基于多模态大模型的SVG 代码生成器,将矢量化任务转换为代码生成任务,直接在SVG代码空间进行解析和生成。在架构上,采用多模态VLM(Vision-LanguageModel),能够处理图像和文本两种输入形式。

当输入图像时,模型会将其转换为视觉Token,并通过解码器生成相应的SVG代码。而当输入文本描述时,St直接根据指令生成符合语义的SVG代码。这使得模型不仅可以执行Image-to-SVG(图像转SVG),还可以进行Text-to-SVG(文本生成SVG)。

《StarVector: Generating Scalable Vector Graphics Code From Images And Text》,https://arxiv.org/pdf/2312.11556),https://starvector.github.io/

模型地址在:https://huggingface.co/starvector/starvector-1b-im2svg,https://huggingface.co/starvector/starvector-8b-im2svg;
数据地址在Lhttps://huggingface.co/collections/starvector/starvector-svg-datasets-svg-bench-67811204a76475be4dd66d09,https://huggingface.co/datasets/starvector/svg-stack;
github地址在:https://github.com/joanrod/star-vector
10、行业R1模型如何构建及减少推理大模型过度思考
之前说过很多R1用在多模态领域的工作,核心就是把多模态的数据进行文本化,然后蒸馏R1的推理路径做微调,或者在强化阶段引入一些个非文本模态的奖励,如IOU奖励。
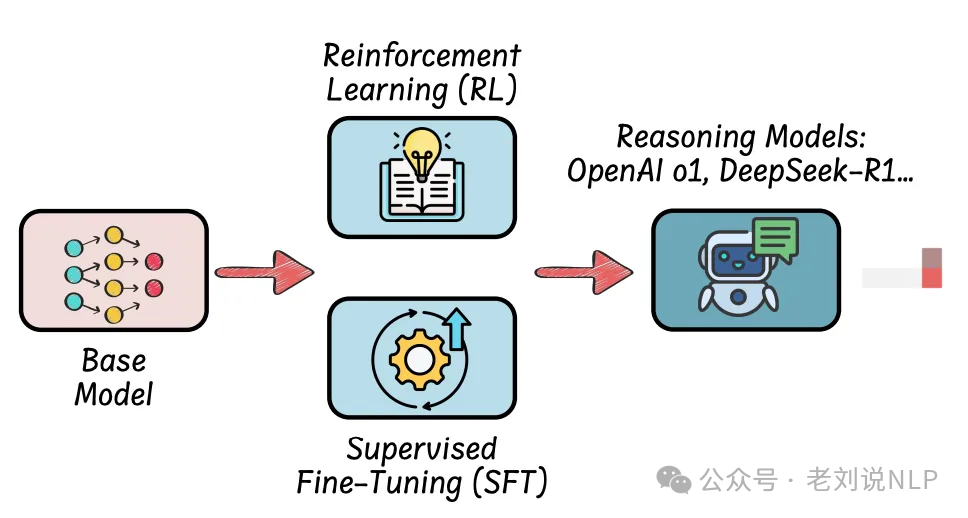
这次来说说用在垂直领域。现在这块的趋势,像极了23年清一色的领域微调模型一样,当时的路线是继续预训练(continue pretain)+微调(SFT),或者直接微调(SFT),这里的SFT大多是构造问题,然后蒸馏GTP4等强模型的答案,构成二元组数据(question, answer)。
R1出来之后,模式就变成了SFT(监督微调)、RL(强化学习)或两者的组合。但是这里的微调(SFT)使用的答案,从之前的答案,变成了加入思考轨迹的三元组,即(question, think, answer),被蒸馏对象变成了DeepseekR1或者GPT4-O1等。然后强化学习变成了GROP(大多都是准确性奖励和格式正确奖励两种)。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1298
1298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









