






环境情况
- ubuntu 18.04 → 20.04(最终)
- 安装Ubuntu1804虚拟机系统 + Anaconda:可参考我的另一篇文章
- Python 3.6.13 → 3.8(最终)
- Anaconda3-2021.05
目标识别:YOLOv5相关
- 1、安装git
sudo apt install git
- 2、使用以下代码来下载源码并直接安装:
git clone https://github.com/ultralytics/yolov5
- 3、配置YOLO v5的环境
cd yolov5
pip install -r requirements.txt
问题及解决
-
1、
fatal: unable to access- 错误显示:
(base) wjq@wjqUbuntu1804:~$ git clone https://github.com/ultralytics/yolov5 正克隆到 'yolov5'... fatal: unable to access 'https://github.com/ultralytics/yolov5/': gnutls_handshake() failed: The TLS connection was non-properly terminated.- 解决方式1:
- ①更新 Git:
sudo apt update sudo apt upgrade git - ②更新 CA 证书:
sudo apt install --reinstall ca-certificates
- ①更新 Git:
- 解决方式2:把命令行里的http改为git重新执行
-
2、
问题443- 解决途径的参考:https://blog.youkuaiyun.com/liubang00001/article/details/141334472
- 随意打开一个终端,输入一下代码安装软件包:
- 出现[y/n],均写y
sudo apt update sudo apt install openssh-server
- 出现[y/n],均写y
- 验证:
sudo systemctl status ssh,接着输入q可以返回命令行,于是可以重新
-
3、版本问题
- 问题:安装requirements.txt时很多版本找不到。
- 解决:可能是anaconda默认下载的Python版本太低,我碰上该问题时用Python3.6无法下载,在虚拟环境搭建Python3.8则可以使用。
创建虚拟环境
- 0、conda很慢时,可以换镜像源
- 通过命令行直接添加:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2/ conda config --set channel_priority strict - 1、尝试创建虚拟环境:
conda create -n py36 python=3.6.13 - 2、如果还是失败,可以尝试指定国内镜像加速
conda create -n py36 python=3.6.13 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main - 3、成功时
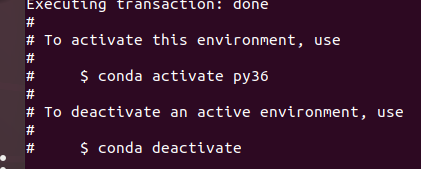
- 4、激活环境:
conda activate py36 - 5、返回到 base 环境:
conda activate base - 6、查看当前的活跃环境:
conda info --envs - 7、列出所有的 Conda 环境,当前激活的环境会有一个星号(*)标记。:
# conda environments: # base * /home/user/anaconda3 py36 /home/user/anaconda3/envs/py36
安装 PyTorch
- Python3.6对应下载:
pip install torch==1.10.0+cpu torchvision==0.11.1+cpu torchaudio==0.10.0+cpu -f https://download.pytorch.org/whl/torch_stable.html - 检查是否成功安装:
pip list | grep torch

VMware虚拟机中的Ubuntu识别不到摄像头
- 在Windows上识别得到外接摄像头,但ubuntu上识别不到
-
①关闭虚拟机,在Windows上启动该服务

- 此时在:虚拟机>可移动设备可见这些选项了
STEREOLABS ZED-2:这是一款完整的硬件设备,具备双目摄像头、深度传感器、IMU(惯性测量单元)、RGB 摄像头等,能够直接用于捕捉深度图像、视频流、环境映射、对象跟踪等。STEREOLABS ZED-2 HID INTERFACE:这是一个接口模式,主要用于支持 ZED-2 摄像头的通信。通过 HID 接口,摄像头和计算机之间可以通过标准 USB 连接进行数据传输,但 HID 本身并不具备图像采集和处理功能,它仅是作为摄像头与计算机的通讯桥梁。

-
②关闭虚拟机,打开“首选项”


-
查看清楚USB接口对应的都是什么设备
ls -l /dev/video* lsusb
-
如果以上选中后仍无法识别,可按序完成如下参考方法:
-
最后连接上摄像头的效果(本处采用的是双目相机)
- 安装chesse:
sudo apt-get install cheese - 开启ubuntu的茄子相机:
cheese

- 安装chesse:
-
安装yolov5期间的问题总结
-
问题1:识别不到摄像头(解决如上)
-
问题2:库等不匹配相关问题
-
不匹配1:yolov5 要求的是 torchvision 0.9.1
- 解决:
# S1.卸载当前torchvision 版本 pip uninstall torchvision # S2.安装正确版本的 torchvision pip install torchvision==0.9.1 # S3.确认 torch 版本是否匹配 python -c "import torch; print(torch.__version__)" # S4.如果当前版本与 YOLOv5 要求的不匹配,安装兼容版本 pip install torch==1.8.1 # S5.检查依赖是否正确 pip install -r requirements.txt
- 解决:
-
不匹配2:YOLOv5 需要版本 >=2.2 的 tensorboard
- 解决:
# S1.安装或更新 tensorboard 到合适的版本: pip install tensorboard>=2.2 # 如果你已经安装了 tensorboard,可以通过以下命令检查版本: pip show tensorboard # S2.确保安装所有依赖 pip install -r requirements.txt # S3.再次运行 python detect.py
- 解决:
-
不匹配3:opencv-python版本不匹配
- YOLOv5 要求的是 opencv-python==4.5.2.54。
- 解决
# S1.卸载当前的 opencv-python 版本 pip uninstall opencv-python # S2.安装所需版本 pip install opencv-python==4.5.2.54 # S3.再次运行 python detect.py
-
插曲:不匹配1-3都是由于虚拟环境切换错了,所以导致库匹配出了很多问题(吃一堑:虚拟环境名要区别好,运行前要多留心虚拟环境对不对)
-
-
问题3:yolov5中模型不够新。
- 由于py38对应的是改动过的yolov5_stereo_Pro,所以包中的模型yolov5s有点问题。
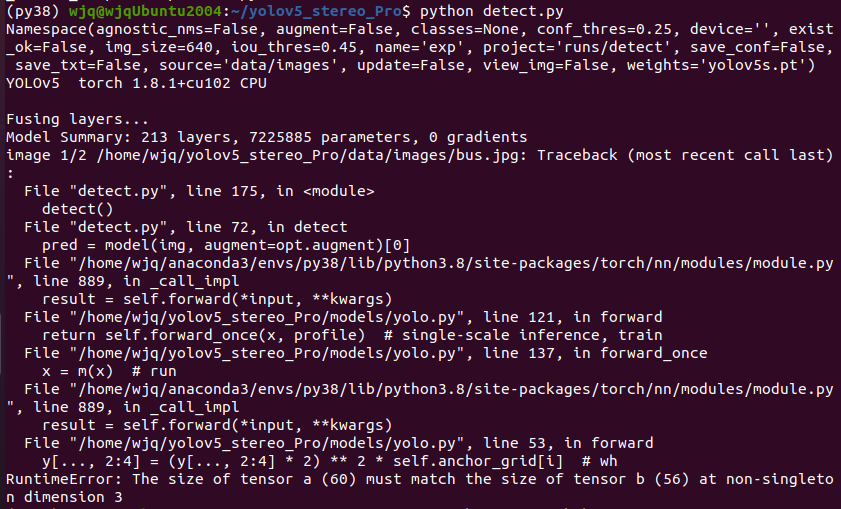
- 解决:重新下载官方权重
wget https://github.com/ultralytics/yolov5/releases/download/v6.0/yolov5s.pt
- 由于py38对应的是改动过的yolov5_stereo_Pro,所以包中的模型yolov5s有点问题。
-
问题4:输入图片尺寸不匹配代码
- 解决:
- 使用 v4l2-ctl 命令查看虚拟机当前连接的摄像头所拍摄图片的分辨率是多少
# 安装 v4l-utils(如果未安装) sudo apt update sudo apt install v4l-utils # 查看连接的摄像头设备: v4l2-ctl --list-devices # 输出中如“/dev/video0”,即是你的摄像头设备 # 查看当前摄像头分辨率: v4l2-ctl --device=/dev/video0 --get-fmt-video # 列出当前摄像头所有支持的分辨率 v4l2-ctl --device=/dev/video0 --list-formats-ext - (#暂缓,先换用笔记本自带摄像头测试yolov5的安装情况,后续再进一步修改匹配ZED2双目相机的代码)
- 使用 v4l2-ctl 命令查看虚拟机当前连接的摄像头所拍摄图片的分辨率是多少
- 解决:
-
问题5:模型文件(yolov5s.pt)的结构和代码不匹配
- 主要是 缺少 SPPF 模块的定义,SPPF是YOLOv5 v6.0 及之后版本新增的模块,用于提高检测速度和精度。原先代码可能是基于旧版本 YOLOv5,而下载的权重文件是基于新版本模型结构。

- 解决:由于我不想更新代码(为了让yolov5匹配后续结合双目相机),故尝试使用旧版本的权重(不包含 SPPF 的版本)
# 回退模型权重 wget https://github.com/ultralytics/yolov5/releases/download/v5.0/yolov5s.pt -O yolov5s.pt # 再运行 python detect.py --source 0
- 主要是 缺少 SPPF 模块的定义,SPPF是YOLOv5 v6.0 及之后版本新增的模块,用于提高检测速度和精度。原先代码可能是基于旧版本 YOLOv5,而下载的权重文件是基于新版本模型结构。
-
问题6:摄像头又连不上了
-
原因:采用ctrl+z退出摄像头,导致进程被挂起,使得原先分配摄像头的source 0被挂起,摄像头因此被轮分配给source 1了。
-
解决
# 查看后台挂起的任务 jobs # 输出类似: # [1]+ Stopped python detect.py --source 0 # 恢复到前台(%1 对应任务编号) fg %1 # 如果不想恢复,直接终止挂起进程 kill %1 -
把两次ctrl+z挂起的进程鲨掉之后,重新在可移动设备断开后再连接,即可重新给摄像头分配source 0了。

-
恢复后,按 Ctrl + C退出,不要用
ctrl+z退出了
-
-
摄像头匹配+yolov5安装成功后:

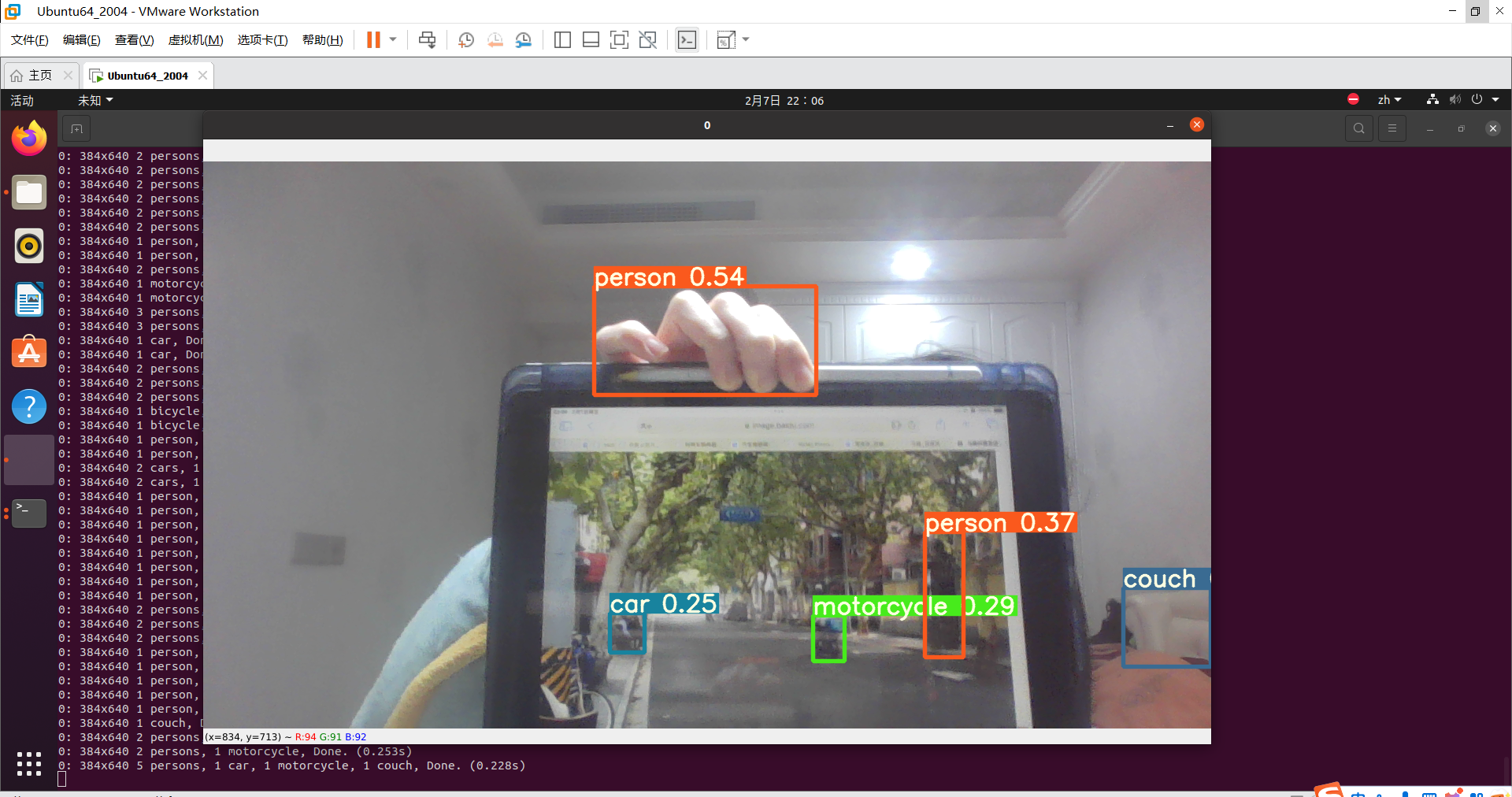

双目测距相关
点云图:采用pcl生成
- 安装cpp_pcl库的参考
- 安装Python_pcl的参考
- 参考1
- 参考2
- 参考3:最后通过这个解决,注意该文章里提供法2Anaconda的路径是base下的,记得要切换成自己的虚拟环境
- 如我的虚拟环境是yl8,则在anaconda中的envs文件夹下找到虚拟环境,法2最终改成
mv pcl /home/aliez/anaconda3/envs/yl8/lib/python3.8/site-packages,另一句同理
- 如我的虚拟环境是yl8,则在anaconda中的envs文件夹下找到虚拟环境,法2最终改成
- 安装pcl的过程中,遇到的其他问题
- 虚拟机磁盘不够了,扩展磁盘+重新划分内存
- 磁盘扩容后,虚拟机重启进不去:先Windows主机重启后,再参考如下两个文章处理

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









