






目录
4.3.1使用pytorch的预定义算子来重新实现二分类任务。
4.3.2 增加一个3个神经元的隐藏层,再次实现二分类,并与4.3.1做对比。
4.3.3 自定义隐藏层层数和每个隐藏层中的神经元个数,尝试找到最优超参数完成二分类。
4.3 自动梯度计算
构建深度学习模型的基本流程就是:搭建计算图,求得损失函数,然后计算损失函数对模型参数的导数,再利用梯度下降法等方法来更新参数。搭建计算图的过程,称为“正向传播”,这个是需要我们自己动手的,因为我们需要设计我们模型的结构。由损失函数求导的过程,称为“反向传播”,求导是件辛苦事儿,所以自动求导基本上是各种深度学习框架的基本功能和最重要的功能之一,PyTorch也不例外。
autograd 包的第一个核心类是Tensor,如果将其属性 “.requires_grad” 设置为True,它将开始追踪(track)在其上的所有操作(意味着可以利用链式法则进行梯度传播)。完成计算后,调用函数“.backward()”完成所有梯度计算。此Tensor的体积将会累计到属性“.grad”中。
【注意:在y.backward()时,如果y是标量,则不需要为backward()传入任何参数,否则,需要传入一个与y同形状的Tensor。】
4.3.1使用pytorch的预定义算子来重新实现二分类任务。
4.3.1.1 实现前馈神经网络模型
首先是创建类model并继承torch.nn.Module,调用父类的初始化函数,重写forward函数,其实就是把之前执行执行的步骤封装在函数里,然后重写backford方法使用pass不改变原操作,随后创建model实例,在前向学习的时候调用model,接受返回值pred
class Model_MLP_L2_V2(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Model_MLP_L2_V2, self).__init__()
# 使用'torch.nn.Linear'定义线性层。
# 其中第一个参数(in_features)为线性层输入维度;第二个参数(out_features)为线性层输出维度
# weight为权重参数属性,这里使用'torch.nn.init.normal_'进行随机高斯分布初始化
# bias为偏置参数属性,这里使用'torch.nn.init.constant_'进行常量初始化
self.fc1 = nn.Linear(input_size, hidden_size)
normal_(tensor=self.fc1.weight,mean=0.,std=1.)
constant_(tensor=self.fc1.bias,val=0.0)
self.fc2 = nn.Linear(hidden_size, output_size)
normal_(tensor=self.fc2.weight, mean=0., std=1.)
constant_(tensor=self.fc2.bias, val=0.0)
# 使用'torch.nn.functional.sigmoid'定义 Logistic 激活函数
self.act_fn = F.sigmoid
# 前向计算
def forward(self, inputs):
z1 = self.fc1(inputs)
a1 = self.act_fn(z1)
z2 = self.fc2(a1)
a2 = self.act_fn(z2)
return a24.3.1.2 完善Runner类
基于上一节实现的 RunnerV2_1 类,本节的 RunnerV2_2 类在训练过程中使用自动梯度计算;模型保存时,使用state_dict方法获取模型参数;模型加载时,使用load_state_dict方法加载模型参数.
class RunnerV2_2(object):
def __init__(self, model, optimizer, metric, loss_fn, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric
# 记录训练过程中的评估指标变化情况
self.train_scores = []
self.dev_scores = []
# 记录训练过程中的评价指标变化情况
self.train_loss = []
self.dev_loss = []
def train(self, train_set, dev_set, **kwargs):
# 将模型切换为训练模式
self.model.train()
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_epochs = kwargs.get("log_epochs", 100)
# 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams"
save_path = kwargs.get("save_path", "best_model.pdparams")
# log打印函数,如果没有传入则默认为"None"
custom_print_log = kwargs.get("custom_print_log", None)
# 记录全局最优指标
best_score = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
X, y = train_set
# 获取模型预测
logits = self.model(X)
# 计算交叉熵损失
trn_loss = self.loss_fn(logits, y)
self.train_loss.append(trn_loss.item())
# 计算评估指标
trn_score = self.metric(logits, y).item()
self.train_scores.append(trn_score)
# 自动计算参数梯度
trn_loss.backward()
if custom_print_log is not None:
# 打印每一层的梯度
custom_print_log(self)
# 参数更新
self.optimizer.step()
# 清空梯度
self.optimizer.zero_grad()
dev_score, dev_loss = self.evaluate(dev_set)
# 如果当前指标为最优指标,保存该模型
if dev_score > best_score:
self.save_model(save_path)
print(f"[Evaluate] best accuracy performence has been updated: {best_score:.5f} --> {dev_score:.5f}")
best_score = dev_score
if log_epochs and epoch % log_epochs == 0:
print(f"[Train] epoch: {epoch}/{num_epochs}, loss: {trn_loss.item()}")
# 模型评估阶段,使用'torch.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def evaluate(self, data_set):
# 将模型切换为评估模式
self.model.eval()
X, y = data_set
# 计算模型输出
logits = self.model(X)
# 计算损失函数
loss = self.loss_fn(logits, y).item()
self.dev_loss.append(loss)
# 计算评估指标
score = self.metric(logits, y).item()
self.dev_scores.append(score)
return score, loss
# 模型测试阶段,使用'torch.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def predict(self, X):
# 将模型切换为评估模式
self.model.eval()
return self.model(X)
# 使用'model.state_dict()'获取模型参数,并进行保存
def save_model(self, saved_path):
torch.save(self.model.state_dict(), saved_path)
# 使用'model.set_state_dict'加载模型参数
def load_model(self, model_path):
state_dict = torch.load(model_path)
self.model.load_state_dict(state_dict)4.3.1.3 模型训练
实例化RunnerV2类,并传入训练配置,代码实现如下:
from metric import accuracy
from dataset import make_moons
n_samples = 1000
X, y = make_moons(n_samples=n_samples, shuffle=True, noise=0.15)
num_train = 640
num_dev = 160
num_test = 200
X_train, y_train = X[:num_train], y[:num_train]
X_dev, y_dev = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
X_test, y_test = X[num_train + num_dev:], y[num_train + num_dev:]
y_train = y_train.reshape([-1,1])
y_dev = y_dev.reshape([-1,1])
y_test = y_test.reshape([-1,1])
# 设置模型
input_size = 2
hidden_size = 5
output_size = 1
model = Model_MLP_L2_V2(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# 设置损失函数
loss_fn = F.binary_cross_entropy
# 设置优化器
learning_rate = 0.2
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
# 设置评价指标
metric = accuracy
# 其他参数
epoch_num = 1000
saved_path = 'best_model.pdparams'
# 实例化RunnerV2类,并传入训练配置
runner = RunnerV2_2(model, optimizer, metric, loss_fn)
runner.train([X_train, y_train], [X_dev, y_dev], num_epochs=epoch_num, log_epochs=50, save_path="best_model.pdparams")[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.55000
[Train] epoch: 0/1000, loss: 0.672812819480896
[Evaluate] best accuracy performence has been updated: 0.55000 --> 0.56250
[Evaluate] best accuracy performence has been updated: 0.56250 --> 0.57500
[Evaluate] best accuracy performence has been updated: 0.57500 --> 0.58125
[Evaluate] best accuracy performence has been updated: 0.58125 --> 0.59375
[Evaluate] best accuracy performence has been updated: 0.59375 --> 0.60000
[Evaluate] best accuracy performence has been updated: 0.60000 --> 0.61250
[Evaluate] best accuracy performence has been updated: 0.61250 --> 0.61875
[Evaluate] best accuracy performence has been updated: 0.61875 --> 0.62500
[Evaluate] best accuracy performence has been updated: 0.62500 --> 0.63750
[Evaluate] best accuracy performence has been updated: 0.63750 --> 0.64375
[Evaluate] best accuracy performence has been updated: 0.64375 --> 0.65000
[Evaluate] best accuracy performence has been updated: 0.65000 --> 0.65625
[Evaluate] best accuracy performence has been updated: 0.65625 --> 0.66250
[Evaluate] best accuracy performence has been updated: 0.66250 --> 0.67500
[Evaluate] best accuracy performence has been updated: 0.67500 --> 0.68125
[Evaluate] best accuracy performence has been updated: 0.68125 --> 0.68750
[Evaluate] best accuracy performence has been updated: 0.68750 --> 0.69375
[Evaluate] best accuracy performence has been updated: 0.69375 --> 0.70000
[Evaluate] best accuracy performence has been updated: 0.70000 --> 0.70625
[Evaluate] best accuracy performence has been updated: 0.70625 --> 0.71250
[Evaluate] best accuracy performence has been updated: 0.71250 --> 0.71875
[Evaluate] best accuracy performence has been updated: 0.71875 --> 0.72500
[Evaluate] best accuracy performence has been updated: 0.72500 --> 0.73125
[Evaluate] best accuracy performence has been updated: 0.73125 --> 0.73750
[Train] epoch: 50/1000, loss: 0.5244487524032593
[Evaluate] best accuracy performence has been updated: 0.73750 --> 0.74375
[Evaluate] best accuracy performence has been updated: 0.74375 --> 0.75000
[Evaluate] best accuracy performence has been updated: 0.75000 --> 0.75625
[Evaluate] best accuracy performence has been updated: 0.75625 --> 0.76250
[Evaluate] best accuracy performence has been updated: 0.76250 --> 0.76875
[Evaluate] best accuracy performence has been updated: 0.76875 --> 0.77500
[Evaluate] best accuracy performence has been updated: 0.77500 --> 0.78125
[Train] epoch: 100/1000, loss: 0.44568243622779846
[Evaluate] best accuracy performence has been updated: 0.78125 --> 0.78750
[Evaluate] best accuracy performence has been updated: 0.78750 --> 0.79375
[Evaluate] best accuracy performence has been updated: 0.79375 --> 0.80000
[Evaluate] best accuracy performence has been updated: 0.80000 --> 0.80625
[Evaluate] best accuracy performence has been updated: 0.80625 --> 0.81250
[Evaluate] best accuracy performence has been updated: 0.81250 --> 0.81875
[Train] epoch: 150/1000, loss: 0.39583656191825867
[Evaluate] best accuracy performence has been updated: 0.81875 --> 0.82500
[Evaluate] best accuracy performence has been updated: 0.82500 --> 0.83125
[Evaluate] best accuracy performence has been updated: 0.83125 --> 0.83750
[Evaluate] best accuracy performence has been updated: 0.83750 --> 0.84375
[Evaluate] best accuracy performence has been updated: 0.84375 --> 0.85000
[Train] epoch: 200/1000, loss: 0.3631165325641632
[Evaluate] best accuracy performence has been updated: 0.85000 --> 0.85625
[Evaluate] best accuracy performence has been updated: 0.85625 --> 0.86250
[Evaluate] best accuracy performence has been updated: 0.86250 --> 0.86875
[Train] epoch: 250/1000, loss: 0.34118399024009705
[Evaluate] best accuracy performence has been updated: 0.86875 --> 0.87500
[Evaluate] best accuracy performence has been updated: 0.87500 --> 0.88125
[Evaluate] best accuracy performence has been updated: 0.88125 --> 0.88750
[Train] epoch: 300/1000, loss: 0.3262239098548889
[Train] epoch: 350/1000, loss: 0.31585538387298584
[Train] epoch: 400/1000, loss: 0.3085569739341736
[Train] epoch: 450/1000, loss: 0.3033401072025299
[Train] epoch: 500/1000, loss: 0.2995539605617523
[Train] epoch: 550/1000, loss: 0.2967640161514282
[Train] epoch: 600/1000, loss: 0.29467660188674927
[Train] epoch: 650/1000, loss: 0.293090283870697
[Train] epoch: 700/1000, loss: 0.2918652892112732
[Train] epoch: 750/1000, loss: 0.29090332984924316
[Train] epoch: 800/1000, loss: 0.29013437032699585
[Train] epoch: 850/1000, loss: 0.28950807452201843
[Train] epoch: 900/1000, loss: 0.2889878451824188
[Train] epoch: 950/1000, loss: 0.2885465621948242
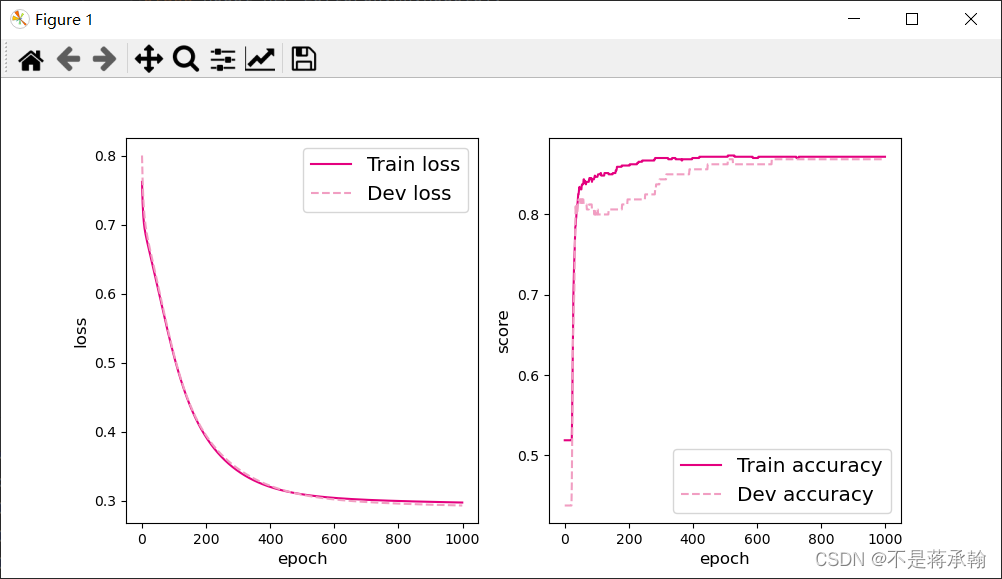
将训练过程中训练集与验证集的准确率变化情况进行可视化。
import matplotlib.pyplot as plt
# 可视化观察训练集与验证集的指标变化情况
def plot(runner, fig_name):
plt.figure(figsize=(10, 5))
epochs = [i for i in range(len(runner.train_scores))]
plt.subplot(1, 2, 1)
plt.plot(epochs, runner.train_loss, color='#e4007f', label="Train loss")
plt.plot(epochs, runner.dev_loss, color='#f19ec2', linestyle='--', label="Dev loss")
# 绘制坐标轴和图例
plt.ylabel("loss", fontsize='large')
plt.xlabel("epoch", fontsize='large')
plt.legend(loc='upper right', fontsize='x-large')
plt.subplot(1, 2, 2)
plt.plot(epochs, runner.train_scores, color='#e4007f', label="Train accuracy")
plt.plot(epochs, runner.dev_scores, color='#f19ec2', linestyle='--', label="Dev accuracy")
# 绘制坐标轴和图例
plt.ylabel("score", fontsize='large')
plt.xlabel("epoch", fontsize='large')
plt.legend(loc='lower right', fontsize='x-large')
plt.savefig(fig_name)
plt.show()
plot(runner, 'fw-acc.pdf')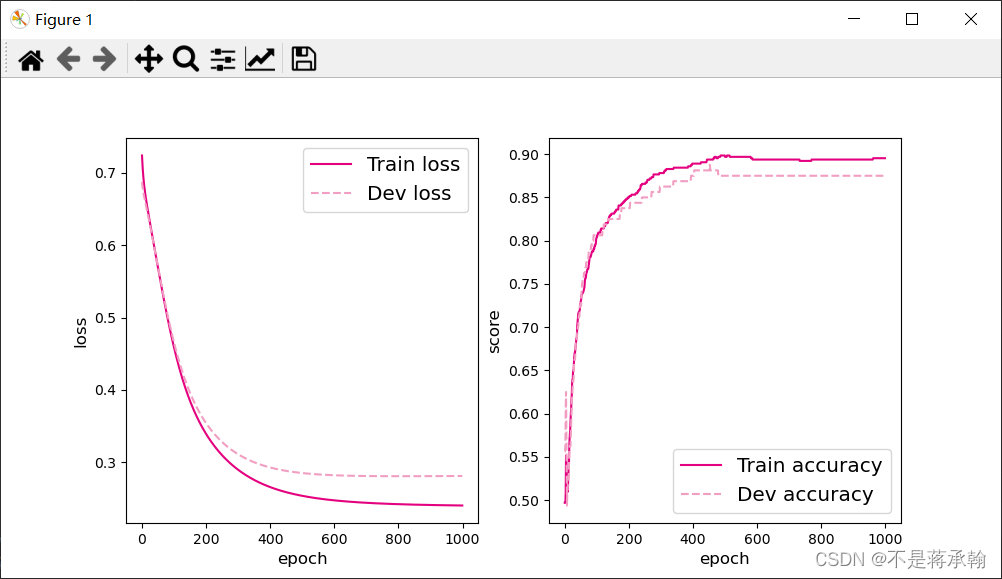
4.3.1.4 性能评价
使用测试数据对训练完成后的最优模型进行评价,观察模型在测试集上的准确率以及loss情况。代码如下:
# 模型评价
runner.load_model("best_model.pdparams")
score, loss = runner.evaluate([X_test, y_test])
print("[Test] score/loss: {:.4f}/{:.4f}".format(score, loss))
[Test] score/loss: 0.8850/0.2583
4.3.2 增加一个3个神经元的隐藏层,再次实现二分类,并与4.3.1做对比。
4.3.2.1 构建两个隐藏层神经网络模型
class Model_MLP_L5(torch.nn.Module):
def __init__(self, input_size, output_size,mean_init=0.,std_init=1.,b_init=0.0):
super(Model_MLP_L5, self).__init__()
self.fc1 = torch.nn.Linear(input_size, 3)
normal_(tensor=self.fc1.weight, mean=mean_init, std=std_init)
constant_(tensor=self.fc1.bias, val=b_init)
self.fc2 = torch.nn.Linear(3, 3)
normal_(tensor=self.fc2.weight, mean=mean_init, std=std_init)
constant_(tensor=self.fc2.bias, val=b_init)
self.fc3 = torch.nn.Linear(3, output_size)
normal_(tensor=self.fc3.weight, mean=mean_init, std=std_init)
constant_(tensor=self.fc3.bias, val=b_init)
# 使用'torch.nn.functional.sigmoid'定义 Logistic 激活函数
self.act = F.sigmoid
# 前向计算
def forward(self, inputs):
outputs = self.fc1(inputs)
outputs = self.act(outputs)
outputs = self.fc2(outputs)
outputs = self.act(outputs)
outputs = self.fc3(outputs)
outputs = self.act(outputs)
return outputs4.3.2.2 模型训练
# 设置模型
input_size = 2
output_size = 1
model = Model_MLP_L5(input_size=input_size, output_size=output_size)
# 设置损失函数
loss_fn = F.binary_cross_entropy
# 设置优化器
learning_rate = 0.2
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
# 设置评价指标
metric = accuracy
# 其他参数
epoch_num = 1000
saved_path = 'best_model.pdparams'
# 实例化RunnerV2类,并传入训练配置
runner = RunnerV2_2(model, optimizer, metric, loss_fn)
runner.train([X_train, y_train], [X_dev, y_dev], num_epochs=epoch_num, log_epochs=50, save_path="best_model.pdparams")[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.51875
[Train] epoch: 0/1000, loss: 0.89256751537323
[Evaluate] best accuracy performence has been updated: 0.51875 --> 0.55000
[Evaluate] best accuracy performence has been updated: 0.55000 --> 0.56250
[Evaluate] best accuracy performence has been updated: 0.56250 --> 0.57500
[Evaluate] best accuracy performence has been updated: 0.57500 --> 0.61875
[Evaluate] best accuracy performence has been updated: 0.61875 --> 0.64375
[Evaluate] best accuracy performence has been updated: 0.64375 --> 0.65000
[Evaluate] best accuracy performence has been updated: 0.65000 --> 0.65625
[Evaluate] best accuracy performence has been updated: 0.65625 --> 0.68125
[Evaluate] best accuracy performence has been updated: 0.68125 --> 0.68750
[Evaluate] best accuracy performence has been updated: 0.68750 --> 0.70625
[Evaluate] best accuracy performence has been updated: 0.70625 --> 0.72500
[Train] epoch: 50/1000, loss: 0.6718729734420776
[Evaluate] best accuracy performence has been updated: 0.72500 --> 0.73125
[Evaluate] best accuracy performence has been updated: 0.73125 --> 0.73750
[Evaluate] best accuracy performence has been updated: 0.73750 --> 0.74375
[Evaluate] best accuracy performence has been updated: 0.74375 --> 0.75000
[Train] epoch: 100/1000, loss: 0.6418899297714233
[Evaluate] best accuracy performence has been updated: 0.75000 --> 0.75625
[Train] epoch: 150/1000, loss: 0.6082024574279785
[Evaluate] best accuracy performence has been updated: 0.75625 --> 0.76250
[Evaluate] best accuracy performence has been updated: 0.76250 --> 0.76875
[Evaluate] best accuracy performence has been updated: 0.76875 --> 0.77500
[Train] epoch: 200/1000, loss: 0.5676448941230774
[Evaluate] best accuracy performence has been updated: 0.77500 --> 0.78125
[Evaluate] best accuracy performence has been updated: 0.78125 --> 0.78750
[Evaluate] best accuracy performence has been updated: 0.78750 --> 0.79375
[Train] epoch: 250/1000, loss: 0.5215781927108765
[Evaluate] best accuracy performence has been updated: 0.79375 --> 0.80000
[Evaluate] best accuracy performence has been updated: 0.80000 --> 0.80625
[Evaluate] best accuracy performence has been updated: 0.80625 --> 0.81250
[Train] epoch: 300/1000, loss: 0.47454261779785156
[Evaluate] best accuracy performence has been updated: 0.81250 --> 0.81875
[Evaluate] best accuracy performence has been updated: 0.81875 --> 0.82500
[Evaluate] best accuracy performence has been updated: 0.82500 --> 0.83125
[Evaluate] best accuracy performence has been updated: 0.83125 --> 0.83750
[Evaluate] best accuracy performence has been updated: 0.83750 --> 0.85000
[Evaluate] best accuracy performence has been updated: 0.85000 --> 0.85625
[Train] epoch: 350/1000, loss: 0.43142348527908325
[Evaluate] best accuracy performence has been updated: 0.85625 --> 0.86250
[Evaluate] best accuracy performence has been updated: 0.86250 --> 0.86875
[Train] epoch: 400/1000, loss: 0.39497217535972595
[Evaluate] best accuracy performence has been updated: 0.86875 --> 0.87500
[Evaluate] best accuracy performence has been updated: 0.87500 --> 0.88125
[Train] epoch: 450/1000, loss: 0.3656612038612366
[Evaluate] best accuracy performence has been updated: 0.88125 --> 0.88750
[Evaluate] best accuracy performence has been updated: 0.88750 --> 0.89375
[Train] epoch: 500/1000, loss: 0.3428545594215393
[Train] epoch: 550/1000, loss: 0.3256698548793793
[Train] epoch: 600/1000, loss: 0.3132207989692688
[Train] epoch: 650/1000, loss: 0.30456796288490295
[Evaluate] best accuracy performence has been updated: 0.89375 --> 0.90000
[Evaluate] best accuracy performence has been updated: 0.90000 --> 0.90625
[Train] epoch: 700/1000, loss: 0.2987373173236847
[Evaluate] best accuracy performence has been updated: 0.90625 --> 0.91250
[Train] epoch: 750/1000, loss: 0.294859379529953
[Train] epoch: 800/1000, loss: 0.292269766330719
[Evaluate] best accuracy performence has been updated: 0.91250 --> 0.91875
[Train] epoch: 850/1000, loss: 0.29051074385643005
[Train] epoch: 900/1000, loss: 0.2892831265926361
[Train] epoch: 950/1000, loss: 0.28839582204818726
[Test] score/loss: 0.8800/0.2849
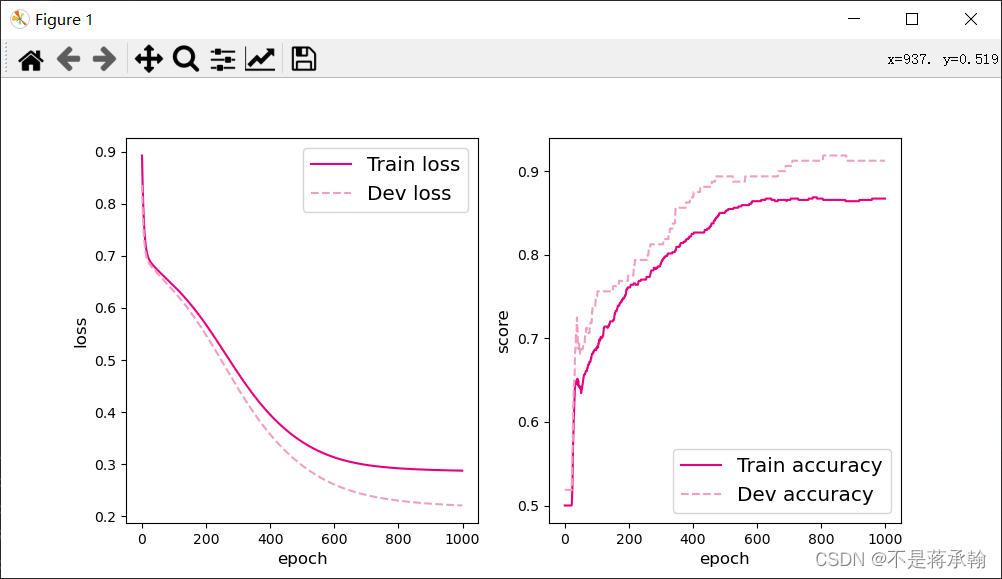
对比一个隐层的4.3.1,两个隐层的模型score更高,训练loss更低。
4.3.3 自定义隐藏层层数和每个隐藏层中的神经元个数,尝试找到最优超参数完成二分类。
构建4个隐层,每个隐层5个神经元的神经网络
class Model_MLP_L5(torch.nn.Module):
def __init__(self, input_size, output_size,mean_init=0.,std_init=1.,b_init=0.0):
super(Model_MLP_L5, self).__init__()
self.fc1 = torch.nn.Linear(input_size, 5)
normal_(tensor=self.fc1.weight, mean=mean_init, std=std_init)
constant_(tensor=self.fc1.bias, val=b_init)
self.fc2 = torch.nn.Linear(5, 5)
normal_(tensor=self.fc2.weight, mean=mean_init, std=std_init)
constant_(tensor=self.fc2.bias, val=b_init)
self.fc3 = torch.nn.Linear(5, 5)
normal_(tensor=self.fc3.weight, mean=mean_init, std=std_init)
constant_(tensor=self.fc3.bias, val=b_init)
self.fc4 = torch.nn.Linear(5, 5)
normal_(tensor=self.fc4.weight, mean=mean_init, std=std_init)
constant_(tensor=self.fc4.bias, val=b_init)
self.fc5 = torch.nn.Linear(5, output_size)
normal_(tensor=self.fc5.weight, mean=mean_init, std=std_init)
constant_(tensor=self.fc5.bias, val=b_init)
# 使用'torch.nn.functional.sigmoid'定义 Logistic 激活函数
self.act = F.sigmoid
# 前向计算
def forward(self, inputs):
outputs = self.fc1(inputs)
outputs = self.act(outputs)
outputs = self.fc2(outputs)
outputs = self.act(outputs)
outputs = self.fc3(outputs)
outputs = self.act(outputs)
outputs = self.fc4(outputs)
outputs = self.act(outputs)
outputs = self.fc5(outputs)
outputs = F.sigmoid(outputs)
return outputs [Evaluate] best accuracy performence has been updated: 0.00000 --> 0.54375
[Train] epoch: 0/1000, loss: 0.8435155153274536
[Evaluate] best accuracy performence has been updated: 0.54375 --> 0.55625
[Evaluate] best accuracy performence has been updated: 0.55625 --> 0.59375
[Evaluate] best accuracy performence has been updated: 0.59375 --> 0.63750
[Evaluate] best accuracy performence has been updated: 0.63750 --> 0.66875
[Evaluate] best accuracy performence has been updated: 0.66875 --> 0.68750
[Evaluate] best accuracy performence has been updated: 0.68750 --> 0.71250
[Evaluate] best accuracy performence has been updated: 0.71250 --> 0.72500
[Train] epoch: 50/1000, loss: 0.6921094655990601
[Train] epoch: 100/1000, loss: 0.6882262229919434
[Evaluate] best accuracy performence has been updated: 0.72500 --> 0.73125
[Evaluate] best accuracy performence has been updated: 0.73125 --> 0.73750
[Evaluate] best accuracy performence has been updated: 0.73750 --> 0.74375
[Train] epoch: 150/1000, loss: 0.6829259395599365
[Train] epoch: 200/1000, loss: 0.6751701831817627
[Evaluate] best accuracy performence has been updated: 0.74375 --> 0.75000
[Train] epoch: 250/1000, loss: 0.6634606122970581
[Evaluate] best accuracy performence has been updated: 0.75000 --> 0.75625
[Evaluate] best accuracy performence has been updated: 0.75625 --> 0.76250
[Evaluate] best accuracy performence has been updated: 0.76250 --> 0.76875
[Train] epoch: 300/1000, loss: 0.6455010175704956
[Evaluate] best accuracy performence has been updated: 0.76875 --> 0.77500
[Train] epoch: 350/1000, loss: 0.6183261871337891
[Train] epoch: 400/1000, loss: 0.5804553031921387
[Evaluate] best accuracy performence has been updated: 0.77500 --> 0.78125
[Evaluate] best accuracy performence has been updated: 0.78125 --> 0.78750
[Evaluate] best accuracy performence has been updated: 0.78750 --> 0.79375
[Train] epoch: 450/1000, loss: 0.5352076888084412
[Evaluate] best accuracy performence has been updated: 0.79375 --> 0.80000
[Evaluate] best accuracy performence has been updated: 0.80000 --> 0.80625
[Evaluate] best accuracy performence has been updated: 0.80625 --> 0.81250
[Train] epoch: 500/1000, loss: 0.4886578917503357
[Evaluate] best accuracy performence has been updated: 0.81250 --> 0.81875
[Evaluate] best accuracy performence has been updated: 0.81875 --> 0.82500
[Train] epoch: 550/1000, loss: 0.44431859254837036
[Evaluate] best accuracy performence has been updated: 0.82500 --> 0.83125
[Evaluate] best accuracy performence has been updated: 0.83125 --> 0.83750
[Evaluate] best accuracy performence has been updated: 0.83750 --> 0.84375
[Evaluate] best accuracy performence has been updated: 0.84375 --> 0.85000
[Train] epoch: 600/1000, loss: 0.40396183729171753
[Evaluate] best accuracy performence has been updated: 0.85000 --> 0.85625
[Evaluate] best accuracy performence has been updated: 0.85625 --> 0.86250
[Evaluate] best accuracy performence has been updated: 0.86250 --> 0.87500
[Train] epoch: 650/1000, loss: 0.3699793219566345
[Evaluate] best accuracy performence has been updated: 0.87500 --> 0.88125
[Train] epoch: 700/1000, loss: 0.3445335030555725
[Evaluate] best accuracy performence has been updated: 0.88125 --> 0.88750
[Evaluate] best accuracy performence has been updated: 0.88750 --> 0.89375
[Train] epoch: 750/1000, loss: 0.32763513922691345
[Evaluate] best accuracy performence has been updated: 0.89375 --> 0.90000
[Train] epoch: 800/1000, loss: 0.31706300377845764
[Train] epoch: 850/1000, loss: 0.3103279769420624
[Train] epoch: 900/1000, loss: 0.30574506521224976
[Train] epoch: 950/1000, loss: 0.3023308515548706
[Evaluate] best accuracy performence has been updated: 0.90000 --> 0.90625
[Test] score/loss: 0.8700/0.3286
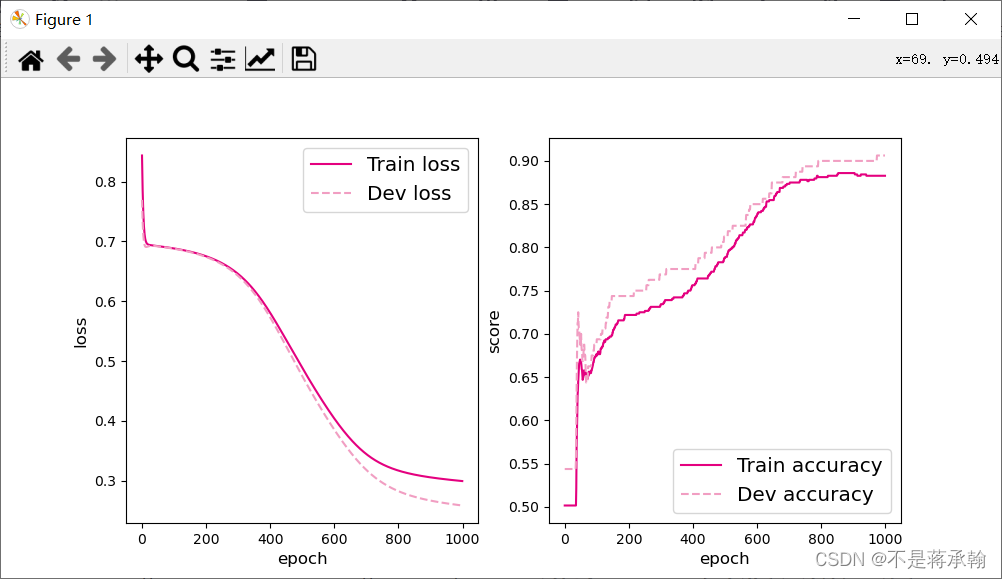
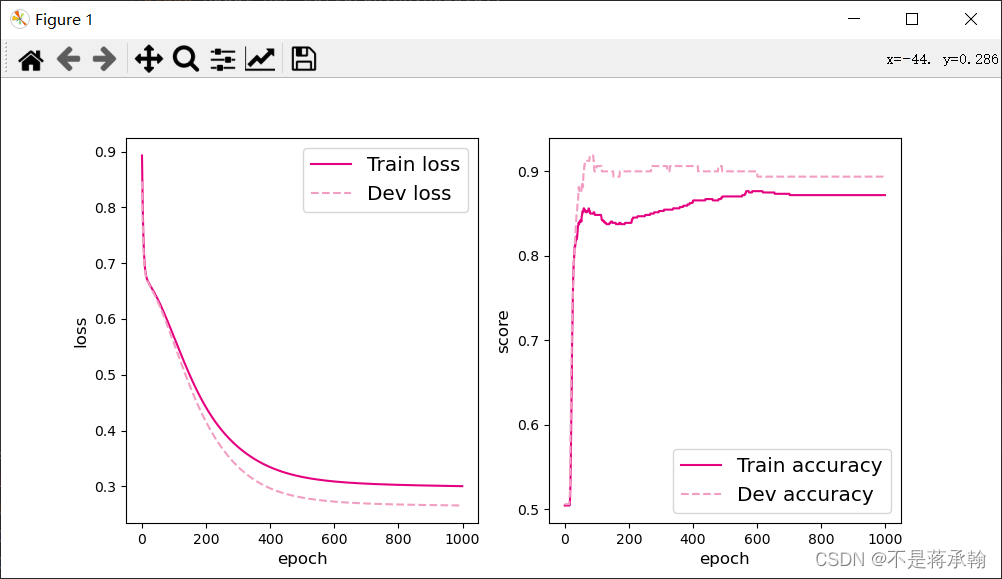
变成4个神经元:
[Test] score/loss: 0.8600/0.4399
变成3个神经元:
[Test] score/loss: 0.4950/0.7104
 神经元数量减少,模型训练效果在逐步下降。
神经元数量减少,模型训练效果在逐步下降。
把隐层数量调整到2层:
每层5个神经元:
[Test] score/loss: 0.9000/0.2586
每层4个神经元:
[Test] score/loss: 0.8500/0.5921
每层3个神经元:
[Test] score/loss: 0.8650/0.3518
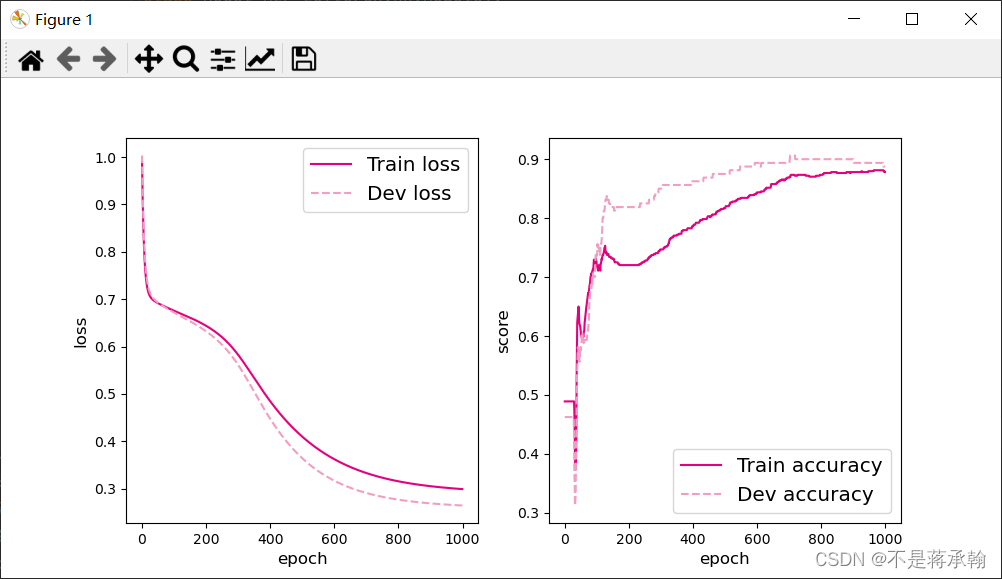
可以看出2个隐层的效果要远远好于4个隐层的效果。
一般认为,增加隐层数可以降低网络误差(也有文献认为不一定能有效降低),提高精度,但也使网络复杂化,从而增加了网络的训练时间和出现过拟合的倾向。一般来讲应设计神经网络应优先考虑4层网络(即有2个隐层)。一般地,靠增加隐层节点数来获得较低的误差,其训练效果要比增加隐层数更容易实现。对于没有隐层的神经网络模型,实际上就是一个线性或非线性(取决于输出层采用线性或非线性转换函数型式)回归模型。
在隐藏层中使用太少的神经元将导致欠拟合(underfitting)。相反,使用过多的神经元同样会导致一些问题。首先,隐藏层中的神经元过多可能会导致过拟合(overfitting)。当神经网络具有过多的节点(过多的信息处理能力)时,训练集中包含的有限信息量不足以训练隐藏层中的所有神经元,因此就会导致过拟合。即使训练数据包含的信息量足够,隐藏层中过多的神经元会增加训练时间,从而难以达到预期的效果。显然,选择一个合适的隐藏层神经元数量是至关重要的。
通常,对所有隐藏层使用相同数量的神经元就足够了。对于某些数据集,拥有较大的第一层并在其后跟随较小的层将导致更好的性能,因为第一层可以学习很多低阶的特征,这些较低层的特征可以馈入后续层中,提取出较高阶特征。
需要注意的是,与在每一层中添加更多的神经元相比,添加层层数将获得更大的性能提升。因此,不要在一个隐藏层中加入过多的神经元。
对于如何确定神经元数量,有很多经验之谈。
- 隐藏神经元的数量应在输入层的大小和输出层的大小之间。
- 隐藏神经元的数量应为输入层大小的2/3加上输出层大小的2/3。
- 隐藏神经元的数量应小于输入层大小的两倍。
【思考】
自定义梯度计算和自动梯度计算:
从计算性能、计算结果等多方面比较,谈谈自己的看法。
基于上次实验,手动计算梯度,得到的模型评价:
[Test] score/loss: 0.8050/0.4815
本次实验4.3.1的模型评价
[Test] score/loss: 0.8850/0.2583
可以看出自动梯度计算得到的模型效果更好,并且和之前的代码相比更加简洁,后向传播的计算部分变成了loss.backward()方法,让模型根据计算图自动计算每一个节点的梯度值,并根据variable中指定require_grad的赋值决定是否保留梯度,因为w1,w2均设置保留,因此这一步计算之后,下面就可以直接使用w1.grad.data调用保留的梯度数据,最后通过zero_方法置为零,防止对下一次迭代进行干扰。
4.4 优化问题
在本节中,我们通过实践来发现神经网络模型的优化问题,并思考如何改进。
4.4.1 参数初始化
实现一个神经网络前,需要先初始化模型参数。如果对每一层的权重和偏置都用0初始化,那么通过第一遍前向计算,所有隐藏层神经元的激活值都相同;在反向传播时,所有权重的更新也都相同,这样会导致隐藏层神经元没有差异性,出现对称权重现象。
接下来,将模型参数全都初始化为0,看实验结果。这里重新定义了一个类TwoLayerNet_Zeros,两个线性层的参数全都初始化为0。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.init import constant_, normal_
class Model_MLP_L2_V4(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Model_MLP_L2_V4, self).__init__()
# 使用'torch.nn.Linear'定义线性层。
# 其中第一个参数(in_features)为线性层输入维度;第二个参数(out_features)为线性层输出维度
# weight为权重参数属性,bias为偏置参数属性,这里使用'torch.nn.init.constant_'进行常量初始化
self.fc1 = nn.Linear(input_size, hidden_size)
constant_(tensor=self.fc1.weight,val=0.0)
constant_(tensor=self.fc1.bias,val=0.0)
self.fc2 = nn.Linear(hidden_size, output_size)
constant_(tensor=self.fc2.weight, val=0.0)
constant_(tensor=self.fc2.bias, val=0.0)
# 使用'torch.nn.functional.sigmoid'定义 Logistic 激活函数
self.act_fn = F.sigmoid
# 前向计算
def forward(self, inputs):
z1 = self.fc1(inputs)
a1 = self.act_fn(z1)
z2 = self.fc2(a1)
a2 = self.act_fn(z2)
return a2
def print_weights(runner):
print('The weights of the Layers:')
for _, param in enumerate(runner.model.named_parameters()):
print(param)
print('---------------------------------')
利用Runner类训练模型:
from metric import accuracy
from dataset import make_moons
n_samples = 1000
X, y = make_moons(n_samples=n_samples, shuffle=True, noise=0.15)
num_train = 640
num_dev = 160
num_test = 200
X_train, y_train = X[:num_train], y[:num_train]
X_dev, y_dev = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
X_test, y_test = X[num_train + num_dev:], y[num_train + num_dev:]
y_train = y_train.reshape([-1,1])
y_dev = y_dev.reshape([-1,1])
y_test = y_test.reshape([-1,1])
# 设置模型
input_size = 2
hidden_size = 5
output_size = 1
model = Model_MLP_L2_V4(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
# 设置损失函数
loss_fn = F.binary_cross_entropy
# 设置优化器
learning_rate = 0.2 #5e-2
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
# 设置评价指标
metric = accuracy
# 其他参数
epoch = 2000
saved_path = 'best_model.pdparams'
# 实例化RunnerV2类,并传入训练配置
runner = RunnerV2_2(model, optimizer, metric, loss_fn)
runner.train([X_train, y_train], [X_dev, y_dev], num_epochs=5, log_epochs=50, save_path="best_model.pdparams",custom_print_log=print_weights)
The weights of the Layers:
('fc1.weight', Parameter containing:
tensor([[-4.1772e-05, 3.4384e-05],
[-4.1772e-05, 3.4384e-05],
[-4.1772e-05, 3.4384e-05],
[-4.1772e-05, 3.4384e-05],
[-4.1772e-05, 3.4384e-05]], requires_grad=True))
---------------------------------
('fc1.bias', Parameter containing:
tensor([8.2898e-07, 8.2898e-07, 8.2898e-07, 8.2898e-07, 8.2898e-07],
requires_grad=True))
---------------------------------
('fc2.weight', Parameter containing:
tensor([[-0.0021, -0.0021, -0.0021, -0.0021, -0.0021]], requires_grad=True))
---------------------------------
('fc2.bias', Parameter containing:
tensor([-0.0042], requires_grad=True))
---------------------------------
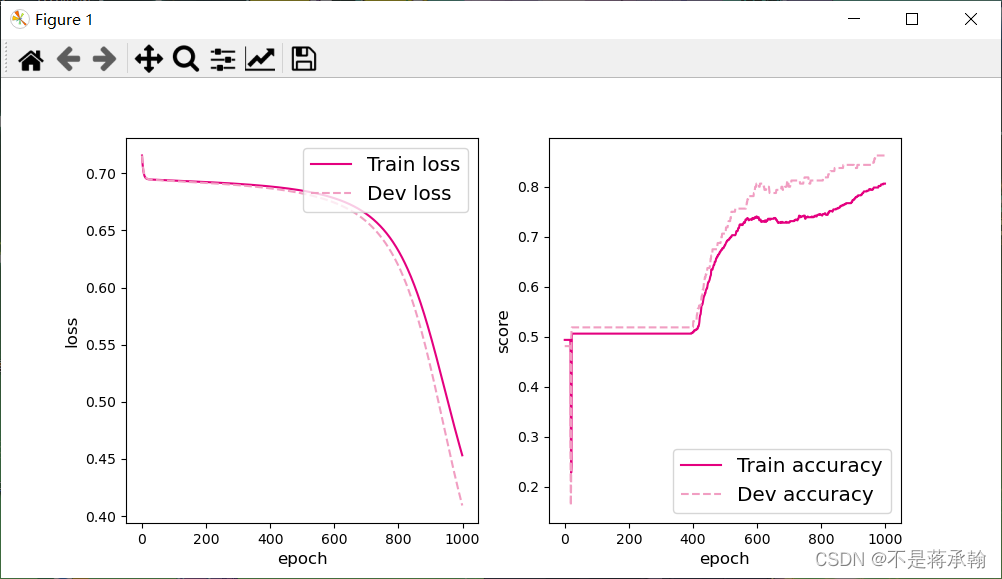
可视化训练和验证集上的主准确率和loss变化:
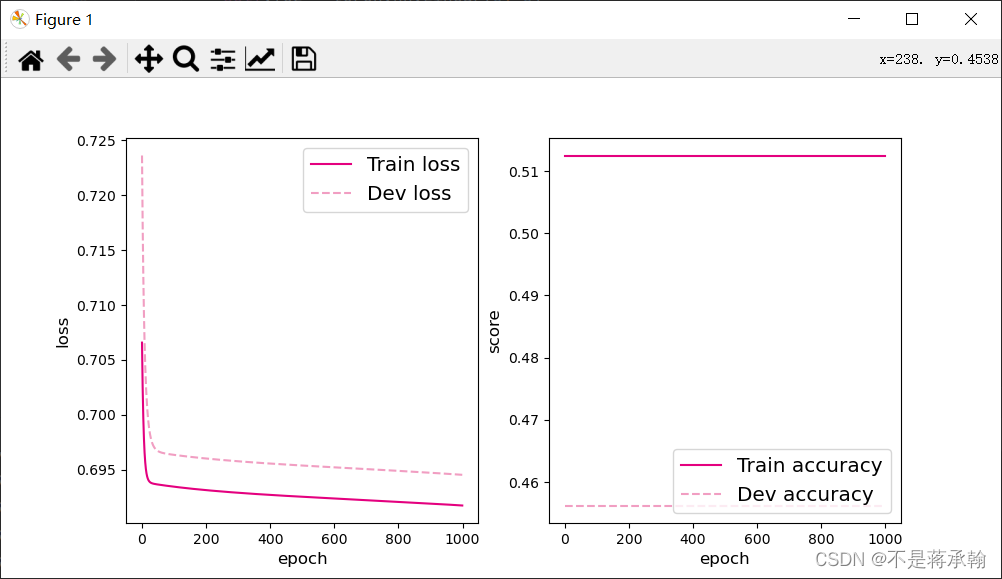
plot(runner, "fw-zero.pdf")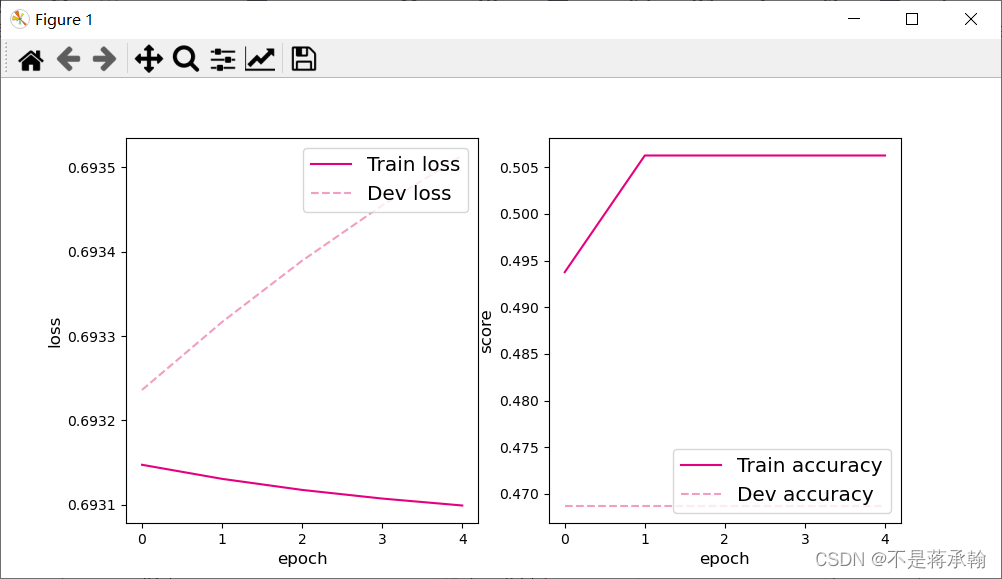
从输出结果看,二分类准确率为50%左右,说明模型没有学到任何内容。训练和验证loss几乎没有怎么下降。
为了避免对称权重现象,可以使用高斯分布或均匀分布初始化神经网络的参数。
4.4.2 梯度消失问题
在神经网络的构建过程中,随着网络层数的增加,理论上网络的拟合能力也应该是越来越好的。但是随着网络变深,参数学习更加困难,容易出现梯度消失问题。
由于Sigmoid型函数的饱和性,饱和区的导数更接近于0,误差经过每一层传递都会不断衰减。当网络层数很深时,梯度就会不停衰减,甚至消失,使得整个网络很难训练,这就是所谓的梯度消失问题。
在深度神经网络中,减轻梯度消失问题的方法有很多种,一种简单有效的方式就是使用导数比较大的激活函数,如:ReLU。
下面通过一个简单的实验观察前馈神经网络的梯度消失现象和改进方法。
4.4.2.1 模型构建
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.init import constant_, normal_
# 定义多层前馈神经网络
class Model_MLP_L5(torch.nn.Module):
def __init__(self, input_size, output_size, act='relu',mean_init=0.,std_init=0.01,b_init=1.0):
super(Model_MLP_L5, self).__init__()
self.fc1 = torch.nn.Linear(input_size, 3)
normal_(tensor=self.fc1.weight, mean=mean_init, std=std_init)
constant_(tensor=self.fc1.bias, val=b_init)
self.fc2 = torch.nn.Linear(3, 3)
normal_(tensor=self.fc2.weight, mean=mean_init, std=std_init)
constant_(tensor=self.fc2.bias, val=b_init)
self.fc3 = torch.nn.Linear(3, 3)
normal_(tensor=self.fc3.weight, mean=mean_init, std=std_init)
constant_(tensor=self.fc3.bias, val=b_init)
self.fc4 = torch.nn.Linear(3, 3)
normal_(tensor=self.fc4.weight, mean=mean_init, std=std_init)
constant_(tensor=self.fc4.bias, val=b_init)
self.fc5 = torch.nn.Linear(3, output_size)
normal_(tensor=self.fc5.weight, mean=mean_init, std=std_init)
constant_(tensor=self.fc5.bias, val=b_init)
# 定义网络使用的激活函数
if act == 'sigmoid':
self.act = F.sigmoid
elif act == 'relu':
self.act = F.relu
elif act == 'lrelu':
self.act = F.leaky_relu
else:
raise ValueError("Please enter sigmoid relu or lrelu!")
def forward(self, inputs):
outputs = self.fc1(inputs.to(torch.float32))
outputs = self.act(outputs)
outputs = self.fc2(outputs)
outputs = self.act(outputs)
outputs = self.fc3(outputs)
outputs = self.act(outputs)
outputs = self.fc4(outputs)
outputs = self.act(outputs)
outputs = self.fc5(outputs)
outputs = F.sigmoid(outputs)
return outputs4.4.2.2 使用Sigmoid型函数进行训练
使用Sigmoid型函数作为激活函数,为了便于观察梯度消失现象,只进行一轮网络优化。代码实现如下:
定义梯度打印函数:
def print_grads(runner):
print('The grad of the Layers:')
for name, parms in runner.model.named_parameters():
print('-->name:', name, ' -->grad_value:', parms.grad)torch.random.manual_seed(102)
# 学习率大小
lr = 0.01
# 定义网络,激活函数使用sigmoid
model = Model_MLP_L5(input_size=2, output_size=1, act='sigmoid')
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(),lr=lr)
# 定义损失函数,使用交叉熵损失函数
loss_fn = F.binary_cross_entropy
from metric import accuracy
# 定义评价指标
metric = accuracy
# 指定梯度打印函数
custom_print_log=print_grads实例化RunnerV2_2类,并传入训练配置。代码实现如下:
# 实例化Runner类
runner = RunnerV2_2(model, optimizer, metric, loss_fn)模型训练,打印网络每层梯度值的范数。代码实现如下:
# 启动训练
runner.train([X_train, y_train], [X_dev, y_dev],
num_epochs=1, log_epochs=None,
save_path="best_model.pdparams",
custom_print_log=custom_print_log)The grad of the Layers:
-->name: fc1.weight -->grad_value: tensor([[-4.3984e-12, 8.6800e-12],
[ 3.3543e-12, -6.6174e-12],
[ 5.9331e-12, -1.1691e-11]])
-->name: fc1.bias -->grad_value: tensor([ 8.6175e-12, -6.5863e-12, -1.1602e-11])
-->name: fc2.weight -->grad_value: tensor([[1.2173e-09, 1.2156e-09, 1.2185e-09],
[1.8435e-09, 1.8409e-09, 1.8453e-09],
[4.3710e-10, 4.3650e-10, 4.3754e-10]])
-->name: fc2.bias -->grad_value: tensor([1.6666e-09, 2.5239e-09, 5.9843e-10])
-->name: fc3.weight -->grad_value: tensor([[-1.4786e-06, -1.4787e-06, -1.4688e-06],
[-1.7528e-06, -1.7530e-06, -1.7412e-06],
[ 1.7010e-06, 1.7012e-06, 1.6898e-06]])
-->name: fc3.bias -->grad_value: tensor([-2.0250e-06, -2.4006e-06, 2.3296e-06])
-->name: fc4.weight -->grad_value: tensor([[-0.0001, -0.0001, -0.0001],
[ 0.0007, 0.0007, 0.0007],
[ 0.0004, 0.0004, 0.0004]])
-->name: fc4.bias -->grad_value: tensor([-0.0001, 0.0010, 0.0006])
-->name: fc5.weight -->grad_value: tensor([[0.1861, 0.1863, 0.1867]])
-->name: fc5.bias -->grad_value: tensor([0.2555])
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.55000
观察实验结果可以发现,梯度经过每一个神经层的传递都会不断衰减,最终传递到第一个神经层时,梯度几乎完全消失。
4.4.2.3 使用ReLU函数进行模型训练
torch.random.manual_seed(102)
# 学习率大小
lr = 0.01
# 定义网络,激活函数使用sigmoid
model = Model_MLP_L5(input_size=2, output_size=1, act='relu')
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(),lr=lr)
# 定义损失函数,使用交叉熵损失函数
loss_fn = F.binary_cross_entropy
from metric import accuracy
# 定义评价指标
metric = accuracy
# 指定梯度打印函数
custom_print_log=print_grads
# 实例化Runner类
runner = RunnerV2_2(model, optimizer, metric, loss_fn)
runner.train([X_train, y_train], [X_dev, y_dev],
num_epochs=1, log_epochs=None,
save_path="best_model.pdparams",
custom_print_log=custom_print_log)The grad of the Layers:
-->name: fc1.weight -->grad_value: tensor([[-2.9280e-09, 5.8138e-09],
[ 2.1988e-09, -4.3659e-09],
[ 3.9221e-09, -7.7876e-09]])
-->name: fc1.bias -->grad_value: tensor([ 5.7912e-09, -4.3489e-09, -7.7572e-09])
-->name: fc2.weight -->grad_value: tensor([[2.1852e-07, 2.1740e-07, 2.1933e-07],
[3.3131e-07, 3.2962e-07, 3.3254e-07],
[7.6353e-08, 7.5963e-08, 7.6636e-08]])
-->name: fc2.bias -->grad_value: tensor([2.1923e-07, 3.3240e-07, 7.6604e-08])
-->name: fc3.weight -->grad_value: tensor([[-5.2026e-05, -5.2053e-05, -5.0292e-05],
[-6.1891e-05, -6.1923e-05, -5.9828e-05],
[ 6.0128e-05, 6.0158e-05, 5.8123e-05]])
-->name: fc3.bias -->grad_value: tensor([-5.2354e-05, -6.2281e-05, 6.0506e-05])
-->name: fc4.weight -->grad_value: tensor([[-0.0007, -0.0007, -0.0007],
[ 0.0051, 0.0052, 0.0052],
[ 0.0029, 0.0029, 0.0029]])
-->name: fc4.bias -->grad_value: tensor([-0.0007, 0.0052, 0.0029])
-->name: fc5.weight -->grad_value: tensor([[0.2526, 0.2539, 0.2567]])
-->name: fc5.bias -->grad_value: tensor([0.2570])
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.55000
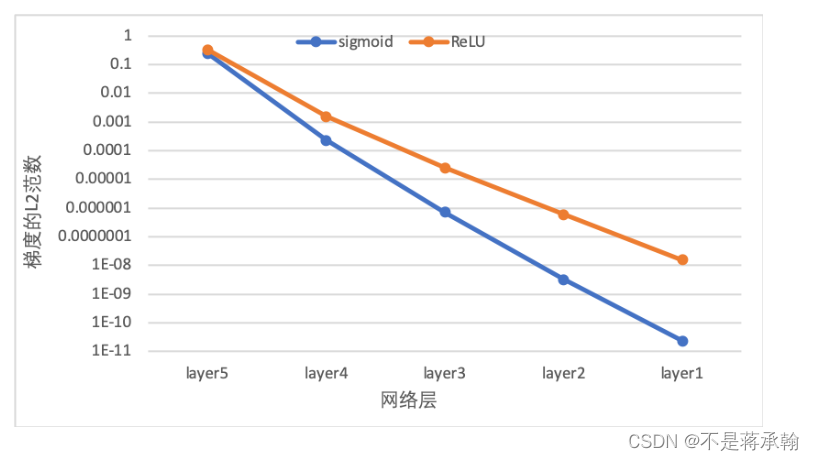
下图展示了使用不同激活函数时,网络每层梯度值的ℓ2ℓ2范数情况。从结果可以看到,5层的全连接前馈神经网络使用Sigmoid型函数作为激活函数时,梯度经过每一个神经层的传递都会不断衰减,最终传递到第一个神经层时,梯度几乎完全消失。改为ReLU激活函数后,梯度消失现象得到了缓解,每一层的参数都具有梯度值。
4.4.3 死亡 ReLU 问题
ReLU激活函数可以一定程度上改善梯度消失问题,但是ReLU函数在某些情况下容易出现死亡 ReLU问题,使得网络难以训练。这是由于当x<0x时,ReLU函数的输出恒为0。在训练过程中,如果参数在一次不恰当的更新后,某个ReLU神经元在所有训练数据上都不能被激活(即输出为0),那么这个神经元自身参数的梯度永远都会是0,在以后的训练过程中永远都不能被激活。而一种简单有效的优化方式就是将激活函数更换为Leaky ReLU、ELU等ReLU的变种。
4.4.3.1 使用ReLU进行模型训练
使用第4.4.2节中定义的多层全连接前馈网络进行实验,使用ReLU作为激活函数,观察死亡ReLU现象和优化方法。当神经层的偏置被初始化为一个相对于权重较大的负值时,可以想像,输入经过神经层的处理,最终的输出会为负值,从而导致死亡ReLU现象。
# 定义网络,并使用较大的负值来初始化偏置
model = Model_MLP_L5(input_size=2, output_size=1, act='relu', b_init=-8.0)实例化RunnerV2类,启动模型训练,打印网络每层梯度值的范数。代码实现如下:
# 实例化Runner类
runner = RunnerV2_2(model, optimizer, metric, loss_fn)
# 启动训练
runner.train([X_train, y_train], [X_dev, y_dev],
num_epochs=1, log_epochs=0,
save_path="best_model.pdparams",
custom_print_log=custom_print_log)
The grad of the Layers:
-->name: fc1.weight -->grad_value: tensor([[0., 0.],
[0., 0.],
[0., 0.]])
-->name: fc1.bias -->grad_value: tensor([0., 0., 0.])
-->name: fc2.weight -->grad_value: tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
-->name: fc2.bias -->grad_value: tensor([0., 0., 0.])
-->name: fc3.weight -->grad_value: tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
-->name: fc3.bias -->grad_value: tensor([0., 0., 0.])
-->name: fc4.weight -->grad_value: tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
-->name: fc4.bias -->grad_value: tensor([0., 0., 0.])
-->name: fc5.weight -->grad_value: tensor([[0., 0., 0.]])
-->name: fc5.bias -->grad_value: tensor([-0.4794])
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.45000
从输出结果可以发现,使用 ReLU 作为激活函数,当满足条件时,会发生死亡ReLU问题,网络训练过程中 ReLU 神经元的梯度始终为0,参数无法更新。
针对死亡ReLU问题,一种简单有效的优化方式就是将激活函数更换为Leaky ReLU、ELU等ReLU 的变种。接下来,观察将激活函数更换为 Leaky ReLU时的梯度情况。
4.4.3.2 使用Leaky ReLU进行模型训练
# 重新定义网络,使用Leaky ReLU激活函数
model = Model_MLP_L5(input_size=2, output_size=1, act='lrelu', b_init=-8.0)
# 实例化Runner类
runner = RunnerV2_2(model, optimizer, metric, loss_fn)
# 启动训练
runner.train([X_train, y_train], [X_dev, y_dev],
num_epochs=1, log_epochps=None,
save_path="best_model.pdparams",
custom_print_log=custom_print_log)
The grad of the Layers:
-->name: fc1.weight -->grad_value: tensor([[-1.0685e-16, 1.4224e-17],
[ 8.0243e-17, -1.0681e-17],
[ 1.4313e-16, -1.9052e-17]])
-->name: fc1.bias -->grad_value: tensor([-1.0803e-16, 8.1126e-17, 1.4471e-16])
-->name: fc2.weight -->grad_value: tensor([[3.2707e-14, 3.2668e-14, 3.2706e-14],
[4.9589e-14, 4.9531e-14, 4.9589e-14],
[1.1428e-14, 1.1415e-14, 1.1428e-14]])
-->name: fc2.bias -->grad_value: tensor([-4.0897e-13, -6.2007e-13, -1.4290e-13])
-->name: fc3.weight -->grad_value: tensor([[-7.8125e-10, -7.8125e-10, -7.8099e-10],
[-9.2938e-10, -9.2939e-10, -9.2907e-10],
[ 9.0290e-10, 9.0291e-10, 9.0260e-10]])
-->name: fc3.bias -->grad_value: tensor([ 9.7662e-09, 1.1618e-08, -1.1287e-08])
-->name: fc4.weight -->grad_value: tensor([[-1.0404e-06, -1.0405e-06, -1.0405e-06],
[ 7.7293e-06, 7.7304e-06, 7.7305e-06],
[ 4.3782e-06, 4.3788e-06, 4.3789e-06]])
-->name: fc4.bias -->grad_value: tensor([ 1.3006e-05, -9.6626e-05, -5.4733e-05])
-->name: fc5.weight -->grad_value: tensor([[0.0383, 0.0383, 0.0383]])
-->name: fc5.bias -->grad_value: tensor([-0.4794])
[Evaluate] best accuracy performence has been updated: 0.00000 --> 0.45000
从输出结果可以看到,将激活函数更换为Leaky ReLU后,死亡ReLU问题得到了改善,梯度恢复正常,参数也可以正常更新。但是由于 Leaky ReLU 中,x<0 时的斜率默认只有0.01,所以反向传播时,随着网络层数的加深,梯度值越来越小。如果想要改善这一现象,将 Leaky ReLU 中,x<0 时的斜率调大即可。
总结
在前馈神经网络的学习中,我们通过亲力亲为的计算,走过了正向传播,也体会了反向传播。但是通过pytorch的自动计算梯度就可以轻易完成原本复杂的反向传播,其实已经有很多机器学习的框架可以很简单的实现神经网络。但是我们的目标是:在看懂算法之后,我们是否能照着算法的整个过程,去实现一遍,这可以加深对算法原理的理解,以及对算法实现思路的的理解。
以下是我对本次实验的几个问题及思考
- 神经网络的结构,即几层网络,输入输出怎么设计才最有效?
设计几层网络比较好的问题仍然是个黑匣子,没有理论支撑应该怎么设计网络,现在仍是经验使然
- 数学理论证明,三层的神经网络就能够以任意精度逼近任何非线性连续函数。那么为什么还需要有深度网络?
深层网络一般用于深度学习范畴,一般的分类、回归问题还是传统机器学习算法用的比较多,而深度学习的天空在cv、nlp等需要大量数据的领域
- 在不同应用场合下,激活函数怎么选择?
没深入研究,感觉还是靠经验多一些
- 学习率怎么怎么选择?
学习率的原则肯定是开始大收敛快,后面小逼近全局最优,需要设置动态的学习率。而且最开始的学习率设置大了训练会震荡,设置小了收敛会很慢,这是实际项目中需要调的超参数
- 训练次数设定多少训练出的模型效果更好?
关于训练次数的问题,一般设置检查点然后让训练到模型过拟合,选择检查点中保存的最优模型权重就好了。次数要能够使得模型过拟合,因为不过拟合就没有达到模型的极限

















 1996
1996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









