







 文章探讨了如何通过微调参数而非改变基础模型来优化视频类模型,并介绍了提示(prompt)的概念,包括硬提示(hardprompt)和软提示(softprompt)。研究还提到了mixgen模块在多任务中的应用。文章倡导设计模型无关的模块以适应大模型的发展,并提出了编写数据集、因果学习和前馈网络(FFNet)等新方向。此外,文章讨论了少样本学习、零样本学习以及fine-tuning在新话题如chainofthoughtprompting中的应用。
文章探讨了如何通过微调参数而非改变基础模型来优化视频类模型,并介绍了提示(prompt)的概念,包括硬提示(hardprompt)和软提示(softprompt)。研究还提到了mixgen模块在多任务中的应用。文章倡导设计模型无关的模块以适应大模型的发展,并提出了编写数据集、因果学习和前馈网络(FFNet)等新方向。此外,文章讨论了少样本学习、零样本学习以及fine-tuning在新话题如chainofthoughtprompting中的应用。
总结zhu老师观点
Efficient
1.这篇论文是真的好orz,总结了目前的视频类模型
修改周边的一些参数,来训练,不改基础的模型(太大了。。。没资源没卡)
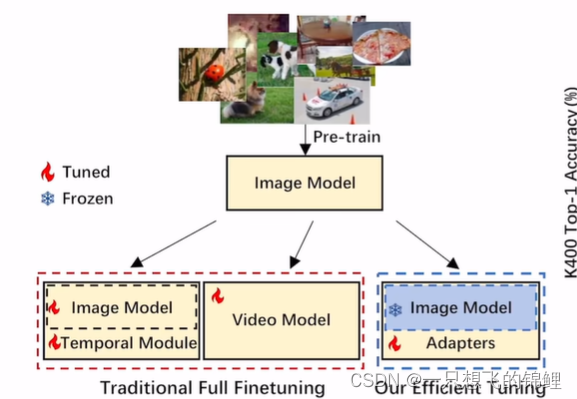
引申:
- prompt 是你想模型干什么你就给提示(简单来说)
- 什么是tuning呢? 就是调可能更好 (设计不同效果不一样)
hard prompt:固定的
COOP:soft prompt 自己学 - PEFT
5. mixgen——这篇论文 一个模块 几个任务有涨点就行。
怎么利用好大的模型,这样即使大模型不断发展也关我们没什么事情,因为设计的module 是模型无关的。但是任务要新,没什么人做
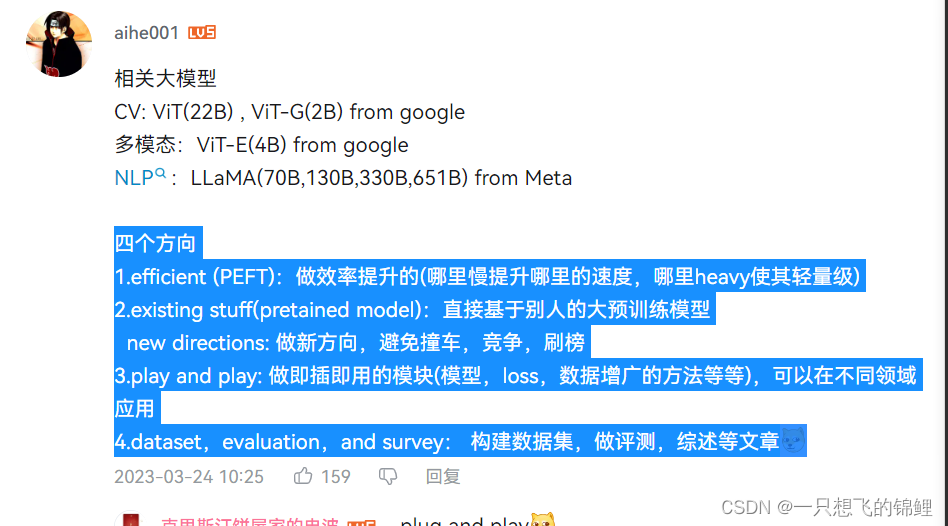
参考了b站用户CNcreator的评论:我太懒了直接copy了= =
1.Efficient PEFT 参数的有效使用
- New directions
3.plug and play 做一些通用的模块,能够广泛引用到一些方向中去 目标函数 loss data argumentation 可以应用到各种领域 选很多的baseline 公平对比说明有效性
4.写数据集,分析为主的文章或者综述论文
Fewshot,zeroshot,或者最多就是Fine Tuning的实验,再加上比较新的topic.比如
Causality Learning 因果学习
Feedforward network FFNet
Language In-context learning
Chain of thought prompting(cot)


















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









