







TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation

- 作者单位:JHU、UESTC、Stanford等
- 代码:https://github.com/Beckschen/TransUNet
- 论文:https://arxiv.org/pdf/2102.04306.pdf
Abstract
- U-Net缺陷:由于卷积运算的固有局部性,建模远程依赖存在局限性
- transformer:已经作为具有先天全局自我注意力机制的替代架构出现,但由于低层细节不足,可能导致定位能力有限
- 我们提出的TransUNet,同时具有transformers和U-Net的优点,作为医学图像分割一个强大的替代
- 一方面,transformers从卷积神经网络(CNN)特征映射中编码标记化的图像块,作为提取全局上下文的输入序列。另一方面,解码器对编码特征进行采样,然后将其与高分辨率的CNN特征相结合使定位更精确
- 实验:多器官分割和心脏分割
Introduction
- 与先前基于cnn的方法不同,transformer不仅在建模全局上下文方面非常强大,而且在大规模的预训练下,对下游任务表现出优越的可迁移性
- 我们发现,单纯的使用transformer(即使用transformer对标记化的图像块进行编码,然后直接将隐藏的特征表示上采样到完整分辨率的密集输出)不能产生令人满意的结果——缺乏详细定位信息(将输入视为一维序列,并专注于建模所有阶段的全局上下文)
- 我们提出了首个医学图像分割框架TransUNet,该框架从序列到序列预测的角度建立了自我注意力机制
- 为了补偿transformer带来的特征分辨率损失,TransUNet采用了CNN-Transformer的混合架构,以利用来自CNN特征的高分辨率信息和Transformers的全局上下文信息
Related Works
- Combining CNNs with self-attention mechanisms:non-local等
- Transformers:建立在ViT之上
Method
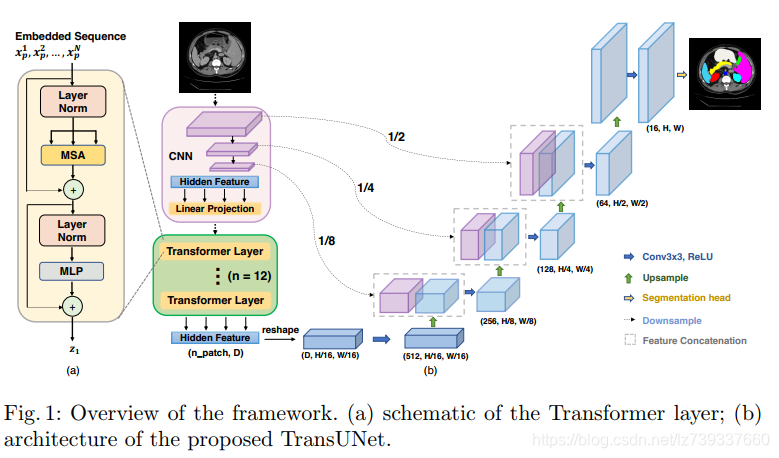
- Transformer as Encoder
(1)Image Sequentialization(图像序列化):reshape成2D patch N= H * W / (P * P)
(2)Patch Embedding:
编码patch空间信息,学习特定的位置嵌入:
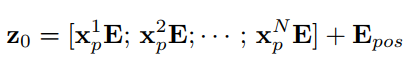
- TransUNet
为了弥补这种信息损失,TransUNet采用了CNN-Transformer混合结构作为编码器,并采用级联上采样器实现精确定位(直接上采用导致低层细节信息丢失)
(1)CNN-Transformer Hybrid as Encoder:
优势:(1)它允许我们在解码路径中利用中间高分辨率的CNN特征映射(2)CNN-Transformer编码器优于单纯Transformer作为编码器
(2)Cascaded Upsampler:一个级联的上采样器
Experiments and Discussion
- Dataset and Evaluation
(1)Synapse multi-organ segmentation dataset(30腹部CT扫描、3779张 / 8个器官)
(2)Automated cardiac diagnosis challenge(左心室、右心室、心肌) - Implementation Details
(1)数据增强:random rotation and flipping
(2)输入:224 x 224
(3)patch size:16 - Comparison with State-of-the-arts
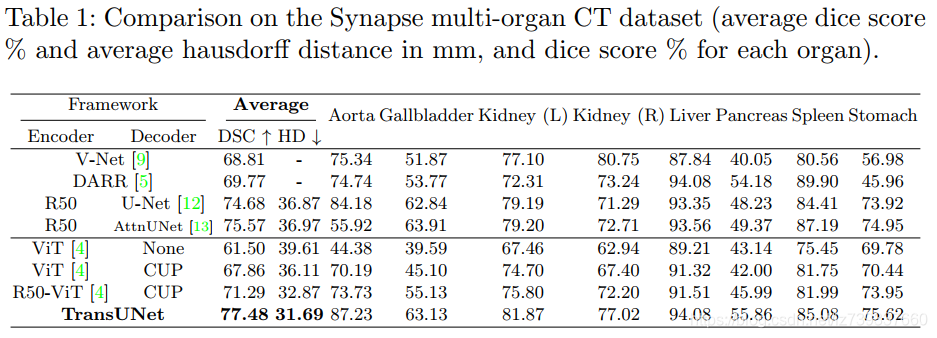 这是由于Transformers可以很好地捕捉高级语义,这有利于分类任务,但缺乏低层线索去分割细粒度的医学图像的良好形状
这是由于Transformers可以很好地捕捉高级语义,这有利于分类任务,但缺乏低层线索去分割细粒度的医学图像的良好形状 - Analytical Study
(1)The Number of Skip-connections:
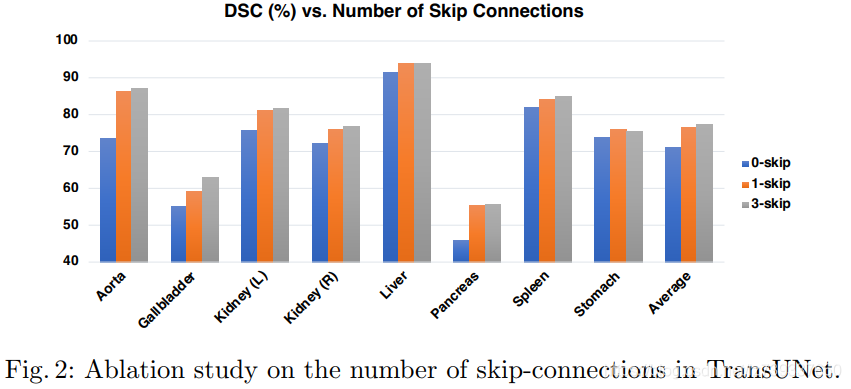 (2)On the Influence of Input Resolution
(2)On the Influence of Input Resolution (3)On the Influence of Patch Size/Sequence Length
(3)On the Influence of Patch Size/Sequence Length
(4)Model Scaling
the hidden size D / number of layers / MLP size / number of heads
- Visualizations
(1)定性比较: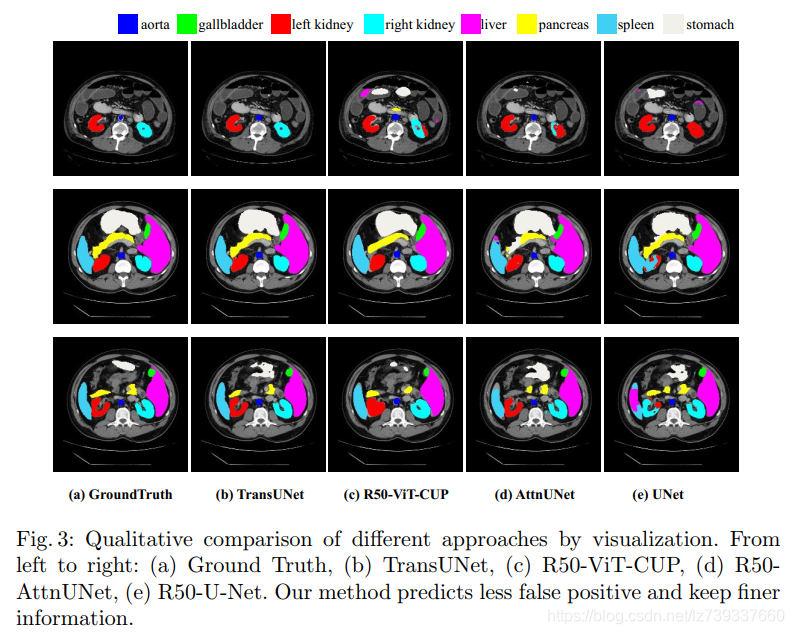
> UNet和AttnUNet过分割 / 欠分割,这表明基于Transformer的模型,例如我们的TransUNet或R50-ViT-CUP在编码全局上下文和区分语义方面具有更强的能力
> TransUNet预测的假阳性更少,这表明TransUNet在抑制噪声预测方面比其他方法更有优势
> 在基于Transformer的模型中进行比较,可以观察到R50-ViT-CUP在边界和形状方面的预测比TransUNet的预测更粗糙
- Generalization to Other Datasets:其他数据验证,得出类似结果
Conclusion
- 在这篇论文中,我们提出了第一个研究Transformers在一般医学图像分割中的应用
- 为了充分发挥Transformers的能力,提出了TransUNet,它不仅将图像特征作为序列进行强全局上下文编码,而且通过u形混合结构设计,很好地利用了低层CNN特征

















 3037
3037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









