




 本文介绍了一种名为TransUNet的方法,它通过结合卷积神经网络(CNN)和自注意力机制(Transformer)来改善图像分割。作者发现直接的Transformer编码不足以捕捉细节,于是提出将CNN用于低级特征提取,再利用Transformer捕获全局上下文。实验表明,混合结构和级联上采样器有效弥补了细节丢失,且在高分辨率图像上性能显著提升。
本文介绍了一种名为TransUNet的方法,它通过结合卷积神经网络(CNN)和自注意力机制(Transformer)来改善图像分割。作者发现直接的Transformer编码不足以捕捉细节,于是提出将CNN用于低级特征提取,再利用Transformer捕获全局上下文。实验表明,混合结构和级联上采样器有效弥补了细节丢失,且在高分辨率图像上性能显著提升。
1 Method
1.作者发现直接将输入图像直接使用Transformer进行编码,并且将得到的特征图直接上采样到全分辨率的密集输出,无法产生令人满意的结果。
2. 原因为:Transformers将输入视为1D序列,并且只关注在所有阶段建模的全局上下文信息,因此会缺乏详细的局部信息。并且,这些信息无法通过直接上采样到完整分辨率来恢复,因此会导致粗略的分割结果。
3. TransUNet采用混合CNN-Transformer结构,充分利用了来自CNN特征的详细高分辨率空间信息以及来自Transformer的全局上下文信息。
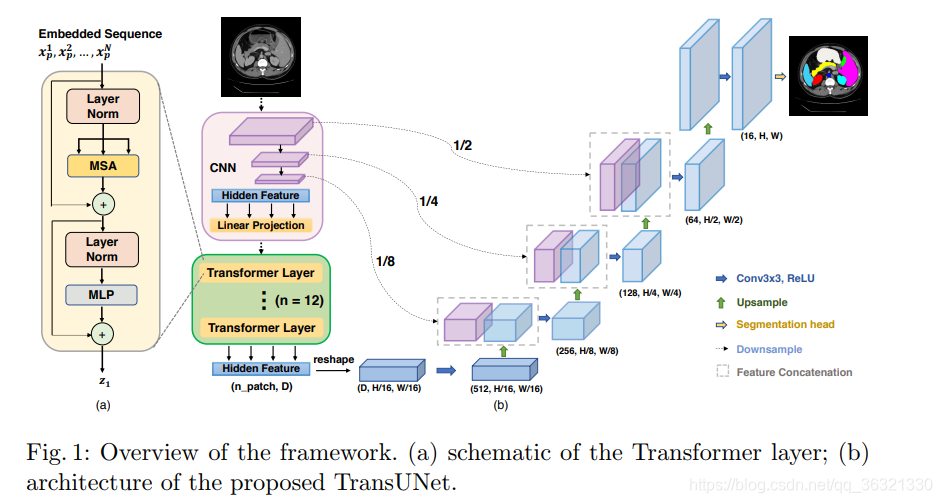
输入图像 X ∈ R H × W × C X \in \mathbb{R}^{H \times W \times C} X∈RH×W×C,我们的目标为预测尺寸为 H × W H \times W H×W 的像素级标签图。
首先将 X X Xreshape成一些序列经过flattened 2D patched { x p i ∈ R P 2 ⋅ C ∣ i = 1 , … , N } \{ x^{i}_p \in \mathbb{R}^{P^{2}\cdot C } | i=1,\ldots,N \} { xpi∈RP2⋅C∣i=1,…,N},其中patch的大小为 P × P P \times P P×P, N = H W P 2 N = \frac{HW}{P^{2}} N=P2HW
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









