







 超级会员免费看
超级会员免费看
 这篇博客介绍了在数据处理中如何使用Pandas DataFrame将空值标记为0,非空值标记为1的方法。通过先填充空值,再替换或者直接利用字符串转化和条件判断来实现这一目标。无论是处理时间类型还是非时间类型的数据,都能找到简单有效的解决方案。
这篇博客介绍了在数据处理中如何使用Pandas DataFrame将空值标记为0,非空值标记为1的方法。通过先填充空值,再替换或者直接利用字符串转化和条件判断来实现这一目标。无论是处理时间类型还是非时间类型的数据,都能找到简单有效的解决方案。
DataFrame中标记空值为0,非空值为1
手动反爬虫,禁止转载: 原博地址 https://blog.youkuaiyun.com/lys_828/article/details/117820052
知识梳理不易,请尊重劳动成果,文章仅发布在优快云网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
测试数据如下,可以自己指定,由于在数据处理过程中遇到了需要进行非空的处理

处理的思路是较为简单的,可以先填充然后在针对非填充的数值再进行替换,需要使用到fillna()的方法,然后就是apply()函数的使用了
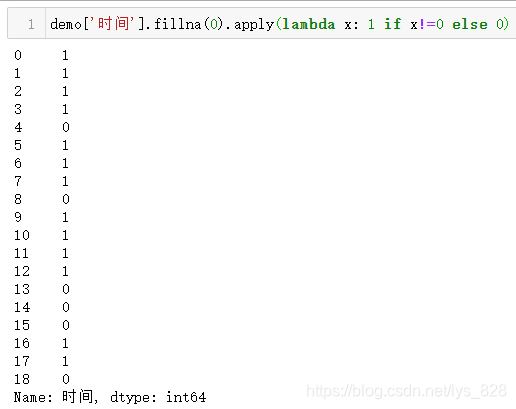
同理对于非时间的转化也是一致
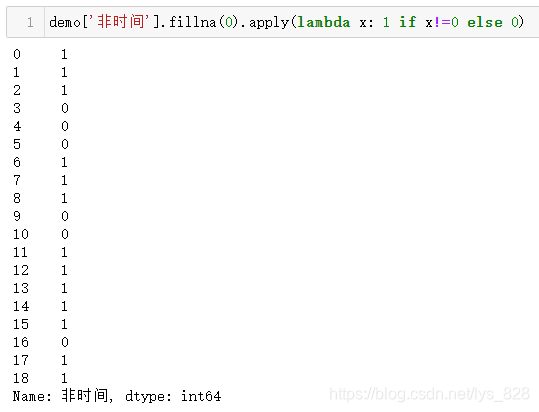
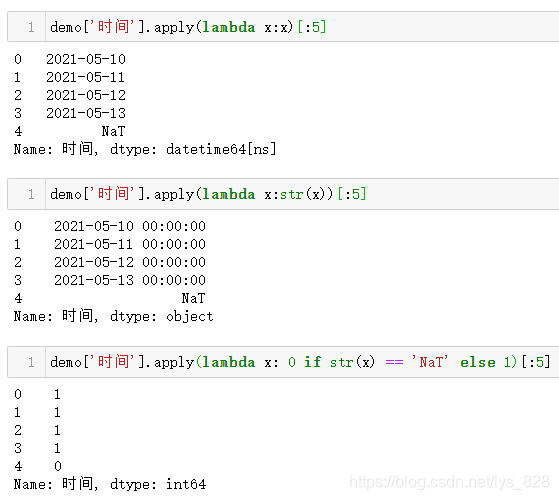
还有一种方式,我自己较为常用的,就是如论如何都可以对单元进行字符串转化,最后空值也会有字符串的表现形式,然后判断如果不等于这个形式就标记为1,是这个形式就标记为0,比如时间

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1965
1965




 到【灌水乐园】发言
到【灌水乐园】发言









