









 本文探讨了在给定二叉树和目标和的情况下,如何判断是否存在从根节点到叶子节点的路径,使得路径上所有节点值之和等于目标和。通过深度优先搜索(DFS)策略,递归地检查每条可能的路径,直至找到符合条件的路径或遍历完整棵树。
本文探讨了在给定二叉树和目标和的情况下,如何判断是否存在从根节点到叶子节点的路径,使得路径上所有节点值之和等于目标和。通过深度优先搜索(DFS)策略,递归地检查每条可能的路径,直至找到符合条件的路径或遍历完整棵树。
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
示例:
给定如下二叉树,以及目标和 sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ \
7 2 1
返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
一、思路
遍历整颗二叉树,找出所有路径之和,与目标进行对比
C++代码:
class Solution {
public:
bool hasPathSum(TreeNode* root, int sum) {
if (!root)
return false;
bool ans = false;
finPathSum(root, sum, 0, ans);
return ans;
}
void finPathSum(TreeNode* root, int& target, int pre_sum, bool& ans) {
int sum = root->val + pre_sum;
if (root->left == NULL && root->right == NULL) {
if (target == sum)
ans = true;
if (ans)
return;
}
if (root->left)
finPathSum(root->left, target, sum, ans);
if (root->right)
finPathSum(root->right, target, sum, ans);
return;
}
};
执行效率:
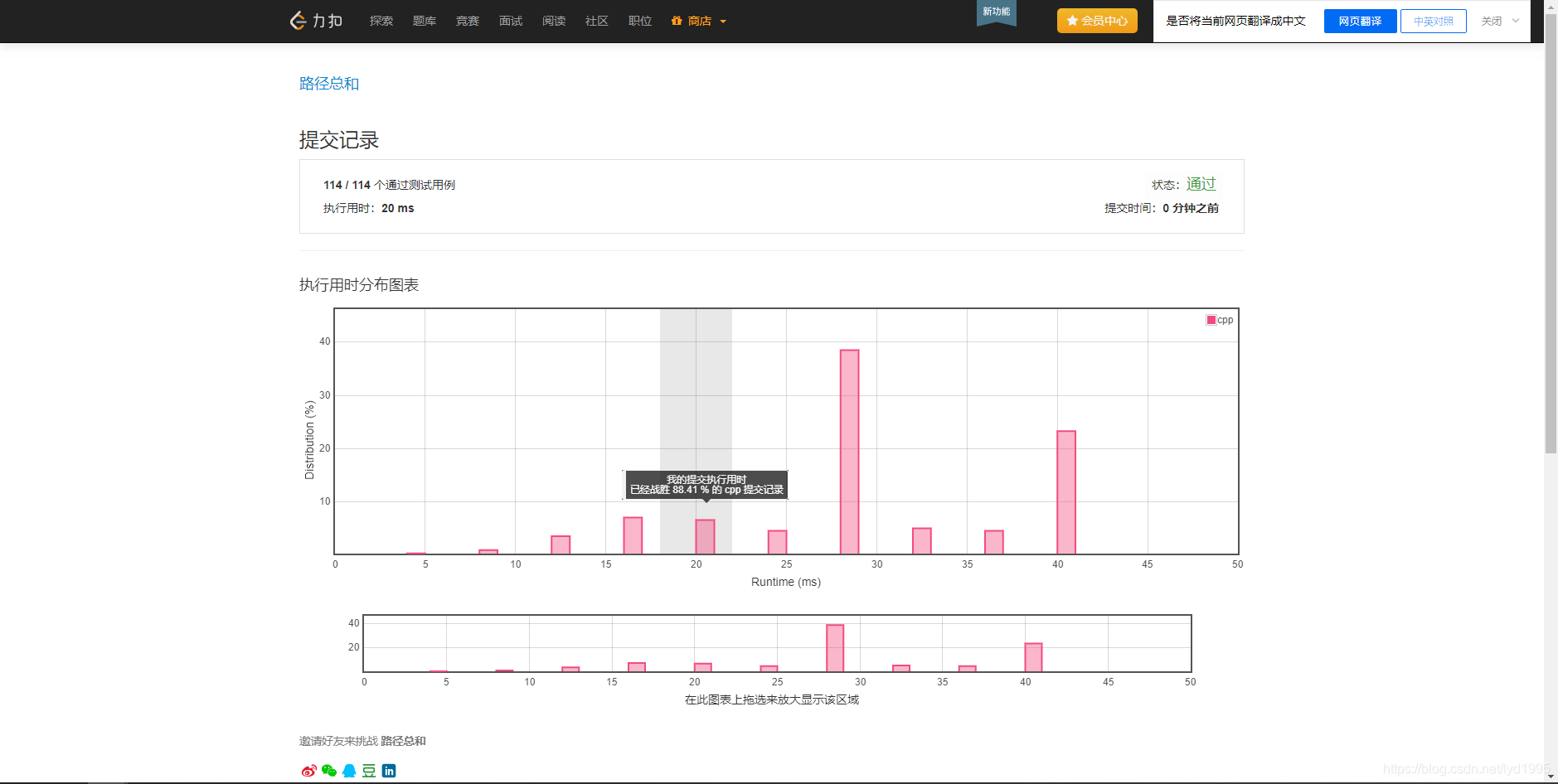

















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









