




 本文详细介绍了如何使用Faster R-CNN框架进行自定义数据集的训练,包括数据集准备、配置文件修改及常见错误解决方法,帮助读者顺利实现目标检测任务。
本文详细介绍了如何使用Faster R-CNN框架进行自定义数据集的训练,包括数据集准备、配置文件修改及常见错误解决方法,帮助读者顺利实现目标检测任务。
为了确保不出问题,可以在pascal voc数据集上测试一遍。具体操作参考:https://mp.youkuaiyun.com/console/editor/html/105561069
首先,你需要制作好自己的数据集,数据集格式与pascal voc2007相同。数据集制作请参考:
https://blog.youkuaiyun.com/ly_twt/article/details/105772354
一、
在进行过pascal voc数据集的训练测试成功后。将以下文件夹删除:
(1)output文件夹
(2)py-faster-rcnn/data/cache中的文件
(3)py-faster-rcnn/data/VOCdevkit2007软链接用你数据集中的Annotations,ImageSets,JPEGImages替换py-faster-rcnn/data/VOCdevkit/VOC2007中对应文件夹。
二、
需要修改一些文件:
(1)
py-faster-rcnn-master/lib/datasets/pascal_voc.py第一处:在第30行,除了_background_不改,其他的改成你自己数据集的类别。

(可选)第二处:在212行。如果你的标签中含有大写字母,可能会出现KeyError的错误,就需要将该行中的lower()去掉。另外,建议标签用小写字母。

(2)
py-faster-rcnn-master/models/pascal_voc/VGG_CNN_M_1024/faster_rcnn_end2end/train.prototxt第一处:在第11行,将21改成你自己数据集‘类别数+1’,例如你数据集中有17种类别,那这里就改成18.

第二处:在第341行,将21改成你自己数据集‘类别数+1’。

第三处:在431行,将21改成你自己数据集‘类别数+1’。

第四处:在454行,将84改成'(类别数+1)*4’,如果你的类别数是17,那么就改成72
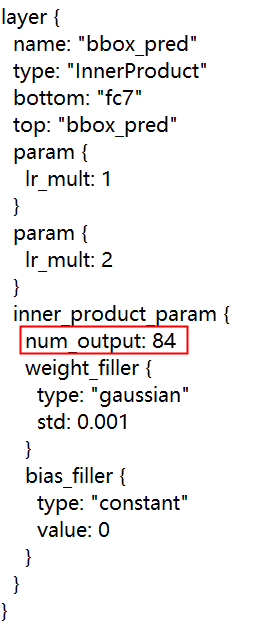
(3)
py-faster-rcnn-master/models/pascal_voc/VGG_CNN_M_1024/faster_rcnn_end2end/test.prototxt第一处:在409行,将21改成你自己数据集‘类别数+1’
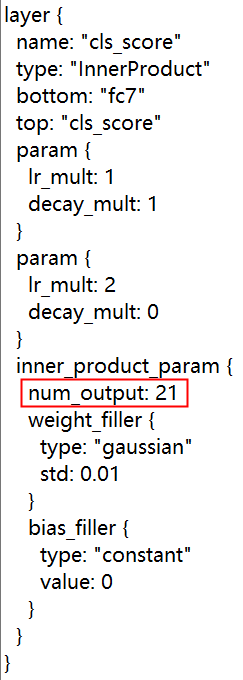
第二处:在434行,将84改成'(类别数+1)*4’

(4)为避免标定区域溢出错误,需要进行以下修改:
一般错误如下:
File "/py-faster-rcnn/tools/../lib/datasets/imdb.py", line 108, in append_flipped_images
assert (boxes[:, 2] >= boxes[:, 0]).all()
AssertionError
第一处:
py-faster-rcnn/lib/datasets/imdb.py在第102行这个函数中进行修改:在110和111行中间插入以下代码
for b in range(len(boxes)):
if boxes[b][2]< boxes[b][0]:
boxes[b][0] = 0
第二处:
py-faster-rcnn-master/lib/datasets/pascal_voc.py将第208,209,210,211行中的-1去掉。

至此,你可以开始训练测试了。训练测试步骤与pascal voc相同,参考:https://mp.youkuaiyun.com/console/editor/html/105561069
遇到的问题:
1、
问题:
ValueError:operands could not be broadcast together with shapes (72, 1024)解决:
在上面修改文件的时候没改对。
2、
问题:
TypeError: slice indices must be integers or None or have an __index__ method解决:
第一处:
lib/rpn/proposal_target_layer.py在第123行的for循环中,如下:(这里的ind,start,end都是 numpy.int 类型,这种类型的数据不能作为索引,所以必须对其进行强制类型转换)

改成:

第二处:
py-faster-rcnn/lib/roi_data_layer/minibatch.py在172行的for循环中,

改为:

3、
问题:
出现u'\ufeff或者xml.etree.ElementTree.ParseError: not well-formed (invalid token): line 99, column 8原因:xml文件中存在乱码
这里就要提醒大家,在标注过程中一定要严格:
①标注文件(图片,xml,标注工具等)存放路径一定不要出现中文。
②标签一定不要出现中文。最好用小写母。‘-’最好使用‘_’代替。
③xml文件用utf-8编码。
4、
问题:
测试出现:IndexError: too many indices for array解决:
lib/datasets/voc_eval.py在147和148行中间插入以下代码:
if len(BB) != 0:
BB = BB[sorted_ind, :]



















 1463
1463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









